Code
mf<-read.csv("https://github.com/zia207/r-colab/raw/main/Data/R_Beginners/rice_arsenic_data.csv", header= TRUE)![]()

This section of the tutorial focuses on Inferential Statistics using R. Inferential statistics is a branch of statistics that allows us to make conclusions about a population based on a sample of data. It involves estimating population parameters, testing hypotheses, and making predictions. This section will cover key concepts in inferential statistics, including point estimation, interval estimation, data distribution and hypothesis testing. We will also explore how to implement these concepts using R programming language.
Inferential statistics is a crucial branch of statistics that deals with utilizing a sample of data to draw conclusions or make predictions about a larger population. It involves using various statistical methods and techniques to analyze the data and infer results beyond the observed data.
The main goal of inferential statistics is to estimate unknown parameters of a population, such as its mean or variance, based on the information gathered from a sample. By doing so, it helps researchers make informed decisions and draw reliable conclusions about the larger population, even with limited data. In summary, inferential statistics plays a significant role in the field of research by providing a framework for statistical inference and prediction.
Inferential statistics is the branch of statistics that deals with making inferences about a population based on data from a sample. This involves several key concepts used to estimate and test hypotheses about population parameters.
Population and Sample: A population is the entire group of individuals, objects, or events being studied. A sample is a subset of the population used to represent the whole. Choosing a sample representative of the population is important to ensure accurate inferences.
Estimation: Estimation is using sample data to estimate population parameters. There are two types of estimation. Point Estimation involves using sample data to estimate a single value (such as the mean or proportion) for the population. - Interval Estimation: This involves estimating a range within which the population parameter lies. This is typically done using confidence intervals, which provide a range of values with a certain confidence level.
Sampling Distributions: Sampling distributions are the probability distributions of sample statistics (such as the mean or proportion) calculated from repeated random samples drawn from the population. The most important sampling distribution is the sampling distribution of the sample mean, used to make inferences about the population mean.
Hypothesis Testing: Hypothesis testing uses sample data to test hypotheses about population parameters. The key concepts in hypothesis testing are:
Null Hypothesis (H0): This is a statement that there is no effect or no difference between groups.
Alternative Hypothesis (Ha): This statement contradicts the null hypothesis.
Significance Level (α): This is the threshold used to assess the strength of evidence against the null hypothesis.
p-value: This is the probability of observing the data given that the null hypothesis is true.
Types of Errors: There are two types of errors in hypothesis testing: Type I (rejecting a true null hypothesis) and Type II (failing to reject a false null hypothesis).
Regression and Correlation: Regression and correlation are statistical methods used to analyze the relationships between variables in a population. Regression is used to predict one variable’s value based on the values of other variables. In contrast, correlation measures the strength and direction of the relationship between two variables.
Analysis of Variance (ANOVA) is a statistical method to compare means among three or more groups. It tests hypotheses related to mean differences of multiple groups for a given variable. One-Way ANOVA is used when comparing means of a single dependent variable across three or more independent categorical groups. It helps researchers identify significant differences in mean values of the dependent variable across different categories of the independent variable. The results guide further research or interventions aimed at improving outcomes for those groups.
Understanding inferential statistics is critical in decision-making processes in various fields, such as healthcare, social sciences, and business. This tutorial provides a comprehensive understanding of the essential concepts in inferential statistics, making it an indispensable tool for anyone interested in this field.
All data set use in this exercise can be downloaded from my Dropbox or from my Github accounts.
mf<-read.csv("https://github.com/zia207/r-colab/raw/main/Data/R_Beginners/rice_arsenic_data.csv", header= TRUE)When conducting research or gathering data, it’s important to understand the concepts of population and sample. The population refers to the entire group or collection of items or individuals that you’re interested in studying or collecting data from. For example, if you want to know the heights of all individuals in a country, the entire set of heights of every person in that country would constitute the population.
A population parameter is a characteristic of the entire population, such as the mean, standard deviation, proportion, or other measurable attribute. These parameters can be difficult or impossible to determine for the entire population, which is why researchers often rely on samples.
A sample is a subset or smaller group selected from the population. It’s usually not feasible to measure or collect data from every individual in a population, so researchers will select a smaller group to represent the population. For example, if you want to estimate the average height of individuals in a country, you might take a sample of 500 individuals and measure their heights. This smaller group represents the sample.
A sample statistic is a characteristic or measure computed from the sample that is used to estimate or infer the population parameter. For example, if you measure the heights of 500 individuals in a country, you can calculate the average height of the sample, which is a sample statistic. This statistic can be used to estimate the population parameter, such as the average height of all individuals in the country.
Estimation is a statistical technique that uses sample data to make inferences about population parameters. The ultimate goal of estimation is to get as close as possible to the true value of the parameter for the entire population based on information obtained from a representative subset of that population.
There are two main types of estimation: point estimation and interval estimation. Point estimation involves using sample data to estimate a single numerical value for the population parameter, such as the mean or proportion. This approach assumes that the sample is representative of the population and that the parameter being estimated is fixed and known. Interval estimation, on the other hand, involves estimating a range of values within which the population parameter is likely to exist. This is typically done using confidence intervals, which provide a range of values with a certain confidence level. In other words, if the same sample were taken multiple times, the confidence interval would contain the true population parameter in a certain percentage of cases.
Interval estimation is generally considered more informative than point estimation, as it provides a range of values rather than a single-point estimate. However, it also requires more data and assumptions about the population distribution being studied. Ultimately, the choice between point estimation and interval estimation depends on the specific research question, the available data, and the precision required for the analysis.
# Estimating the Population Mean
# Calculating the sample mean (point estimate for the population mean)
sample_mean <- mean(mf$GAs)
sample_mean[1] 1.36003# Calculating the sample proportion (point estimate for the population proportion)
data<-mf$TREAT
sample_proportion <- sum(data == "Low As") / length(data)
sample_proportion[1] 0.5In statistical analysis, interval estimation is a technique used to estimate the value of an unknown population parameter with a degree of certainty. This technique involves calculating a range, or interval, of values within which the true value of the parameter is likely to fall, based on a sample of data. This interval provides researchers with a measure of the uncertainty around the point estimate of the population parameter, and enables them to make inferences about the population with a known level of confidence.
# Confidence Interval for Population Mean
data <- mf$GAs
# Calculating the sample mean and standard deviation
sample_mean <- mean(data)
sample_std_dev <- sd(data)
# Calculating the confidence interval for the population mean (assuming normal distribution)
confidence_level <- 0.95 # Adjust as needed
alpha <- 1 - confidence_level
n <- length(data)
# Calculating margin of error
margin_of_error <- qt(1 - alpha / 2, n - 1) * (sample_std_dev / sqrt(n))
# Calculating lower and upper bounds of the confidence interval
lower_bound <- sample_mean - margin_of_error
upper_bound <- sample_mean + margin_of_error
# Outputting the confidence interval
print(paste("Confidence Interval for Population Mean (95%):",
round(lower_bound, 2), "to", round(upper_bound, 2)))[1] "Confidence Interval for Population Mean (95%): 1.28 to 1.44"To compute an interval, we use the sample mean, sample standard deviation, and the t-distribution. This accounts for any uncertainty. If you adjust the confidence_level variable, you can change the confidence level for the interval estimation. Understanding interval estimation is important as it helps you quantify the uncertainty around point estimates. It also provides a range of values where the true population parameter is likely to fall.
The sampling distribution is a statistical concept that refers to the probability distribution of a statistic, such as the mean, variance, or proportion, obtained from multiple random samples taken from the same population. It helps illustrate how sample statistics might vary if multiple samples were drawn from the same population. This distribution is a theoretical representation of all possible sample statistics obtained from repeated sampling from the same population. Understanding the sampling distribution is critical in statistical inference, as it helps determine the probability of obtaining a particular sample statistic and, consequently, the likelihood of making accurate inferences about the population
set.seed(42) # Setting seed for reproducibility
# Number of samples to draw
num_samples <- 1000
sample_size <- 30 # Size of each sample
# Creating an empty vector to store sample means
sample_means <- numeric(num_samples)
# Generating multiple samples and calculating sample means
for (i in 1:num_samples) {
sample <- sample(mf$GAs, sample_size)
sample_means[i] <- mean(sample)
}We use hist() function to create a histogram of means:
# Plotting the histogram of sample means
hist(sample_means, breaks = 30, col = "skyblue", main = "Sampling Distribution of the Mean")
abline(v=mean(mf$As), col="red")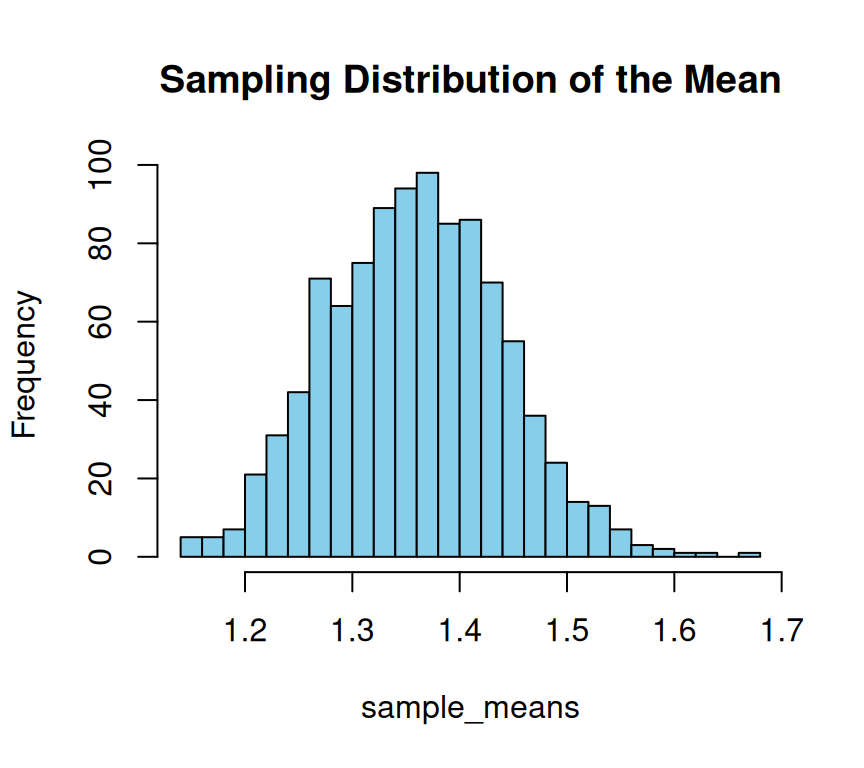
In the above example, we draw 1000 samples of size 30 from this population. For each of these samples, we calculate their means. Finally, we plot a histogram of these sample means, which shows the approximate normal distribution. This means that as the sample size increases, the sample means tend to approach a normal distribution, regardless of the shape of the population distribution. The Central Limit Theorem is a fundamental statistical concept that allows us to make inferences about a population based on a sample. Red line on plot show the population mean.
