This section is designed to provide a comprehensive introduction to correlation analysis using R. Correlation analysis is a fundamental statistical technique used to assess the strength and direction of the relationship between two or more variables. It plays a crucial role in various fields, including social sciences, finance, healthcare, and environmental studies. By the end of this tutorial, you will have a solid understanding of conducting correlation analysis in R. This will enable you to effectively explore relationships within your datasets and draw meaningful insights from your data.
Introduction
Correlation is a statistical technique used to measure the degree of association between two continuous variables. It measures the linear relationship between two variables, indicating how closely they are related. A correlation coefficient ranges from -1 to +1, with a value of -1 indicating a perfect negative correlation, 0 indicating no correlation, and +1 indicating a perfect positive correlation. Correlation analysis is commonly used in many fields, including economics, finance, psychology, and social sciences, to help understand the relationship between variables and to make predictions based on that relationship.
The most common correlation coefficient is the Pearson correlation coefficient (denoted by \(r\)), and the formula is as follows:
- \(X_i\) and \(Y_i\) are the individual data points for the two variables.
\(\bar{X}\) and \(\bar{Y}\) are the means of the respective variables.
- \(n\) is the number of data points.
This formula calculates the correlation coefficient by dividing the covariance of the two variables by the product of their standard deviations. The correlation coefficient \(r\) ranges from -1 to 1,
where:
- \(r = 1\) indicates a perfect positive linear relationship.
- \(= -1\) indicates a perfect negative linear relationship.
- \(r = 0\) indicates no linear relationship.
In practice, correlation coefficients close to 1 or -1 suggest a strong linear relationship, while coefficients close to 0 suggest a weak or no linear relationship.
However, it is important to note that correlation does not imply causation. This means that just because two variables are found to be correlated, it does not necessarily mean that one variable causes the other. There could be other factors involved that might influence the relationship between the two variables. Therefore, it is essential to exercise caution while interpreting correlation results and avoid making any causal inferences.
Correlation Analysis from Scratch
Below is the R code to perform correlation analysis and calculate the p-value manually:
Code
# Define the two variablesx <-c(2.1, 2.5, 4.0, 3.6)y <-c(8, 10, 12, 14)# Step 1: Calculate meansmean_x <-mean(x)mean_y <-mean(y)# Step 2: Calculate the numerator (covariance)numerator <-sum((x - mean_x) * (y - mean_y))# Step 3: Calculate the denominator (product of standard deviations)denominator <-sqrt(sum((x - mean_x)^2) *sum((y - mean_y)^2))# Step 4: Calculate Pearson correlation coefficientr <- numerator / denominator# Step 5: Calculate the t-statisticn <-length(x) # number of data pointst_stat <- r *sqrt((n -2) / (1- r^2))# Step 6: Calculate the p-value# Degrees of freedom is n - 2df <- n -2p_value <-2*pt(-abs(t_stat), df) # two-tailed test# Output resultscat("Correlation coefficient (r):", r, "\n")
Correlation coefficient (r): 0.8642268
Code
cat("t-statistic:", t_stat, "\n")
t-statistic: 2.429329
Code
cat("p-value:", p_value, "\n")
p-value: 0.1357732
Correlation Analysis with R
Performing correlation analysis in R, a powerful and versatile programming language for statistical computing and graphics, is a straightforward and efficient process. This tutorial will guide you through the following key steps:
Correlation Computation: We will calculate correlation coefficients between variables using the cor() function in R. Depending on your requirements, this function calculates Pearson, Spearman, or Kendall correlation coefficients.
Correlation Test: To test the significance of the correlation coefficient, we will use the cor.test() function.
Visualizing Correlation: Correlation matrices can be challenging to interpret at a glance. We will explore how to visualize correlation matrices using heatmaps, which provide a more intuitive understanding of the relationships between variables.
This section will guide you through the process of performing correlation analysis using R, a powerful programming language for statistical computing and data visualization. We will cover the following key steps:
Check and Install Required R Packages
In these exercise we will use following R-Packages:
tydyverse: The tidyverse is a collection of R packages designed for data science.
plyr: plyr is a set of tools for a common set of problems: you need to split up a big data structure into homogeneous pieces, apply a function to each piece and then combine all the results back together. For example, you might want to:
Hmisc: Contains many functions useful for data analysis, high-level graphics, utility operations,
corrplot:R package corrplot provides a visual exploratory tool on correlation matrix
ggstatsplot: ggplot2 based lots with statistical details
GGally: GGally extends ggplot2 by adding several functions to reduce the complexity of combining geoms with transformed data.
ggside: The package ggside was designed to enable users to add metadata to their ggplots with ease.
