![]()

Introduction to Data Wrangling
Data Wrangling is a crucial process in data science that involves transforming and cleaning raw data into a usable format. It involves converting data from one form to another, removing missing or duplicated values, and dealing with outliers. Data wrangling also ensures that data formatting is consistent and accurate, making it reliable for analysis and modeling. This process is vital as it helps researchers to obtain accurate results and make informed decisions based on the data. Data wrangling is significant in environmental data as it helps to build maps and models that can provide valuable insights into environmental conditions. Therefore, it is essential to carry out data wrangling consistently and accurately to ensure the data is reliable and can be used for decision-making.
This section provides an overview of data wrangling, its importance, and the steps involved in the process. It also highlights some of the key R packages that can be used for data wrangling tasks.
Why is Data Wrangling Important?
Here are some key reasons why data wrangling is essential:
Data Quality Improvement: Raw data often contains errors, missing values, inconsistencies, and outliers. Data wrangling identifies and rectifies these issues to ensure data accuracy and reliability.Compatibility: Data from various sources may have different formats and structures, making it challenging to analyze. Data wrangling standardizes data from different sources, ensuring the compatibility and consistency necessary for accurate analysis.Handling Missing Values: Data wrangling provides methods to handle missing data, such as imputation or removal, to prevent it from affecting the analysis.Data Transformation: Transforming raw data into the right format for analysis can be done through data wrangling, which involves converting data types, aggregating information, and creating new variables.Feature Engineering: Data wrangling allows for the creation of new variables that can enhance the predictive power of machine learning models.Outlier Detection and Handling: It is crucial to detect and manage outliers to prevent them from skewing analysis results. Data wrangling offers techniques for identifying and dealing with outliersData Reduction: In some cases, data can be massive and unwieldy. Wrangling can involve reduction techniques to make the data more manageable without losing critical information.Improved Efficiency: Efficient analysis and modeling require wrangled data, which saves time and lowers error risk.Data Exploration: Data wrangling and exploration are intertwined to gain insight and hypotheses for better analysis.Reproducibility: A well-documented data wrangling process is essential for collaboration and transparency, allowing others to replicate the same data preparation steps and obtain consistent results.Regulatory Compliance: In regulated industries like finance and healthcare, data wrangling is crucial to ensure data privacy and comply with data protection laws.Better Decision-Making: Clean and well-structured data resulting from effective data wrangling leads to more accurate insights, supporting better decision-making in business and research contexts.
Data wrangling is a crucial step in the data analysis process that enhances the accuracy, reliability, and usability of data. It has a significant role in converting raw data into a format that is suitable for various data-based tasks such as statistical analysis, machine learning, and business intelligence.
Steps of Data Wrangling
Here below 6 steps of data wrangling:
Discovering: systematic wrangling based on some criteria which could restrict and divide the data accordingly.Structuring: the raw data should be restructured to suit the analytically method. Feature engineering can be done in this stage,Cleaning: outliers and missing values identification, transformation and imputation
Outliers: Outliers are data points that differ significantly from other observations. They can arise due to variability in the data or may indicate experimental errors. Outliers can skew results and affect the performance of machine learning models.Missing Values: Missing values occur when no data value is stored for a variable in an observation. They can arise due to various reasons, such as data entry errors, equipment malfunctions, or survey non-responses. Missing values can lead to biased estimates and reduced statistical power.
Enrichingupscale, downsample, or perform data augmentation.
Upscale: Upscaling is the process of increasing the resolution or size of an image or video. It can be done using various algorithms, such as nearest neighbor interpolation, bilinear interpolation, and bicubic interpolation.Downsample: Downsampling is the process of reducing the resolution or size of an image or video. It can be done using various algorithms, such as nearest neighbor interpolation, bilinear interpolation, and bicubic interpolation. `Data Augmentation: Data augmentation is a technique used to increase the diversity of training data without actually collecting new data. It involves applying various transformations to the existing data, such as rotation, translation, scaling, and flipping.
Validating: validation data after processing.Publishing: process for further use
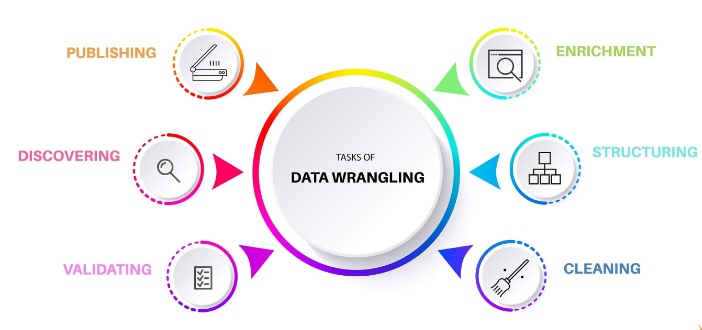
source: FavTutor
Important R Packages for Data Wrangling
Books Focused on Data Wrangling in R
R for Data Science** by Hadley Wickham & Garrett Grolemund
- Free online
- Covers
tidyverse,dplyr,tidyr,readr - Great intro to data wrangling, visualization, and modeling
- Ideal for beginners and intermediate users
Data Wrangling with R by Bradley C. Boehmke
- Deep dive into
dplyr,tidyr,stringr,lubridate, etc. - Practical wrangling scenarios
- Very hands-on and code-focused
Efficient R Programming by Colin Gillespie & Robin Lovelace*
- Covers performance + code efficiency in data wrangling
- Includes parallel processing, profiling, and memory management
General/Language-Agnostic Books on Data Wrangling & Cleaning
Data Cleaning: The Ultimate Practical Guide by Lee Baker
- Language-agnostic; full of strategies and pitfalls to avoid
- Great for understanding what “clean data” really means
The Art of Data Wrangling by Jason L. Callahan
- Covers entire process from messy to clean across domains
- Good for both data scientists and data engineers
Data Science Handbook by Jake VanderPlas
- While broader than just wrangling, it includes detailed sections on data preparation and pipelines
- Covers R, Python, and general best practices