Rows: 467
Columns: 23
$ ID <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 1…
$ FIPS <dbl> 56041, 56023, 56039, 56039, 56029, 56039, 56039, 56039, 5603…
$ STATE_ID <dbl> 56, 56, 56, 56, 56, 56, 56, 56, 56, 56, 56, 56, 56, 56, 56, …
$ STATE <chr> "Wyoming", "Wyoming", "Wyoming", "Wyoming", "Wyoming", "Wyom…
$ COUNTY <chr> "Uinta County", "Lincoln County", "Teton County", "Teton Cou…
$ Longitude <dbl> -111.0119, -110.9830, -110.8065, -110.7344, -110.7308, -110.…
$ Latitude <dbl> 41.05630, 42.88350, 44.53497, 44.43289, 44.80635, 44.09124, …
$ SOC <dbl> 15.763, 15.883, 18.142, 10.745, 10.479, 16.987, 24.954, 6.28…
$ DEM <dbl> 2229.079, 1889.400, 2423.048, 2484.283, 2396.195, 2360.573, …
$ Aspect <dbl> 159.1877, 156.8786, 168.6124, 198.3536, 201.3215, 208.9732, …
$ Slope <dbl> 5.6716146, 8.9138117, 4.7748051, 7.1218114, 7.9498644, 9.663…