Central Limit Theorem
The Central Limit Theorem is a statistical concept that explains how the distribution of sample means tends to be normally distributed, regardless of the underlying population distribution, as the sample size increases. In simpler terms, if we were to take several random samples from a population, the average of each sample would create a normal distribution, even if the original population is not normally distributed. This theorem is widely used in statistical analysis and is essential in making inferences about the population based on the sample data..
In statistics, data distribution is a fundamental concept that describes how data points are distributed or spread out over a range of values. It is an important aspect of statistical analysis as it helps to understand the underlying characteristics of a data set. A thorough understanding of data distribution allows researchers to select appropriate statistical tests, detect outliers, identify patterns and trends, and make informed decisions.
Data distribution can be represented graphically using various methods such as histograms, density plots, and qq-plots or probability plots. Histograms are graphical representations that display the distribution of numerical data. They plot the frequency of data points within different intervals or “bins” along the x-axis. Density plots are similar to histograms, but they use a smooth curve instead of using bars to represent the frequency of data points. Qq-plots or probability plots are graphical methods used to assess whether a given data set follows a particular distribution. These plots compare the distribution of the data set to a theoretical distribution, such as the normal distribution.
There are several types of data distributions, including:
Normal distribution is also known as Gaussian distribution, it is a bell-shaped curve that is symmetric around the mean. It is used to model data that is distributed evenly around the mean, with a few data points on the tails of the distribution.
The probability density function (pdf), (a statistical function that describes the likelihood of a continuous random variable taking on a particular value) of the normal distribution is given by the following formula:
\[ f(x \mid \mu, \sigma) = \frac{1}{\sigma \sqrt{2\pi}} \, e^{-\frac{1}{2}\left(\frac{x - \mu}{\sigma}\right)^2} \]
Where:
- \(x\) is the variable for which the probability density is calculated.
- \(\mu\) is the mean of the distribution.
- \(\sigma\) is the standard deviation of the distribution.
- \(e\) is the mathematical constant Euler’s number (approximately 2.71828).
This formula describes the bell-shaped curve of the normal distribution. The parameters \(\mu\) and \(\sigma\) determine the location and spread of the distribution, respectively.
When \(mu = 0\) and \(sigma = 1\), the normal distribution is referred to as the standard normal distribution. In this case, the formula simplifies to:
\[ f(x) = \frac{1}{\sqrt{2\pi}} \, e^{-\frac{1}{2}x^2} \]
This standard normal distribution has a mean of 0 and a standard deviation of 1. The probability density function represents the likelihood of observing a particular value \(x\) in the distribution.
R has four in built functions to generate normal distribution. They are described below.
dnorm(x, mean, sd) - vector of quantiles
pnorm(q, mean, sd) - vector of quantiles
qnorm(p, mean, sd) - vector of probabilities
rnorm(n, mean = 0, sd = 1) - number of observations. If length(n) > 1, the length is taken to be the number required
x = seq(-15, 15, by=0.5)
y = dnorm(x, mean(x), sd(x))
# Plot the graph.
plot(x, y, main= "Normal distribution") 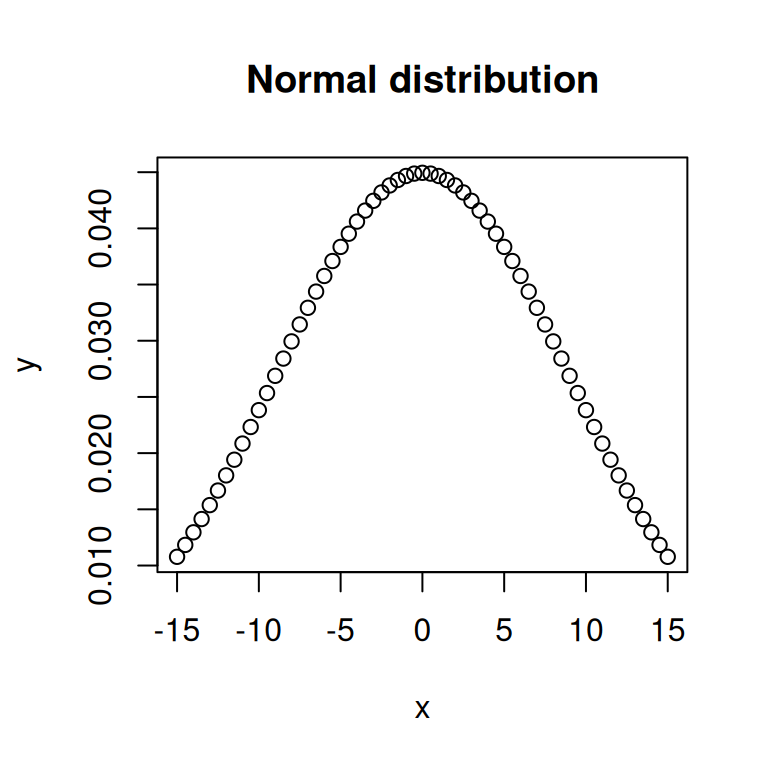
Skewed distribution: A skewed distribution is one in which the data points are not evenly distributed around the mean. There are two types skewed distributions: positively skewed (skewed to the right) and negatively skewed (skewed to the left). In a positively skewed distribution, the tail of the distribution is longer on the right side, while in a negatively skewed distribution, the tail is longer on the left side.
par(mfrow = c(1, 2))
set.seed(5)
#left or negatively skewness
x = rbeta(100000,100,1)*10
hist(x,
main="Negatively Skewed")
#right skewness or positively
hist(rbeta(100000,1,100)*10,
main='Positively Skewed')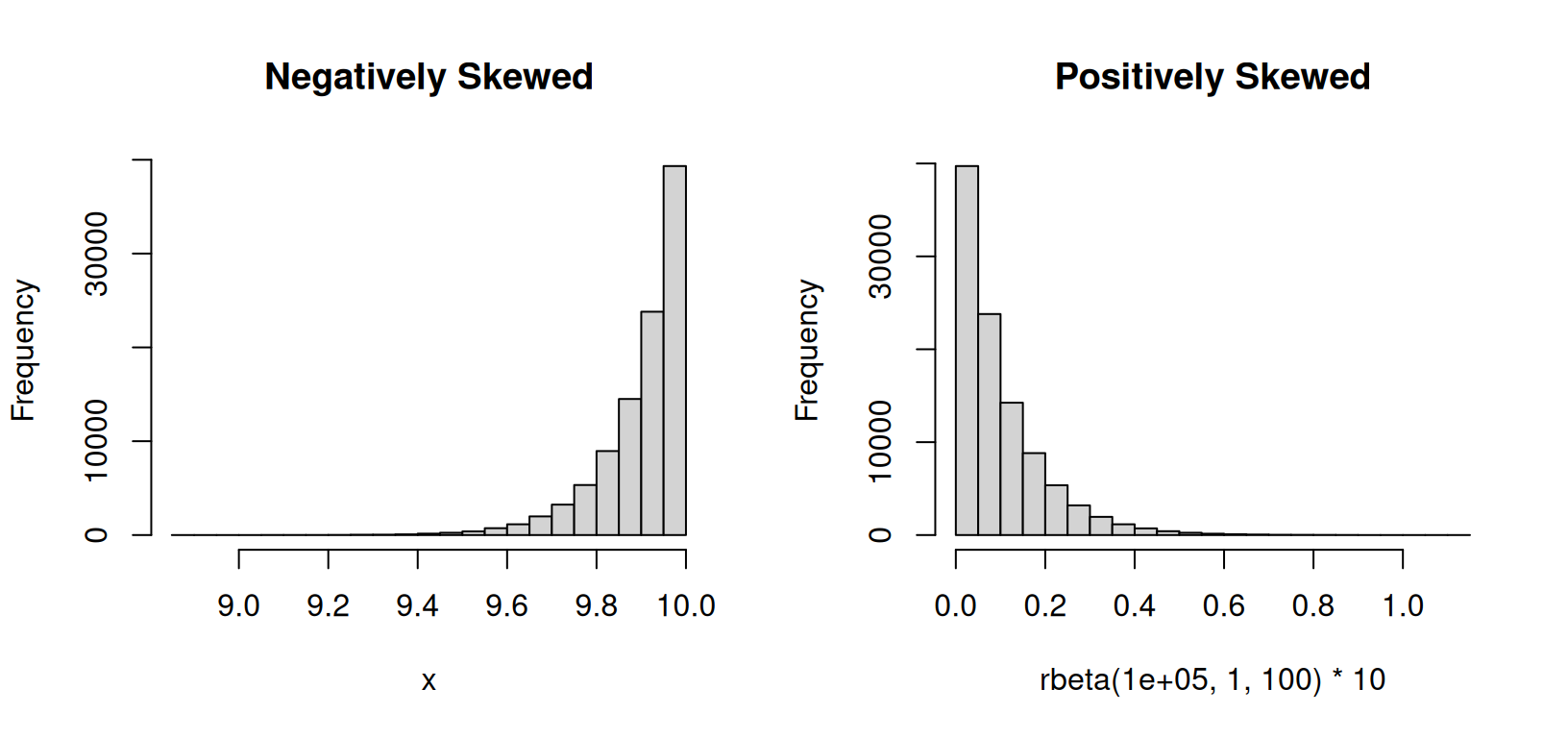
A Uniform distribution on is one in which all the data points are equally likely to occur. This type of distribution is often used in simulations and random number generation.