RColorBrewer:Provides color schemes for maps (and other graphics)
patchwork:The goal of patchwork is to make it ridiculously simple to combine separate ggplots into the same graphic.
gridExtra:The grid package provides low-level functions to create graphical objects (grobs), and position them on a page in specific viewports.
rstatix: Provides a simple and intuitive pipe-friendly framework, coherent with the ‘tidyverse’ design philosophy, for performing basic statistical tests, including t-test, Wilcoxon test, ANOVA, Kruskal-Wallis and correlation analyses.
The Pearson correlation is a statistical method that helps to determine the strength and direction of the relationship between two continuous variables. It’s a widely used technique in various fields, such as social sciences, finance, and engineering. This method, also known as **Pearson’s r** or the Pearson product-moment correlation coefficient, calculates the degree to which two variables are related. In other words, it measures how much one variable changes when the other variable changes and the formula is as follows:
\(X_i\) and \(Y_i\) are the individual data points for the two variables.
\(\bar{X}\) and \(\bar{Y}\) are the means of the respective variables.
\(n\) is the number of data points.
We can calculate the Pearson correlation coefficient using the cor() function. method is a character string indicating which correlation coefficient (or covariance) is to be computed. One of pearson (default),kendall, or spearman can be abbreviated. Here’s an example:
Nonparametric correlations provide a flexible approach for measuring the relationship between two variables. Unlike traditional parametric methods, which assume that the relationship between variables follows a particular pattern, nonparametric correlations do not make such assumptions. This makes them ideal for use when the analyzed variables are not normally distributed, or the relationship between them is not linear. These measures of association are essential tools in statistical analysis, as they help to identify patterns and trends in data that may not be immediately apparent from simple descriptive statistics. Nonparametric correlations enable researchers and analysts to make more informed decisions based on their data by providing a more nuanced understanding of the relationship between variables.
Two commonly used nonparametric correlation measures are Spearman’s rank correlation coefficient and Kendall’s tau correlation coefficient.
Spearman’s rank correlation coefficient is a non-parametric measure of the strength and direction of monotonic (non-linear) relationships between two variables. In Spearman’s rank correlation, the data is first converted into ranks, and then the correlation is calculated based on the ranks. The formula for Spearman’s rank correlation coefficient \(\rho\) is as follows:
\[ \rho = 1 - \frac{6\sum d_i^2}{n(n^2 - 1)} \]
Where: - \(\rho\) is Spearman’s rank correlation coefficient. - \(d_i\) is the difference between the ranks of corresponding pairs of observations. - \(n\) is the number of pairs of observations.
The calculation involves summing the squared differences between the ranks of corresponding pairs of observations and then applying the formula to obtain the correlation coefficient.
The coefficient ranges from -1 to 1,
where:
\(\rho = 1\) indicates a perfect monotonic increasing relationship.
\(\rho = -1\) indicates a perfect monotonic decreasing relationship.
\(\rho = 0\) indicates no monotonic relationship.
Spearman’s rank correlation is often used when the assumption of linearity in Pearson correlation is not met or when dealing with ordinal data.
An ordinal scale is a type of measurement scale used in statistics and research that categorizes data into distinct, ordered categories. In this scale, the categories possess a clear order or rank, but the differences between the categories are not precisely measurable or equal.
A nominal scale is a categorical measurement scale used in statistics and research that categorizes data into distinct, non-numeric categories or groups without any intrinsic order or rank
Kendall’s Tau correlation coefficient, often denoted as \(\tau\), is another non-parametric measure of association that assesses the strength and direction of the relationship between two variables. It is based on comparing the number of concordant and discordant pairs of observations. The formula for Kendall’s Tau is as follows:
\[ \tau = \frac{{\text{{Number of concordant pairs}} - \text{{Number of discordant pairs}}}}{{\frac{1}{2} n (n - 1)}} \]
Where: - \(\tau\) is Kendall’s Tau correlation coefficient. - \(n\) is the number of pairs of observations. - The number of concordant pairs is the count of pairs for which the ranks have the same order in both variables. - The number of discordant pairs is the count of pairs for which the ranks have different orders in the two variables.
The value of ( \(\tau\) ) ranges from -1 to 1,
where:
\(\tau = 1\) indicates a perfect positive relationship
\(\tau = -1\) indicates a perfect negative relationship.
\(\tau = 0\) indicates no association.
Kendall’s Tau is particularly useful when dealing with ordinal data or when the assumption of linearity in Pearson correlation is not met. It measures the strength of a monotonic relationship between variables.
Concordant typically refers to a situation or data in which two or more items or sets of data align or agree with each other. In statistics or research, concordant data points or results show consistency or agreement in their characteristics, patterns, or relationships.
Discordant refers to a situation where two or more items or sets of data do not align or agree with each other. In statistical analysis or research, discordant data points or results indicate inconsistency or disagreement in their characteristics, patterns, or relationships.