$ TPI <dbl> -0.08572358, 4.55913162, 2.60588670, 5.14693117, 3.75570583,…
$ KFactor <dbl> 0.31999999, 0.26121211, 0.21619999, 0.18166667, 0.12551020, …
$ MAP <dbl> 468.3245, 536.3522, 859.5509, 869.4724, 802.9743, 1121.2744,…
$ MAT <dbl> 4.5951686, 3.8599243, 0.8855000, 0.4707811, 0.7588266, 1.358…
$ NDVI <dbl> 0.4139390, 0.6939532, 0.5466033, 0.6191013, 0.5844722, 0.602…
$ SiltClay <dbl> 64.84270, 72.00455, 57.18700, 54.99166, 51.22857, 45.02000, …
$ NLCD <chr> "Shrubland", "Shrubland", "Forest", "Forest", "Forest", "For…
$ FRG <chr> "Fire Regime Group IV", "Fire Regime Group IV", "Fire Regime…
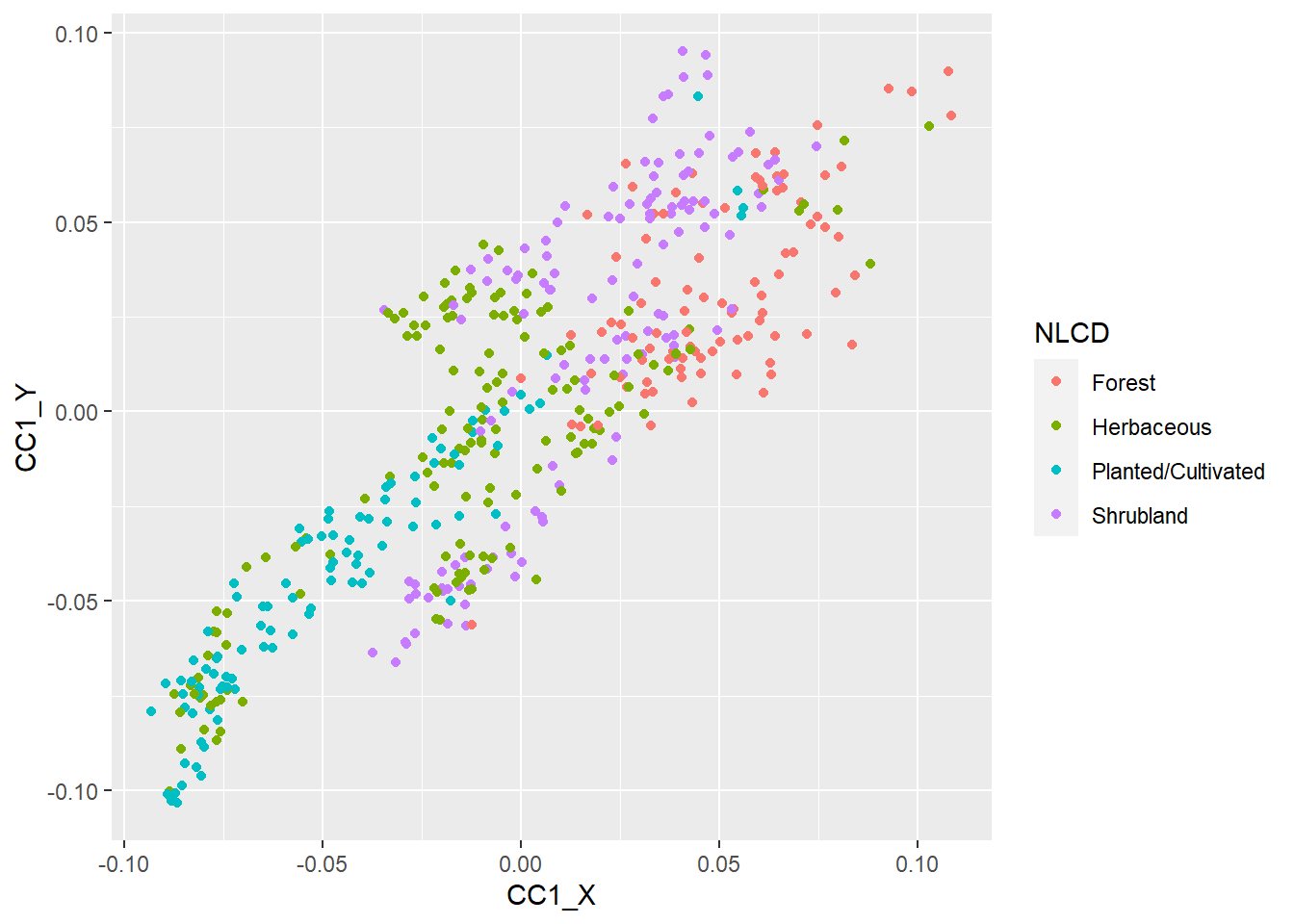
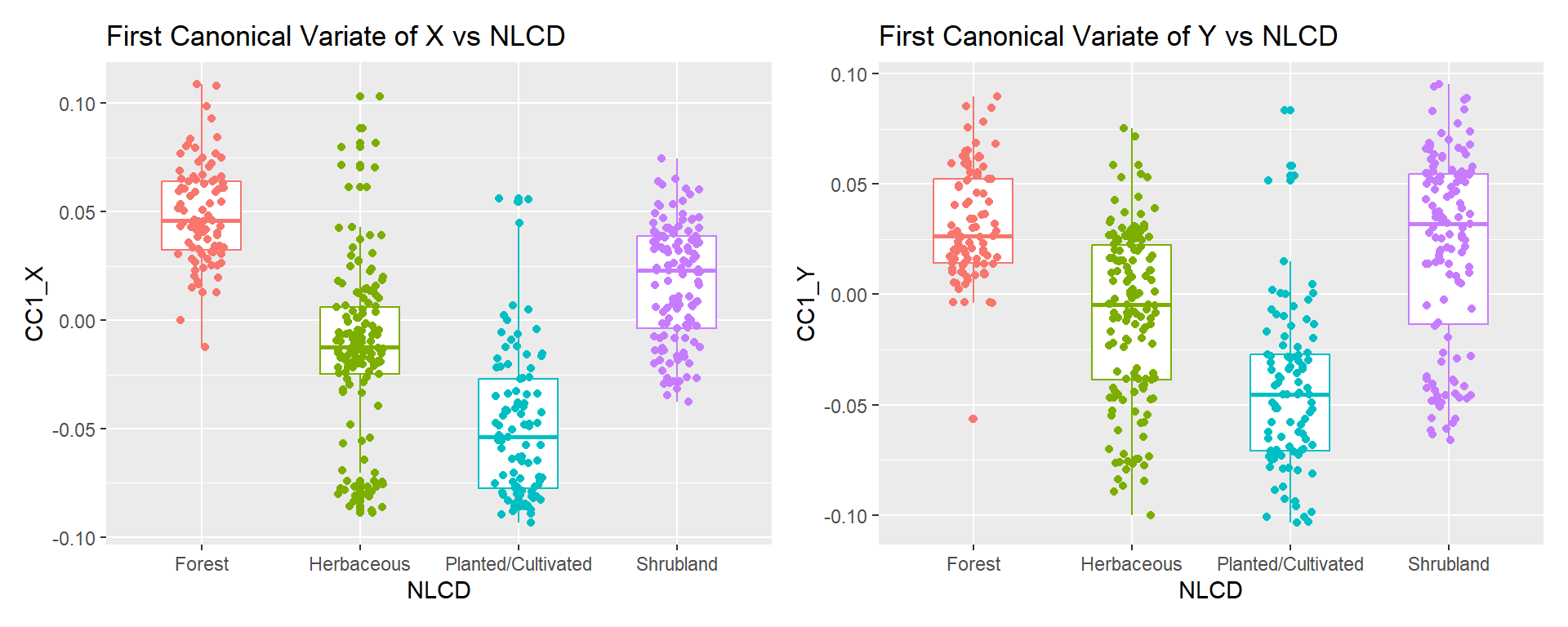
$ CC1_X <dbl[,1]> <matrix[26 x 1]>
$ CC1_Y <dbl[,1]> <matrix[26 x 1]>
$ CC2_X <dbl[,1]> <matrix[26 x 1]>
$ CC2_Y <dbl[,1]> <matrix[26 x 1]>