#
# Generating Uniformly distributed data
set.seed(123) # Setting seed for reproducibility
# Generating Uniform distributed data within a specified interval
uniform_data <- runif(1000, min = 0, max = 10) # Change min and max values as needed
# Plotting the Uniform distribution
hist(uniform_data,
breaks = 30,
col = "lightgreen",
main = "Uniform Distribution", xlab = "Values")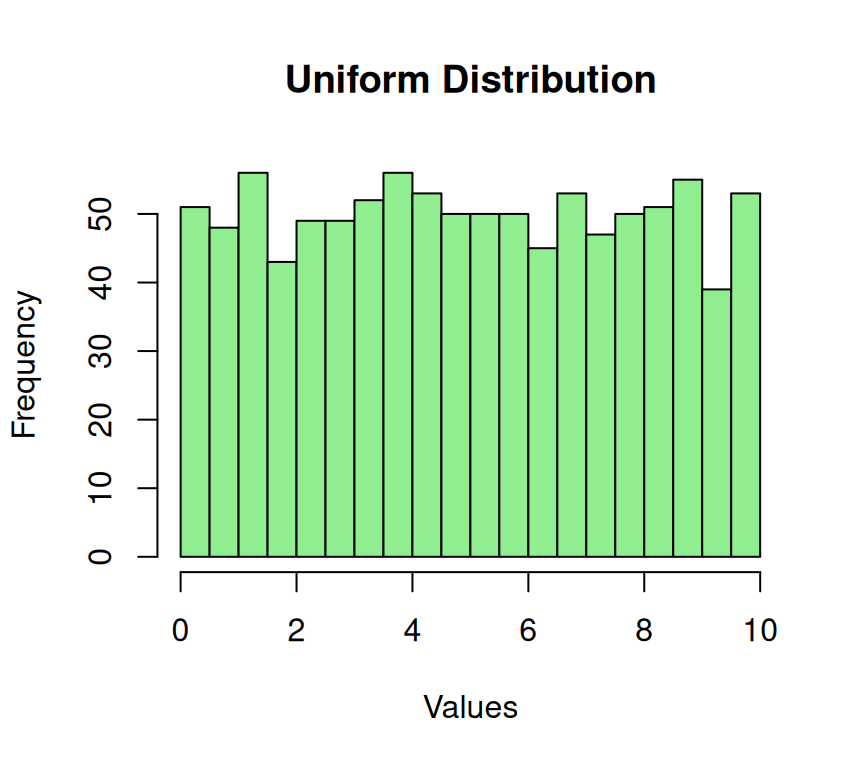
A bimodal distribution has two distinct peaks or modes. This means that the data can be divided into two distinct groups with different characteristics or patterns. For example, a data set of test scores may have one peak for students who scored well and another for students who scored poorly. This type of distribution can occur when two different populations are merged or when a single population exhibits two different patterns. Bimodal distributions are essential to understanding statistics because they can affect data interpretation and statistical models’ accuracy.
The common way to create a bimodal distribution is by combining two unimodal distributions. Let’s consider a simple example where we create a bimodal distribution by summing two normal distributions:
If \(X_1 \sim \mathcal{N}(\mu_1, \sigma_1^2)\) and \((X_2 \sim \mathcal{N}(\mu_2, \sigma_2^2)\) are two independent normal distributions, then their sum \(Y = X_1 + X_2\) would result in a distribution that is bimodal. The parameters \(\mu_1, \sigma_1, \mu_2, \sigma_2\) determine the location and spread of each individual normal distribution, and the sum introduces the bimodal characteristic.
The probability density function (PDF) of the bimodal distribution is obtained by convolving the PDFs of the individual distributions. For normal distributions, the convolution of two normal distributions is another normal distribution. Therefore, the PDF of the sum of two normal distributions is itself a normal distribution, and the sum creates the bimodal appearance.
The PDF for the sum of two normal distributions would involve terms related to \(\mu_1, \sigma_1, \mu_2, \sigma_2\), and their interplay would determine the location and separation of the modes.
#
# Generating a bimodal distribution by combining two normal distributions
set.seed(123) # Setting seed for reproducibility
# Generating data from two normal distributions
data1 <- rnorm(500, mean = 10, sd = 2) # First normal distribution
data2 <- rnorm(500, mean = 20, sd = 3) # Second normal distribution
# Combining the data from both distributions
bimodal_data <- c(data1, data2)
# Plotting the bimodal distribution
hist(bimodal_data,
breaks = 30,
col = "skyblue",
main = "Bimodal Distribution",
xlab = "Values")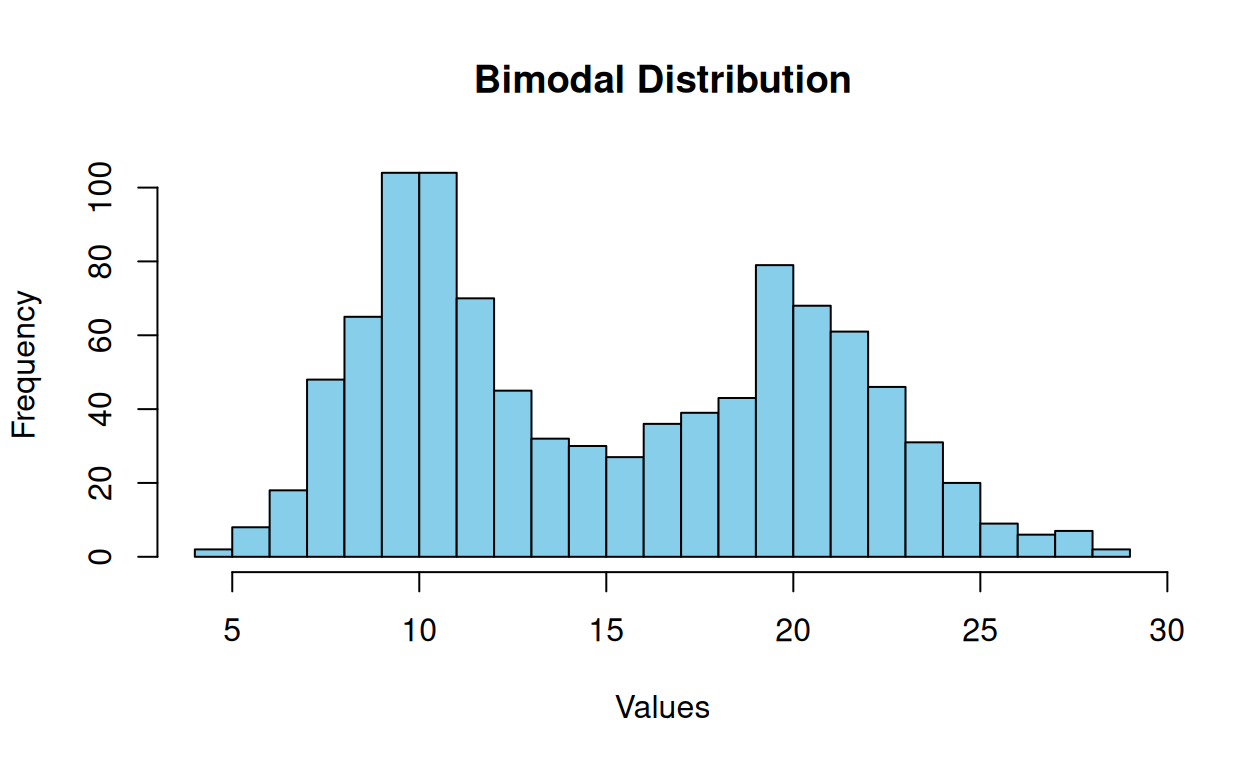
The log-normal distribution is used when the logarithm of a variable follows a normal distribution. In other words, if the natural logarithm of a variable (e.g., stock prices, asset returns, etc.) is normally distributed, then the variable follows a log-normal distribution. This distribution is frequently used in finance and economics to model stock prices, asset returns, and income phenomena. The log-normal distribution is characterized by its skewed shape, with a long right tail and a short-left tail. Despite its asymmetry, the log-normal distribution has valuable properties, such as being closed under multiplication, making it a useful tool for modeling certain data types.