Correlation Test
The cor.test() function is used to test the significance of the correlation coefficient between two variables (both r-and p-values):
Code
cor.test(mf$SOC, mf$NDVI)
Pearson's product-moment correlation
data: mf$SOC and mf$NDVI
t = 15.637, df = 465, p-value < 2.2e-16
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.5242311 0.6435059
sample estimates:
cor
0.5870452
The correlation coefficient between SOC and Fe is 0.3149, and that the p-value of the test is < 2.2e-16, indicating that there is a significant correlation between SOC and Fe at the alpha level of 0.05.
Correlation by Group
We can also calculate spearman correlation coefficients between SOC and Fe in different landcovers. will We will use ddply() function of plyr package which split data frame, apply function, (here cor()), and return r-values in a data frame using summarise argument
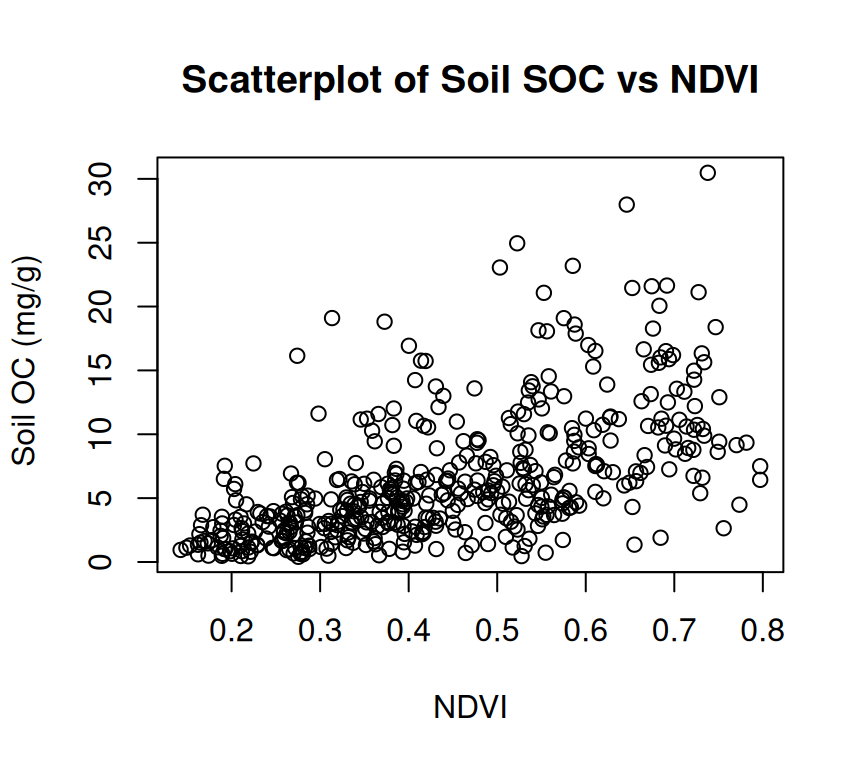
A scatter plot is a type of graph used to display the relationship between two continuous variables. This plot is commonly used in data analysis to explore and visualize the relationship between two variables. They are particularly useful in identifying patterns or trends in data, as well as in identifying outliers or unusual observations.
plot(mf$NDVI, mf$SOC,# x-axis label xlab="NDVI",# y-axis labelylab=" Soil OC (mg/g)", # Plot titlemain="Scatterplot of Soil SOC vs NDVI")