The probability density function (PDF) of the log-normal distribution describes the distribution of a random variable whose natural logarithm is normally distributed. If \(X\) is a log-normally distributed random variable, its PDF is given by:
\[ f(x \mid \mu, \sigma) = \frac{1}{x\sigma\sqrt{2\pi}} \exp\left(-\frac{(\ln(x) - \mu)^2}{2\sigma^2}\right) \]
Where:
- \(x > 0\) is the variable for which the probability density is calculated.
- \(\mu\) is the mean of the natural logarithm of the distribution.
- \(\sigma\) is the standard deviation of the natural logarithm of the distribution.
- \(\pi\) is the mathematical constant pi (approximately 3.14159).
- \(\ln(x)\) is the natural logarithm of \(x\).
In the formula, \(\mu\) and \(\sigma\) are parameters that determine the location and spread of the distribution, respectively.
# Generating log-normal distributed data
set.seed(123) # Setting seed for reproducibility
# Generating log-normal distributed data with specified meanlog and sdlog
log_normal_data <- rlnorm(1000, meanlog = 0, sdlog = 1)
# Plotting the log-normal distribution
hist(log_normal_data, breaks = 30,
col = "lightgreen",
main = "Log-Normal Distribution", xlab = "Values")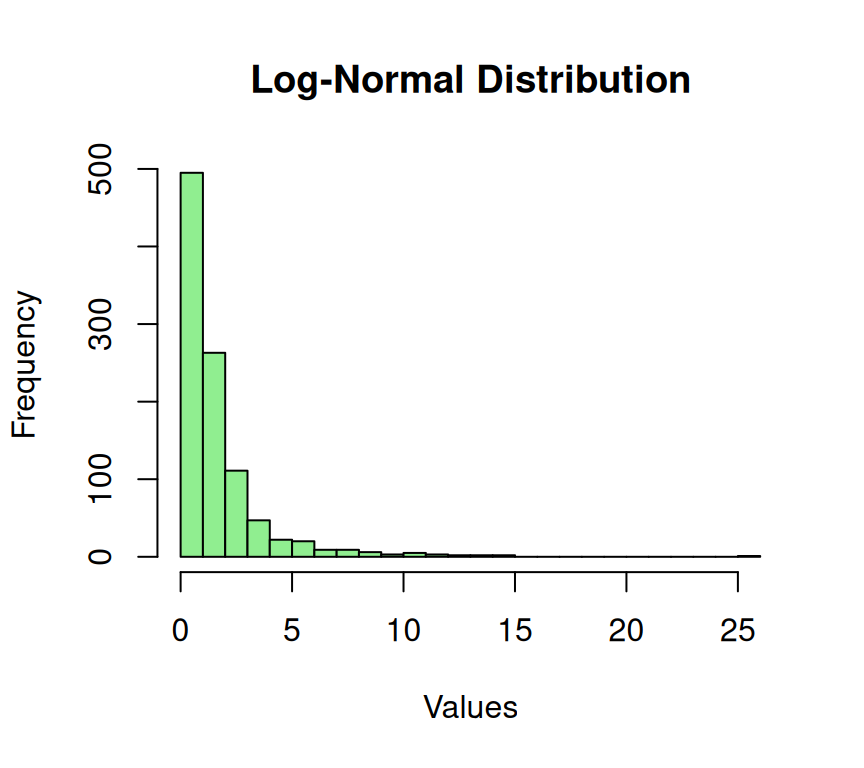
In probability theory and statistics, the exponential distribution is a continuous probability distribution widely used to represent the time between two events occurring in a Poisson process. The Poisson process is a stochastic process that models the number of events occurring in a fixed time interval, given that the events occur independently and at a constant rate (\(\lambda\)). The exponential distribution is used to model the time between two such events, assuming that the events occur independently and at a constant rate. It is a fundamental distribution in the field of reliability engineering and is used to model the failure times of devices that fail at a constant rate. It also has applications in queuing theory, where it is used to model the time between the arrivals of customers to a service facility.
The exponential distribution is defined for \(x \geq 0\) and is given by:
\[ f(x \mid \lambda) = \lambda e^{-\lambda x} \]
Where:
- \(x\) is the variable for which the probability density is calculated.
- \(\lambda\) is the rate parameter, representing the average number of events per unit of time.
The cumulative distribution function (CDF) of the exponential distribution is given by:
\[ F(x \mid \lambda) = 1 - e^{-\lambda x} \]
Where:
- \(F(x \mid \lambda)\) is the probability that the random variable is less than or equal to \(x\).
# Generating exponentially distributed data
set.seed(123) # Setting seed for reproducibility
# Generating exponential distributed data with a specified rate parameter (lambda)
exponential_data <- rexp(1000, rate = 0.2) # Change the rate parameter as needed
# Plotting the exponential distribution
hist(exponential_data,
breaks = 30, col = "lightblue",
main = "Exponential Distribution",
xlab = "Values")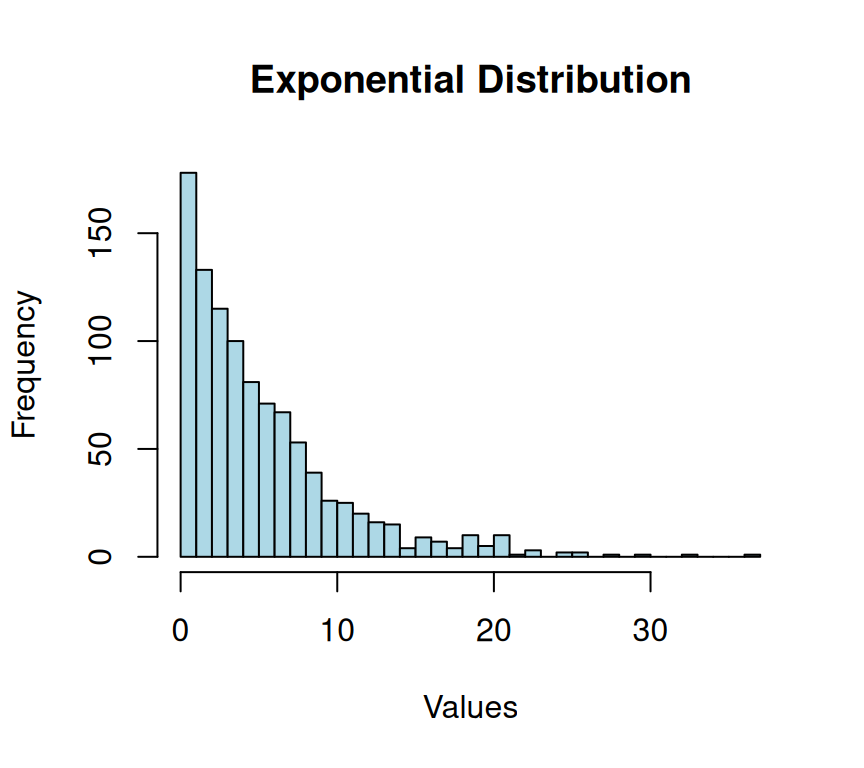
The concept of modeling the frequency of events in a fixed time or space interval involves estimating the number of events that are likely to occur based on a known average rate of occurrence. This technique is commonly used to predict the number of events that are likely to happen within a specific time or space frame. By using a statistical approach, it’s possible to approximate the probability of an event occurring and to make informed decisions based on that probability. This technique is particularly useful in fields such as finance, insurance, and science, where the ability to predict the likelihood of future events is essential for making effective decisions.
The probability mass function (PMF) of the Poisson distribution describes the probability of a given number of events occurring in a fixed interval of time or space, given a known average rate of occurrence (\(\lambda\)). The Poisson distribution is often used to model rare events or events that occur independently of each other.
The PMF of the Poisson distribution is given by:
\[ P(X = k \mid \lambda) = \frac{e^{-\lambda} \cdot \lambda^k}{k!} \]
Where:
- \(X\) is the random variable representing the number of events.
- \(k\) is a non-negative integer (0, 1, 2, …) representing the number of events.
- \(\lambda\) is the average rate of events occurring in the given interval.
- \(e\) is the mathematical constant Euler’s number, approximately 2.71828.
The expression \(\frac{e^{-\lambda} \cdot \lambda^k}{k!}\) represents the probability of observing exactly \(k\) events in the specified interval.
The expected value (mean) and variance of a Poisson-distributed random variable are both equal to \(\lambda\).