Code
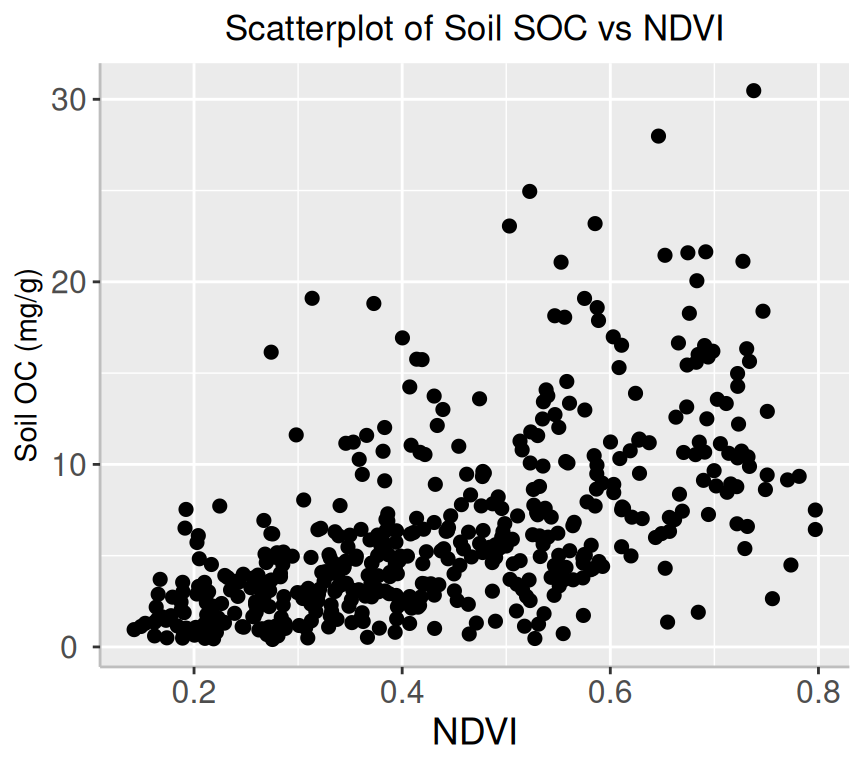
ggplot(mf, aes(x=NDVI, y=SOC)) +geom_point(size=2) +# add plot titleggtitle("Scatterplot of Soil SOC vs NDVI") +theme(# center the plot titleplot.title =element_text(hjust =0.5),axis.line =element_line(colour ="gray"),# axis title font sizeaxis.title.x =element_text(size =14), # X and axis font sizeaxis.text.y=element_text(size=12,vjust =0.5, hjust=0.5),axis.text.x =element_text(size=12))+xlab("NDVI") +ylab("Soil OC (mg/g)")
Code
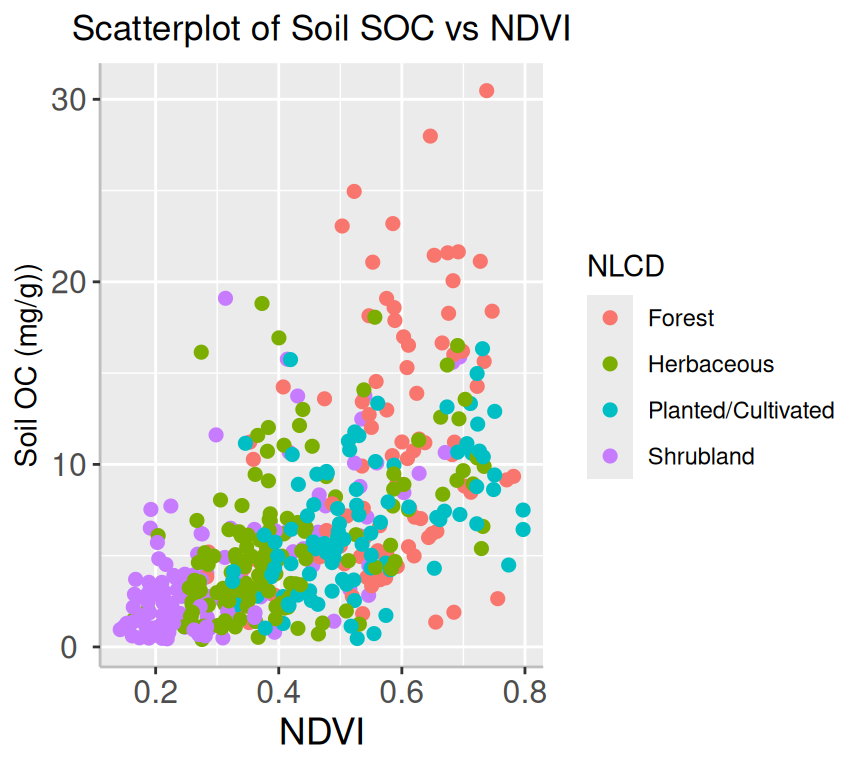
ggplot(mf, aes(x=NDVI, y=SOC, color=NLCD)) +geom_point(size=2) +# add plot titleggtitle("Scatterplot of Soil SOC vs NDVI") +theme(# center the plot titleplot.title =element_text(hjust =0.5),axis.line =element_line(colour ="gray"),# axis title font sizeaxis.title.x =element_text(size =14), # X and axis font sizeaxis.text.y=element_text(size=12,vjust =0.5, hjust=0.5),axis.text.x =element_text(size=12))+# add legend tittleguides(color =guide_legend(title ="NLCD"))+xlab("NDVI") +ylab("Soil OC (mg/g))")
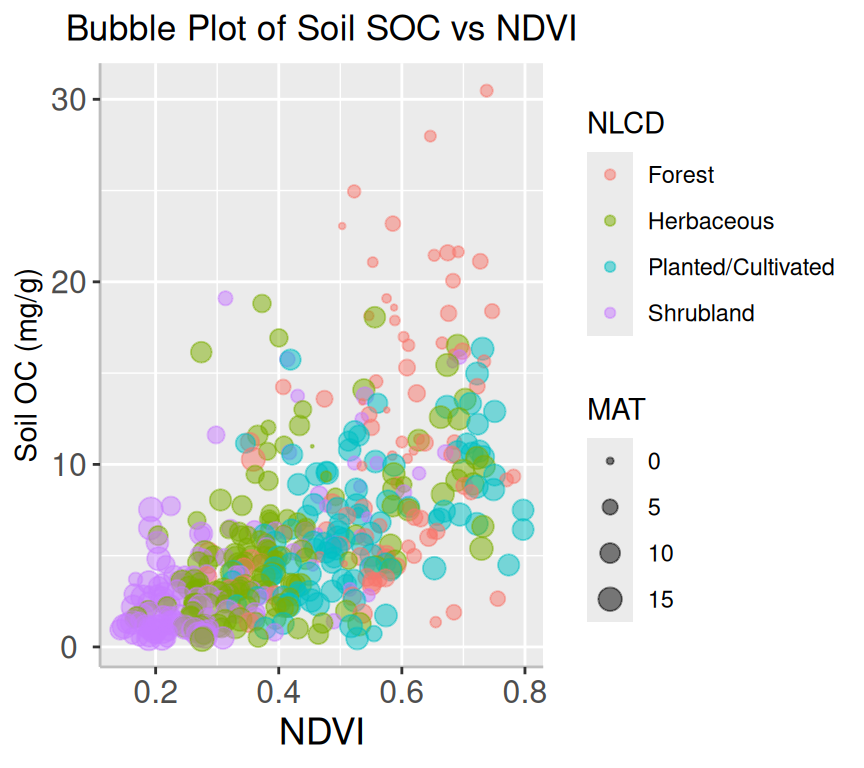
Bubble Plot
A bubble plot is a type of chart that displays data points in a 3-dimensional space using bubbles or spheres. The chart is similar to a scatter plot, but each data point is represented by a bubble with a size proportional to a third variable. Bubble plots are useful for displaying relationships between three variables and can be particularly effective when used to visualize large datasets.