# Generating Poisson-distributed data
set.seed(123) # Setting seed for reproducibility
# Generating Poisson distributed data with a specified lambda (mean rate)
poisson_data <- rpois(1000, lambda = 3) # Change the lambda parameter as needed
# Plotting the Poisson distribution
hist(poisson_data,
breaks = 30,
col = "lightgreen",
main = "Poisson Distribution",
xlab = "Values")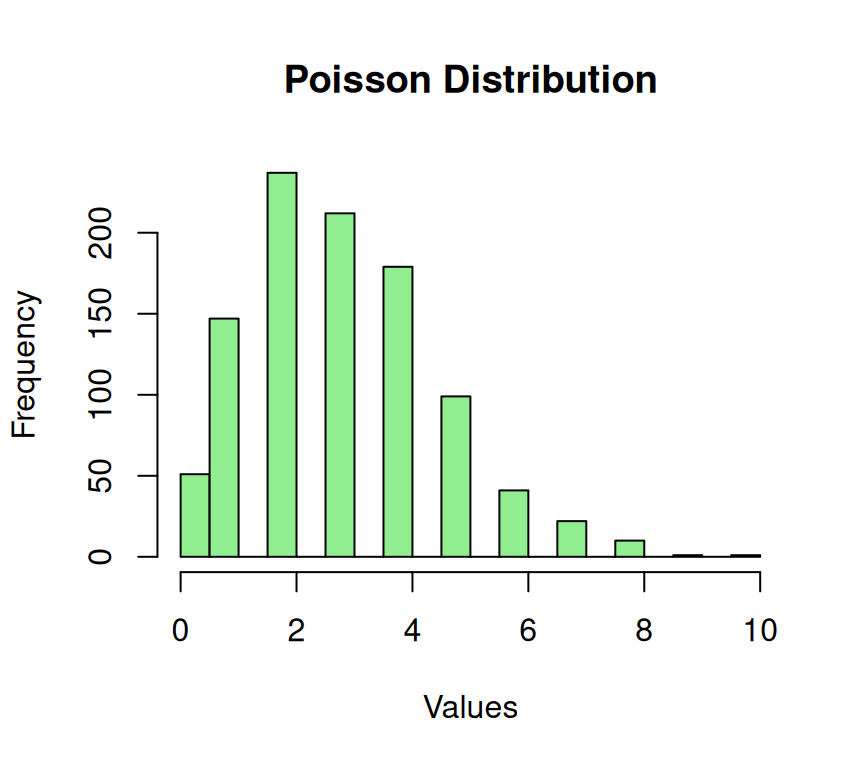
The Gamma and Weibull distribution is a continuous probability distribution commonly used in engineering, physics, and other fields to model variables that take on positive values. It is a generalization of the exponential distribution and is often used when the rate of change is not constant over time. Weibull distribution can exhibit a broader range of shapes, from exponential-like to normal-like, whereas Gamma tends to be more skewed and often shows a different set of shapes. Both distributions have different parameterizations; the Weibull has a shape and scale parameter, while the Gamma has shape and scale parameters but in a different configuration. Weibull is commonly used in reliability engineering for modeling time to failure or survival analysis. At the same time, Gamma is more diverse, being applied in various fields for modeling different types of skewed data, such as income distribution or wait times.
Gamma Distribution:
The probability density function (PDF) of the gamma distribution is defined as follows:
\[ f(x \mid \alpha, \beta) = \frac{\beta^\alpha x^{\alpha - 1} e^{-\beta x}}{\Gamma(\alpha)} \]
Where:
- \(\alpha\) is the shape parameter.
- \(\beta\) is the rate parameter.
- \(\Gamma(\alpha)\) is the gamma function.
The gamma distribution is a generalization of the exponential distribution. When \(\alpha = 1\), it reduces to the exponential distribution.
par(mfrow = c(1, 2))
# Create a sequence of x values
x_gamma <- seq(0, 10, length.out = 100)
# Calculate PDF values
pdf_gamma <- dgamma(x_gamma, shape = 2, rate = 1) # Example parameters: shape = 2, rate = 1
# Plot the PDF
plot(x_gamma, pdf_gamma, type = "l", xlab = "X", ylab = "Density", main = "Gamma PDF")
# Calculate CDF values
cdf_gamma <- pgamma(x_gamma, shape = 2, rate = 1) # Example parameters: shape = 2, rate = 1
# Plot the CDF
plot(x_gamma, cdf_gamma, type = "l", xlab = "X", ylab = "Cumulative Probability", main = "Gamma CDF")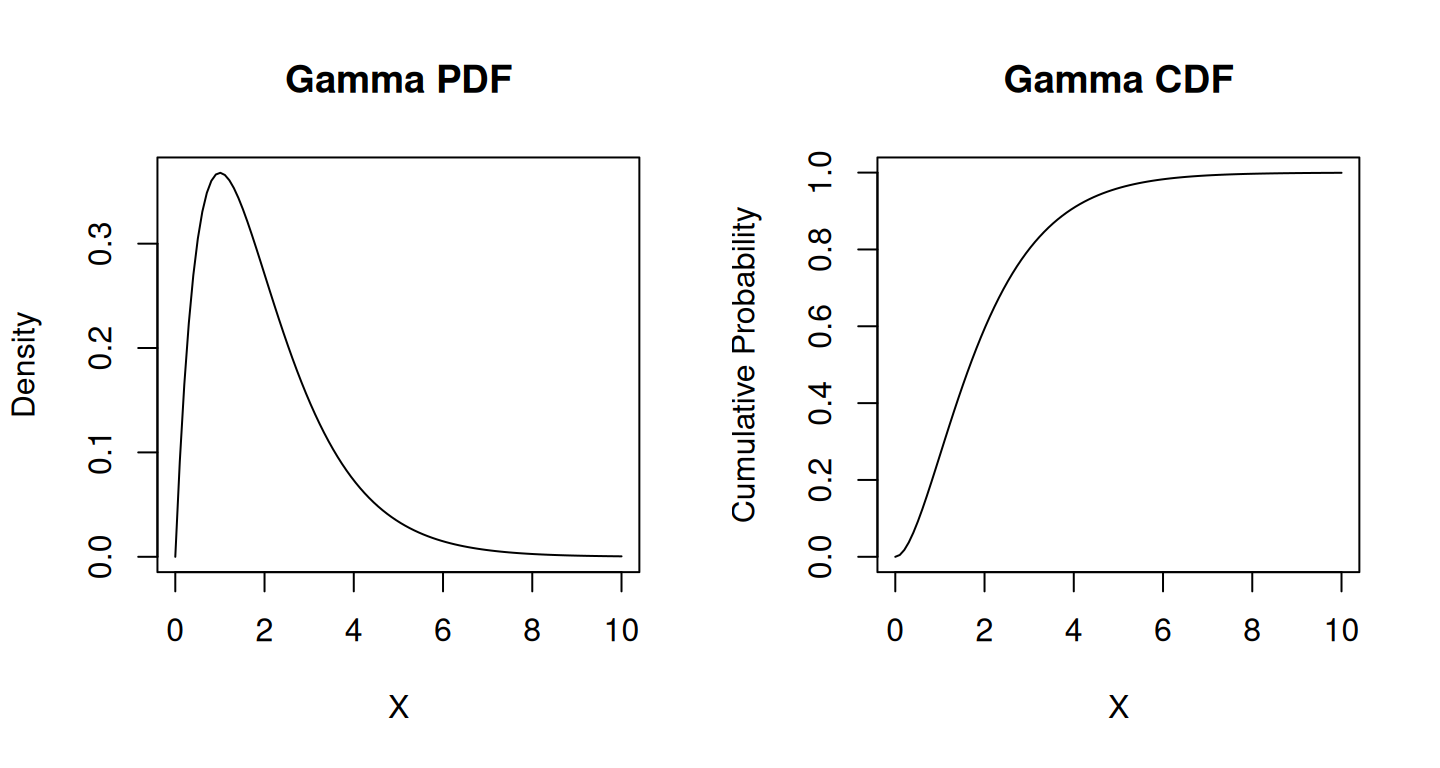
Weibull Distribution
The probability density function (PDF) of the Weibull distribution is defined as follows:
\[ f(x \mid \lambda, k) = \frac{k}{\lambda} \left(\frac{x}{\lambda}\right)^{k-1} e^{-(x/\lambda)^k} \]
Where:
- \(x\) is the variable for which the probability density is calculated.
- \(\lambda\) is the scale parameter.
- \(k\) is the shape parameter.
The Weibull distribution can take on various shapes depending on the value of the shape parameter \(k\). When \(k > 1\), it is right-skewed (increasing hazard rate), when \(k < 1\), it is left-skewed (decreasing hazard rate), and when \(k = 1\), it reduces to the exponential distribution.
par(mfrow = c(1, 2))
# Create a sequence of x values
x_weibull <- seq(0, 10, length.out = 100)
# Calculate PDF values
pdf_weibull <- dweibull(x_weibull, shape = 2, scale = 1) # Example parameters: shape = 2, scale = 1
# Plot the PDF
plot(x_weibull, pdf_weibull, type = "l", xlab = "X", ylab = "Density", main = "Weibull PDF")
# Calculate CDF values
cdf_weibull <- pweibull(x_weibull, shape = 2, scale = 1) # Example parameters: shape = 2, scale = 1
# Plot the CDF
plot(x_weibull, cdf_weibull, type = "l", xlab = "X", ylab = "Cumulative Probability", main = "Weibull CDF")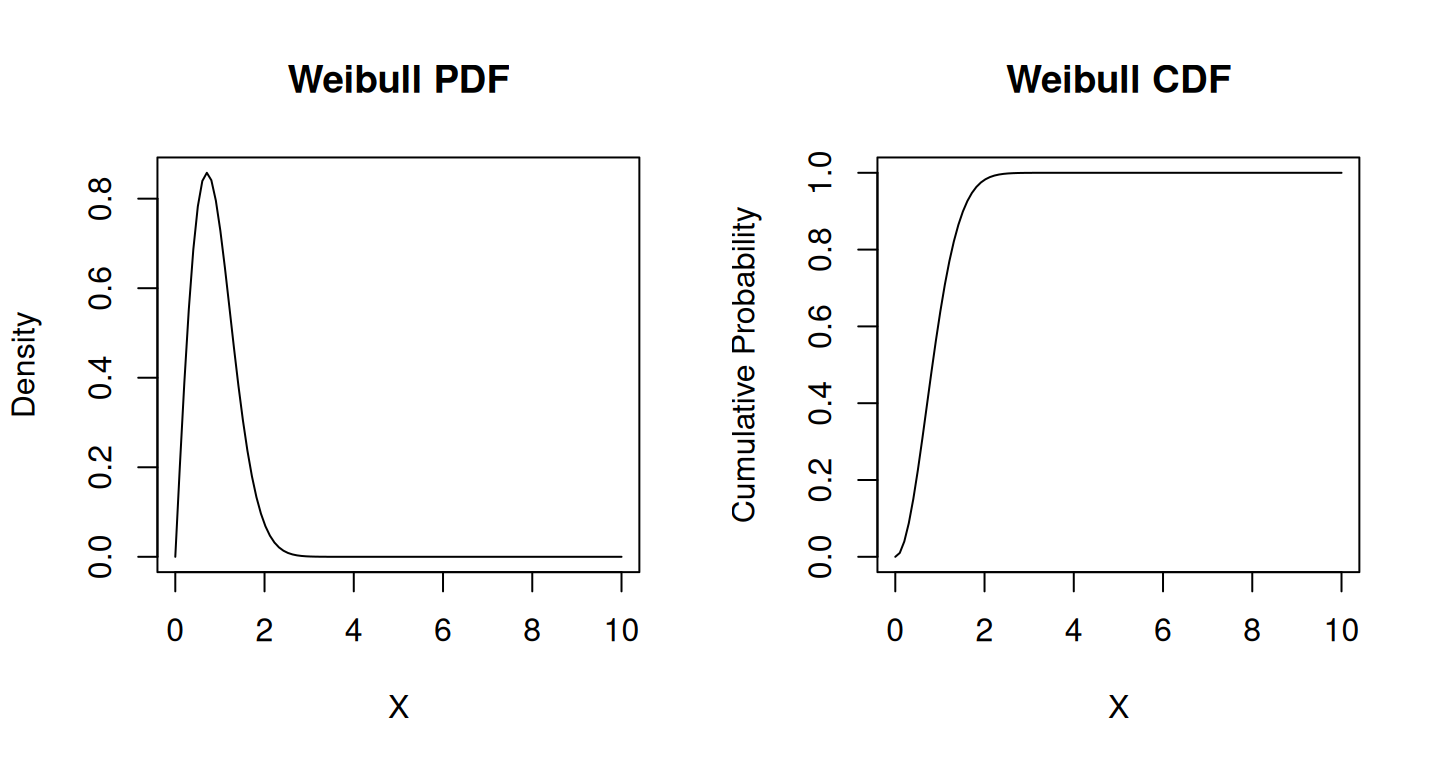
In both the gamma and Weibull distributions, the parameters \(\alpha, \beta, \lambda\), and \(k\) determine the characteristics of the distribution, including its shape, scale, and location. Adjusting these parameters allows for flexibility in modeling different types of data.
The Probability Density Function (PDF) and Cumulative Distribution Function (CDF) are fundamental concepts in probability theory and statistics, both describing different aspects of a probability distribution.
Probability Density Function (PDF)
Definition: The PDF represents the probability that a continuous random variable takes on a particular value or falls within a certain range of values.
Function: For a continuous random variable \(X\), the PDF \(F(x)\) gives the probability density at a specific value \(x\). It’s non-negative and integrates over the entire range to 1.Mathematically, for a continuous random variable \(X\), the probability that \(X\) falls in the interval \([a, b]\) is given by the integral of the PDF over that interval:
\[ P(a \leq X \leq b) = \int_{a}^{b} f(x) \,dx \]
Interpretation: The PDF at a specific point doesn’t directly provide a probability but rather describes the relative likelihood of the variable taking that value.
Use: It’s used to visualize the shape and characteristics of a continuous probability distribution.
Cumulative Distribution Function (CDF)
Definition: The CDF gives the probability that a random variable \(X\) is less than or equal to a certain value \(x\).
Function: For a random variable \(X\) , the CDF \(f(x)\) at a point \(x\) is the probability that \(X\) takes a value less than or equal to \(x\). Mathematically, the CDF is expressed as:
\[ F(x) = \int_{-\infty}^{x} f(t) \,dt \]
The derivative of the CDF with respect to \(x\) gives the PDF: \(f(x) = \frac{d}{dx}F(x)\).
Properties: It always starts at 0 and approaches 1 as (x) increases. It’s non-decreasing, right-continuous, and defines the entire distribution.
Use: It’s useful for determining probabilities of events within a certain range or understanding the overall behavior of a random variable.
Differences:
Nature: PDF gives the density of probabilities at specific values, while CDF gives cumulative probabilities up to a particular value.
Interpretation: PDF does not directly give probabilities but describes relative likelihoods, while CDF directly provides probabilities.
Integration: The CDF is obtained by integrating the PDF, and it’s the accumulation of probabilities up to a certain point.
Ranges: PDF works with individual values or ranges, whereas CDF works with cumulative probabilities up to a given value.
Relationship:
The relationship between the PDF and CDF is integral:
Both PDF and CDF are crucial in understanding and working with probability distributions, with each providing unique insights into the behavior and characteristics of random variables.
The Chi-Square distribution (\(\chi^2\)) is a continuous probability distribution that is commonly used in statistics and probability theory. It is particularly useful in the context of hypothesis testing and confidence intervals. The distribution is derived by summing the squares of independent standard normal random variables. This is known as a sum of squares, which is a common measurement used in statistical analysis. The \(\chi^2\) has a number of important properties that make it a useful tool. For one, it is always positive, which means it can be used to model non-negative random variables. It also has an infinite number of degrees of freedom, which makes it a flexible distribution that can be used in a wide range of applications.
The probability density function (PDF) of the chi-square distribution is defined as follows:
\[ f(x \mid k) = \frac{x^{(k/2 - 1)} e^{-x/2}}{2^{k/2} \Gamma(k/2)} \]
Where:
- \(x\) is the variable for which the probability density is calculated.
- \(k\) is the degrees of freedom parameter.
- \(\Gamma(k/2)\) is the gamma function evaluated at \(k/2\).
The \(\chi^2\) is a continuous probability distribution that arises in the context of statistical inference, particularly in hypothesis testing and confidence interval construction. The degrees of freedom parameter, \(k\), determines the shape of the distribution.
Key points: - The \(\chi^2\) is the distribution of the sum of the squares of \(k\) independent standard normal random variables. - When \(k = 1\), the \(\chi^2\) is equivalent to the exponential distribution. - The expected value (mean) of the \(\chi^2\) is \(k\), and its variance is \(2k\).
The \(\chi^2\) plays an important role in many statistical tests, including the Chi-Square test for goodness of fit, the Chi-Square test for independence, and the Chi-Square test for homogeneity. These tests are commonly used to determine whether a set of data is consistent with a particular hypothesis or whether there is a significant difference between two or more groups. Overall, the \(\chi^2\) is a powerful tool for analyzing data and making predictions. Its properties and applications make it a valuable resource for statisticians and researchers across a wide range of fields.