Code
mf |>arrange(desc(SOC)) |>mutate(NLCD =factor(NLCD)) |>ggplot(aes(x=NDVI, y=SOC, size = MAT, color=NLCD)) +geom_point(alpha=0.5) +scale_size(range =c(.2, 4), name="MAT")+guides(color =guide_legend(title ="NLCD"))+ggtitle("Bubble Plot of Soil SOC vs NDVI") +theme(# center the plot titleplot.title =element_text(hjust =0.5),axis.line =element_line(colour ="gray"),# axis title font sizeaxis.title.x =element_text(size =14), # X and axis font sizeaxis.text.y=element_text(size=12,vjust =0.5, hjust=0.5),axis.text.x =element_text(size=12))+# add legend tittleguides(color =guide_legend(title ="NLCD")) +xlab("NDVI") +ylab("Soil OC (mg/g)")
Mariginal Plot
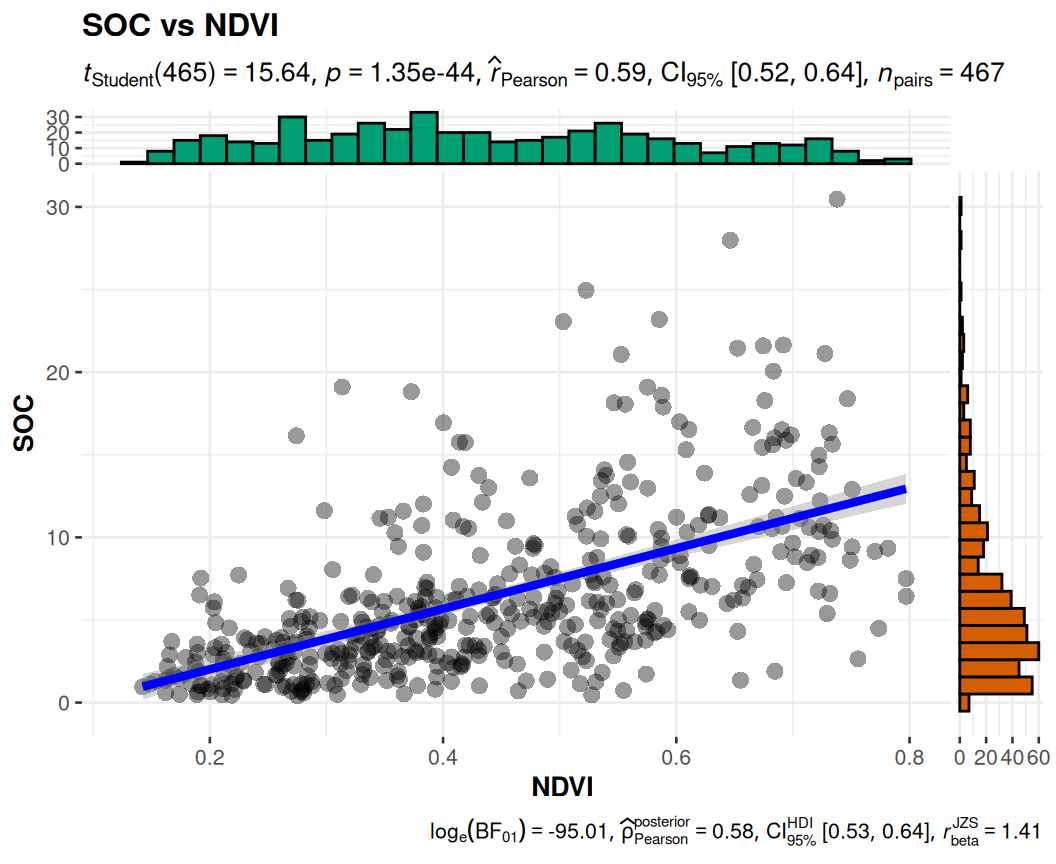
A marginal plot is a type of visualization that displays the distribution of a single variable along the margins of a scatterplot. It is a useful tool for exploring the relationship between two variables and can provide additional insights into the data. We will use ggMarginal() function from ggExtra library makes it create marginal plots
ggscatterstats() function from ggstatsplot will create scatterplots from ggplot2 combined with marginal densigram (density + histogram) plots with statistical details.