# Generating Chi-Square distributed data
set.seed(123) # Setting seed for reproducibility
# Generating Chi-Square distributed data with specified degrees of freedom
df <- 5 # Change degrees of freedom as needed
chi_square_data <- rchisq(1000, df)
# Plotting the Chi-Square distribution
hist(chi_square_data,
breaks = 30,
col = "lightpink",
main = "Chi-Square Distribution",
xlab = "Values")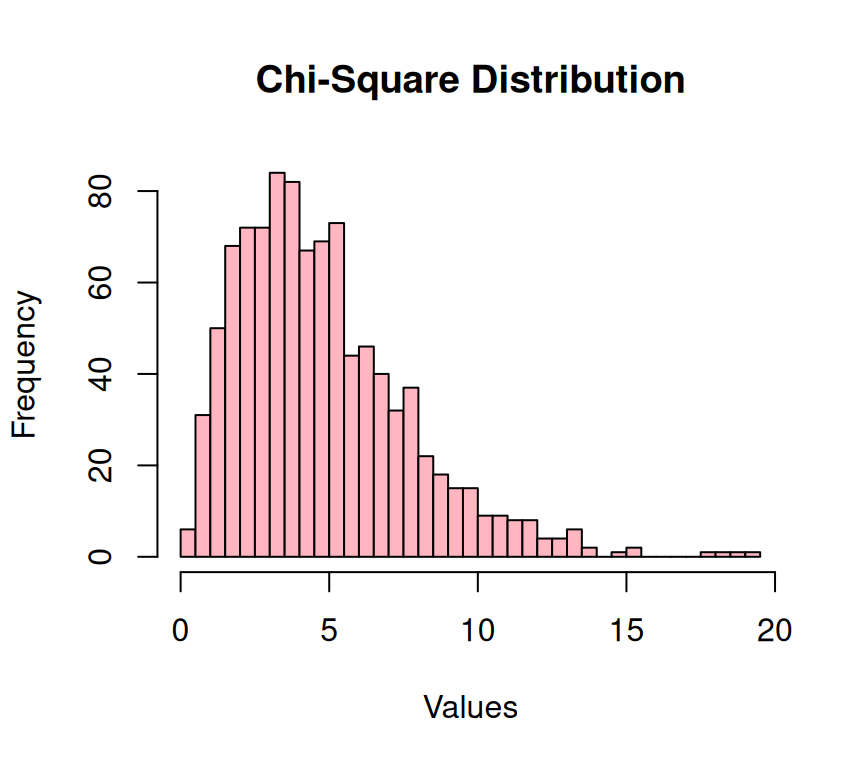
The Beta distribution is a probability distribution that is commonly used to model random variables that have values constrained to a fixed interval between 0 and 1. The distribution function takes two parameters, alpha and beta, which are shape parameters that determine the shape of the distribution.
The probability density function (PDF) of the beta distribution is defined as follows:
\[ f(x \mid \alpha, \beta) = \frac{x^{\alpha-1} (1-x)^{\beta-1}}{B(\alpha, \beta)} \]
Where:
- \(x\) is the variable for which the probability density is calculated, and \(0 \leq x \leq 1\).
- \(\alpha\) and \(\beta\) are shape parameters, and \(\alpha, \beta > 0\).
- \(B(\alpha, \beta)\) is the beta function, given by \(B(\alpha, \beta) = \frac{\Gamma(\alpha) \Gamma(\beta)}{\Gamma(\alpha + \beta)}\), where \(\Gamma\) is the gamma function, an extension of the factorial function to complex numbers and real numbers (except negative integers where it is undefined).
The beta distribution is defined on the interval \([0, 1]\), making it suitable for modeling random variables that represent proportions or probabilities. The shape parameters \(\alpha\) and \(\beta\) control the shape of the distribution.
Key points:
- When \(\alpha = \beta = 1\), the beta distribution is the uniform distribution on \([0, 1]\).
- As \(\alpha\) and \(\beta\) increase, the distribution becomes more peaked around the mean.
- The expected value (mean) of the beta distribution is \(\frac{\alpha}{\alpha + \beta}\), and its variance is given by \(\frac{\alpha \beta}{(\alpha + \beta)^2 (\alpha + \beta + 1)}\).
The Beta distribution is widely used in Bayesian statistics because it provides a way to model the uncertainty of a probability distribution. It is also used in machine learning for tasks such as modeling proportions and predicting outcomes based on probabilities. One of the key advantages of the Beta distribution is its flexibility. It can be used to model a wide range of shapes and can be customized to fit specific data sets. This makes it a versatile tool for data analysis and modeling. Furthermore, the Beta distribution has several important properties that make it a useful tool in statistical analysis. For instance, it is a conjugate prior for the binomial and Bernoulli distributions, which means that it can be used to update the prior belief about the probability of a binary outcome when new data become available.
Overall, the Beta distribution is an essential tool for anyone working with data that is constrained to lie within a fixed range, such as probabilities, proportions, or percentages. Its versatility, flexibility, and important statistical properties make it a powerful tool for data analysis and modeling.
# Generating Beta-distributed data
set.seed(123) # Setting seed for reproducibility
# Generating Beta distributed data with specified shape parameters (alpha and beta)
alpha <- 2 # Change alpha parameter as needed
beta <- 3 # Change beta parameter as needed
beta_data <- rbeta(1000, shape1 = alpha, shape2 = beta)
# Plotting the Beta distribution
hist(beta_data,
breaks = 30,
col = "lightblue",
main = "Beta Distribution",
xlab = "Values")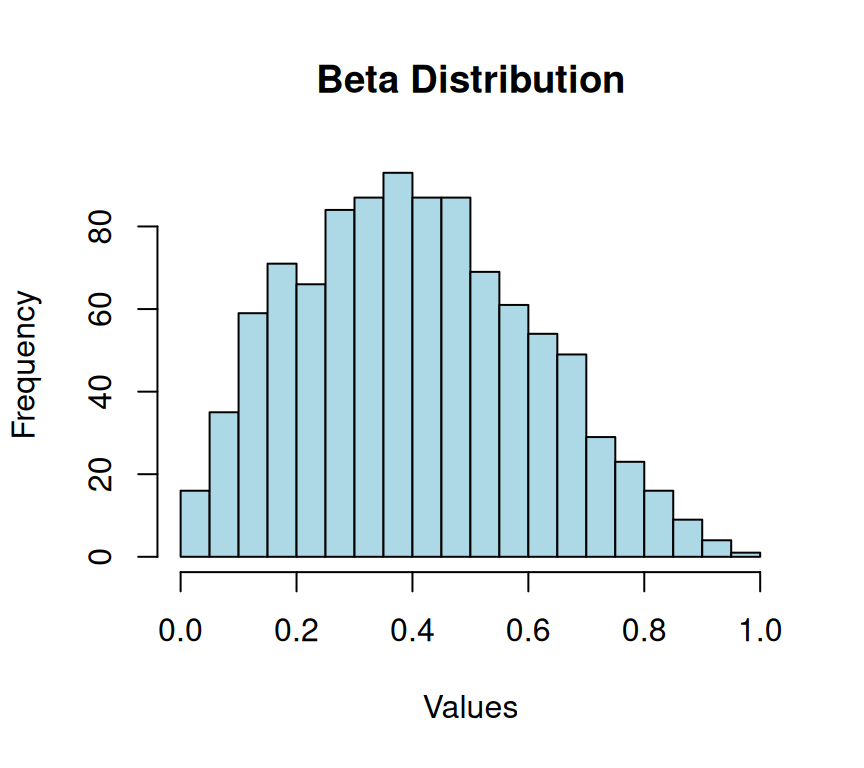
The t-distribution, also known as Student’s t-distribution, is a probability distribution that is symmetric and bell-shaped, much like the normal distribution. However, it has heavier tails compared to the normal distribution, allowing for more variability in data.
The probability density function (PDF) of the t-distribution is given by:
\[ f(t \mid \nu) = \frac{\Gamma\left(\frac{\nu + 1}{2}\right)}{\sqrt{\nu \pi} \cdot \Gamma\left(\frac{\nu}{2}\right)} \left(1 + \frac{t^2}{\nu}\right)^{-\frac{\nu + 1}{2}} \]
Where:
- \(t\) is the variable for which the probability density is calculated.
- \(\nu\) is the degrees of freedom parameter.
- \(\Gamma\) is the gamma function.
The t-distribution is used in hypothesis testing when the population standard deviation is unknown, and sample sizes are small. It is similar in shape to the standard normal distribution but has heavier tails. As the degrees of freedom \(\nu\) increase, the t-distribution approaches the standard normal distribution.
Key points: -
When \(\nu = 1\), the t-distribution is equivalent to the Cauchy distribution, which has undefined mean and variance.
The mean of the t-distribution is 0, and its variance is \(\frac{\nu}{\nu - 2}\) for \(\nu > 2\).
The t-distribution is symmetric around 0.
The t-distribution arises from the standardization of normally distributed data when the population standard deviation is unknown and estimated from the sample. It’s frequently used in hypothesis testing, confidence interval estimation, and modeling when dealing with small sample sizes or situations where population variance is not known.
# Generating random numbers from a t-distribution with 10 degrees of freedom
set.seed(123) # Setting seed for reproducibility
t_distribution_data <- rt(1000, df = 10)
# Calculating the probability density at x = 1.5 for t-distribution with 10 degrees of freedom
density_at_x <- dt(1.5, df = 10)
# Calculating the cumulative probability up to x = 1.5 for t-distribution with 10 degrees of freedom
cumulative_prob <- pt(1.5, df = 10)
# Calculating the quantile for a probability of 0.95 in t-distribution with 10 degrees of freedom
quantile_value <- qt(0.95, df = 10)
# Plotting a histogram of t-distributed data
hist(t_distribution_data,
breaks = 30,
col = "lightblue",
main = "Histogram of t-Distributed Data")
The F-distribution, also known as Fisher-Snedecor distribution, is a continuous probability distribution that arises in statistical analysis, particularly in the context of analysis of variance (ANOVA) and regression analysis. It’s used to compare variances or test the equality of means of multiple groups.