install.package(ggstatsplot)
install.package(ggside)
Code
#library(ggstatsplot )ggstatsplot::ggscatterstats(data = mf, x = NDVI, y = SOC,title ="SOC vs NDVI",messages =FALSE)
Correlation Matrix
A correlation matrix is a table that displays the correlation coefficients between different variables.
The rcorr() function of Hmisc package computes a matrix of Pearson’s r or Spearman’s rho rank correlation coefficients for all possible pairs of columns of a matrix.
install.packages(“Hmisc”)
Code
#library(Hmisc)# create a data frame for correlation analysisdf.cor<-mf |> dplyr::select(SOC, DEM, Slope, TPI, NDVI, MAP, MAT) # correlation matrixcor.mat<-Hmisc::rcorr(as.matrix(df.cor, type="pearson"))cor.mat
We can create a correlation matrix table with correlation coefficients (r) and with significat P-values using following function:
Code
# install.packages("xtable")library(xtable)cor_table <-function(x){ require(Hmisc) x <-as.matrix(x) R <-rcorr(x)$r p <-rcorr(x)$P ## define notions for significance levels; spacing is important. mystars <-ifelse(p < .001, "***", ifelse(p < .01, "** ", ifelse(p < .05, "* ", " ")))## trunctuate the matrix that holds the correlations to three decimal R <-format(round(cbind(rep(-1.11, ncol(x)), R), 3))[,-1] ## build a new matrix that includes the correlations with their apropriate stars Rnew <-matrix(paste(R, mystars, sep=""), ncol=ncol(x)) diag(Rnew) <-paste(diag(R), " ", sep="") rownames(Rnew) <-colnames(x) colnames(Rnew) <-paste(colnames(x), "", sep="") ## remove upper triangle Rnew <-as.matrix(Rnew) Rnew[upper.tri(Rnew, diag =TRUE)] <-"" Rnew <-as.data.frame(Rnew) ## remove last column and return the matrix (which is now a data frame) Rnew <-cbind(Rnew[1:length(Rnew)-1])return(Rnew) }
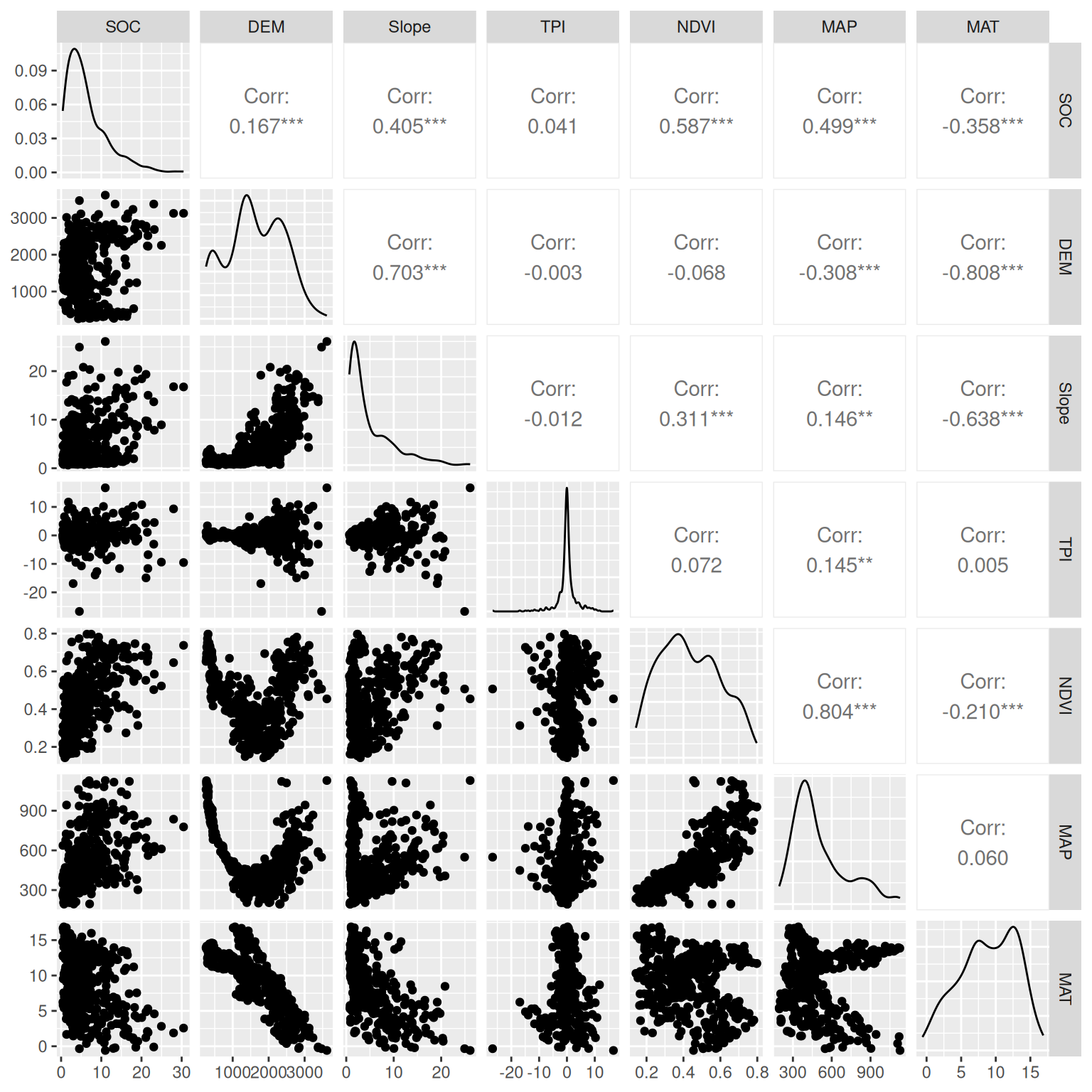
The function ggpairs() from GGally leverages a modular design of pairwise comparisons of multivariate data and displays either the density or count of the respective variable along the diagonal.
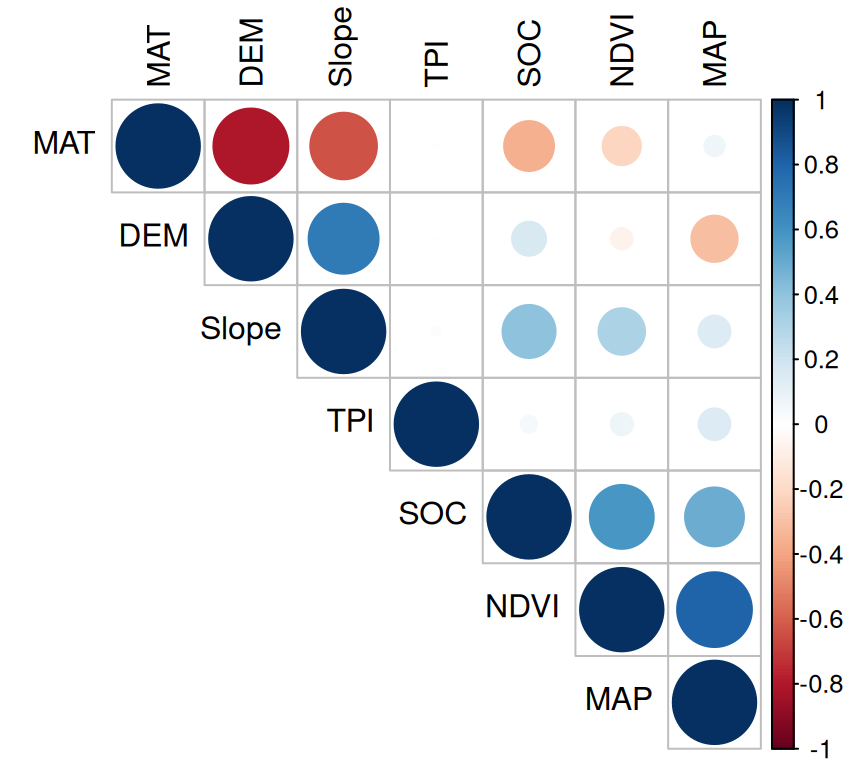
You can create a graphical display of a correlation matrix using the function corrplot() of corrplot package. The function corrplot() takes the correlation matrix as the first argument. The second argument (type=“upper”) is used to display only the upper triangular of the correlation matrix. The correlation matrix is reordered according to the correlation coefficient using “hclust” method.