The probability density function (PDF) of the F-distribution is given by the formula:
\[ f(x; d_1, d_2) = \frac{{d_1^{\frac{{d_1}}{2}} \cdot d_2^{\frac{{d_2}}{2}} \cdot x^{\frac{{d_1}}{2} - 1}}}{{(d_1 \cdot x + d_2)^{\frac{{d_1 + d_2}}{2}} \cdot B\left(\frac{{d_1}}{2}, \frac{{d_2}}{2}\right)}} \]
Where:
- \(x\) is a non-negative real number.
- \(d_1\) and \(d_2\) are the degrees of freedom parameters.
- \(B\) represents the beta function, a mathematical function that generalizes the concept of factorials to real numbers
The beta function, denoted as \(B(p, q)\), is defined as:
\[ B(p, q) = \int_0^1 t^{p-1} (1-t)^{q-1} \,dt \]
The F-distribution arises in statistical hypothesis testing, particularly in analysis of variance (ANOVA) and regression analysis. The F-statistic, which follows an F-distribution, is used to compare variances or test the equality of means of multiple groups.
In the context of the F-distribution, the degrees of freedom \(d_1\) and \(d_2\) correspond to the degrees of freedom associated with the numerator and denominator of the F-statistic, respectively.
It’s worth noting that there are different parametrizations of the F-distribution, and the formula may be expressed in slightly different ways depending on the conventions used. The key components involve the degrees of freedom and the beta function.
# Define a range of x values
x_values <- seq(0.1, 5, by = 0.1) # Define your range accordingly
# Calculate the probability density function (pdf) of the F-distribution for given degrees of freedom df1 and df2
pdf_values <- df(x_values, df1 = 5, df2 = 10) # Change df1 and df2 as needed
# Plot the F-distribution
plot(x_values,
pdf_values,
type = "l",
col = "blue",
lwd = 2,
main = "F-Distribution",
xlab = "x",
ylab = "Density")
Hypothesis testing is a widely used statistical approach that enables researchers to conclude a population parameter based on the sample data. It is a technique used to evaluate the validity of a hypothesis by examining the evidence presented through the data. It involves setting up two competing hypotheses: a null hypothesis and an alternative hypothesis. The null hypothesis is generally considered the default hypothesis, stating that there is no significant difference between the sample and the population. The alternative hypothesis, on the other hand, is the hypothesis that is tested against the null hypothesis and is generally the researcher’s primary hypothesis. After setting up the hypotheses, the researcher collects data to determine which hypothesis is more likely to be true. The process involves analyzing the evidence presented by the data to either accept or reject the null hypothesis. Hypothesis testing is a powerful tool that allows researchers to make informed decisions based on statistical evidence.
Key Steps in Hypothesis Testing:
Formulating Hypotheses:
Null Hypothesis (H0): Represents the status quo or no effect.
Alternative Hypothesis (Ha): Contradicts the null hypothesis, suggesting an effect or difference.
Choosing a Significance Level (α):
The significance level is the threshold for rejecting the null hypothesis.
Commonly used values are 0.05 or 0.01.
Collecting and Analyzing Data:
Making a Decision:
Compare the test statistic to a critical value (from a statistical distribution) or calculate a p-value.
If the test statistic falls into the rejection region (extreme values), reject the null hypothesis. Otherwise, fail to reject it.
Drawing Conclusion:
A t-test is a statistical hypothesis test that compares the means of two groups or samples to determine if they are significantly different from each other. A commonly used parametric test assumes the data follows a normal distribution. There are two types of t-tests: One-sample t-test and Two-sample t-test. The one-samples t-test is used to determine if a sample mean is significantly different from a known population mean. While A two-sample t-test is a statistical test used to determine if two sets of data are significantly different from each other.
\[ t = \frac{\bar{X} - \mu_0}{\frac{s}{\sqrt{n}}} \]
In these formulas, \(\bar{X}\) represents the sample mean, \(\mu_0\) is the hypothesized population mean, \(s\) is the sample standard deviation, and \(n\) is the number of observations in the sample. The t-statistic is then compared to a critical value from the t-distribution to assess statistical significance.
The t-test() calculates the t-value and then compares it to a critical value from the t-distribution to determine if the difference between the means is statistically significant. If the t-value is greater than the critical value, then we conclude that there is a significant difference between the means of the two groups or samples.
set.seed(42) # Setting seed for reproducibility
# sample
sample_data <- sample(mf$GAs, 50)
sample_mean<-mean(sample)
sample_mean[1] 1.365258# population
population_mean<-mean(mf$GAs)
population_mean[1] 1.36003# One-sample t-test (testing if the sample_mean is significantly different population_mean)
t_test_result <- t.test(sample_data, mu = population_mean)
print(t_test_result)
One Sample t-test
data: sample_data
t = -0.033051, df = 49, p-value = 0.9738
alternative hypothesis: true mean is not equal to 1.36003
95 percent confidence interval:
1.214169 1.501171
sample estimates:
mean of x
1.35767 In this example, a one-sample t-test is performed in R to determine if the mean of the sample is significantly different from true mean. The t.test() function computes the test statistic, the p-value, and provides information to decide whether to reject the null hypothesis.Since the p-value is greater than the level of significance (α) = 0.05, we may to accept the null hypothesis and means sample and population are not significantly different.
A nice and easy way to report results in R is with the report() function from the report package. The primary goal of package report is to bridge the gap between R’s output and the formatted results contained in your manuscript. It automatically produces reports of models and data frames according to best practices guidelines, ensuring standardization and quality in results reporting.

library(report)
report(t_test_result)Effect sizes were labelled following Cohen's (1988) recommendations.
The One Sample t-test testing the difference between sample_data (mean = 1.36)
and mu = 1.36002985712143 suggests that the effect is negative, statistically
not significant, and very small (difference = -2.36e-03, 95% CI [1.21, 1.50],
t(49) = -0.03, p = 0.974; Cohen's d = -4.67e-03, 95% CI [-0.28, 0.27])The chi-square test is a statistical test used to determine if there is a significant association between two categorical variables. It is based on the comparison of observed and expected frequencies in a contingency table which shows the frequencies of the joint occurrences of the categories of the two variables.
The expected frequency for a cell is calculated as
\[ \frac{{\text{Row Total} \times \text{Column Total}}}{{\text{Grand Total}}} \]
Calculate the chi-square (\(\chi^2\)) statistic using the formula: \[ \chi^2 = \sum \frac{{(O_{ij} - E_{ij})^2}}{{E_{ij}}} \] - Where:
- \(O_{ij}\) is the observed frequency in cell (\(i, j\)).
- \(E_{ij}\) is the expected frequency in cell (\(i, j\)).
The chi-square test is commonly used in various fields, including biology, social sciences, and business, to assess the independence of categorical variables. The test is applicable when the variables are categorical and the observations are independent. If the chi-square test indicates a significant association, additional analysis may be needed to understand the nature of the relationship.
In R, the chi-square test can be conducted using the chisq.test() function. Here’s a basic example illustrating how to perform a chi-square test in R:
## Create a contingency table (example data)
df <- matrix(c(40, 10, 11, 25), nrow = 2, byrow = TRUE)
rownames(df) <- c("VAR_A", "VAR_B")
colnames(df) <- c("TREAT_`", "TREAT_2")
# Display the observed data (contingency table)
print("mf:")[1] "mf:"print(df) TREAT_` TREAT_2
VAR_A 40 10
VAR_B 11 25# Perform the chi-square test
chi_square_result <- chisq.test(df)
# Display the results
print("\nChi-Square Test Result:")[1] "\nChi-Square Test Result:"print(chi_square_result)
Pearson's Chi-squared test with Yates' continuity correction
data: df
X-squared = 19.202, df = 1, p-value = 1.176e-05The F-test is a statistical test used to compare the variances of two or more groups. The test is based on the F-statistic, which is the ratio of the variances. The F-test is commonly used in analysis of variance (ANOVA) and regression analysis. Here are the key components and steps of the F-test:
\[ F = \frac{\text{Variance Between Groups}}{\text{Variance Within Groups}} \]
Degrees of Freedom:
The F-test is used to assess whether the variances among groups are significantly different. If the test indicates a significant difference, it may suggest the need for further investigation into which specific groups have different variances.
In R, you can perform an F-test for comparing variances using the var.test() function.
var.test(GY~TREAT, data=mf)
F test to compare two variances
data: GY by TREAT
F = 0.1677, num df = 69, denom df = 69, p-value = 3.12e-12
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.1042069 0.2698937
sample estimates:
ratio of variances
0.1677045 This tutorial aims to equip users with the necessary tools to draw insightful conclusions and make accurate inference based on sample data. It covers a range of fundamental concepts, including the distinction between populations and samples and the critical role of statistical inference in decision-making. Additionally, it delves into essential topics such as hypothesis testing and t-tests, commonly used statistical techniques for testing hypotheses and comparing means between two groups.
The tutorial provides clear explanations and practical examples for each concept covered, making it easy for users to understand and apply what they learn. It also includes step-by-step instructions on how to use R to perform various inferential statistics analyses, such as calculating confidence intervals, conducting hypothesis tests, and performing t-tests. Detail correlation and regression analyses and ANOVA has discussed later.
Whether you’re a beginner or an advanced user seeking to improve your inferential statistics skills, this tutorial is an invaluable resource that can help you achieve your goals. By the end of the tutorial, you will have a solid understanding of inferential statistics and how to use R to draw meaningful conclusions and make accurate predictions based on sample data.