In above plot, correlation coefficients are colored according to the value. Correlation matrix can be also reordered according to the degree of association between variables. Positive correlations are displayed in blue and negative correlations in red color. Color intensity and the size of the circle are proportional to the correlation coefficients. In the right side of the correlogram, the legend color shows the correlation coefficients and the corresponding colors. The correlations with p-value > 0.05 are considered as insignificant. In this case the correlation coefficient values are leaved blank.
Correlation analysis with rstatix
The ‘rstatix’ package is a user-friendly tool that follows the ‘tidyverse’ design philosophy to perform basic statistical tests, including ‘t-test’, ‘Wilcoxon test’, ‘ANOVA’, ‘Kruskal-Wallis’ and ‘correlation analyses’ with ease. The output of each test is transformed into a tidy data frame for easy visualization. Additional functions are included to help with the analysis of factorial experiments, including purely ‘within-Ss’ designs (repeated measures), purely ‘between-Ss’ designs, and mixed ‘within-and-between-Ss’ designs. The package also provides several effect size metrics, such as ‘eta squared’ for ANOVA, ‘Cohen’s d’ for t-test, and ‘Cramer’s V’ for the association between categorical variables. Additionally, the package includes helper functions to identify univariate and multivariate outliers, assess normality, and homogeneity of variance.
install.pcakges(“rstatix”)
Computing correlation:
cor_test(): correlation test between two or more variables using Pearson, Spearman or Kendall methods.
cor_mat(): compute correlation matrix with p-values. Returns a data frame containing the matrix of the correlation coefficients. The output has an attribute named pvalue which contains the matrix of the correlation test p-values.
cor_get_pval(): extract a correlation matrix p-values from an object of class cor_mat().
cor_pmat(): compute the correlation matrix, but returns only the p-values of the correlation tests.
as_cor_mat(): convert a cor_test object into a correlation matrix format.
Correlation test
cor_test() provides a pipe-friendly framework to perform correlation test between paired samples, using Pearson, Kendall or Spearman method. Wrapper around the function cor.test().
cor_mat(): compute correlation matrix with p-values. Returns a data frame containing the matrix of the correlation coefficients. The output has an attribute named “pvalue”, which contains the matrix of the correlation test p-values.
cor_pmat(): compute the correlation matrix but returns only the p-values of the tests.
cor_get_pval(): extract a correlation matrix p-values from an object of class cor_mat(). P-values are not adjusted
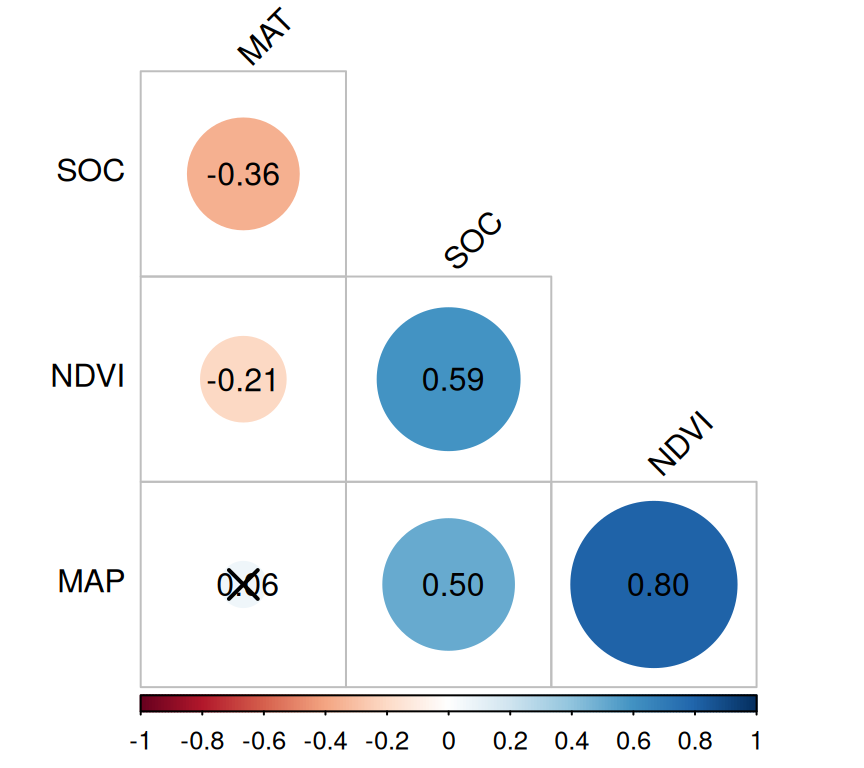
In above plot, insignificant correlations are marked by crosses.
Summary and Conclusion
The tutorial on correlation analysis in R has given you a foundation to explore relationships between variables in a dataset. You can measure the strength and direction of the relationship between two variables using correlation coefficients. With these skills, you can conduct correlation analysis on your datasets and use this foundation to explore more complex statistical techniques.