Introduction to Stack-Ensemble Learning
Stacking, or stack ensemble learning, is a machine learning technique that combines multiple models, called base models or base learners, to make predictions. It is a form of model aggregation that leverages the strengths of different models to improve overall predictive performance.
In stack ensemble learning, the base models are trained on the same dataset, and their individual predictions are combined using another model, called a meta-model or a blender. The meta-model takes the predictions of the base models as input and learns to make the final prediction. The meta-model is typically trained on a separate validation set.
Steps involved in Stack-Ensemble Learning
The process of creating a stack ensemble typically involves the following steps:
Data splitting: The original training dataset is divided into multiple subsets. Typically, a training set and a holdout set (also known as a test set) are created. The training set is used to train the base models, while the holdout set is used to create predictions for the meta-model.
Base model training: Several different base models are trained on the training set. Each base model can be any machine learning algorithm, such as decision trees, random forests, support vector machines, or neural networks. Each base model is trained on a subset of the training data.
Creating the meta-model input: The cross validation predictions from the base models re combined to create a new dataset. Each prediction becomes a new feature in this dataset.
Meta-model training: A meta-model, also known as a blender or aggregator, is trained on the new dataset created in the previous step. The meta-model takes the base model predictions as input and learns to make the final prediction. The meta-model is trained to minimize the prediction error between its output and the true labels of the holdout set.
Prediction: Once the stack ensemble is trained, it can be used to make predictions on new, unseen data. The base models generate predictions on the new data, and these predictions are then fed into the trained meta-model to produce the final prediction.
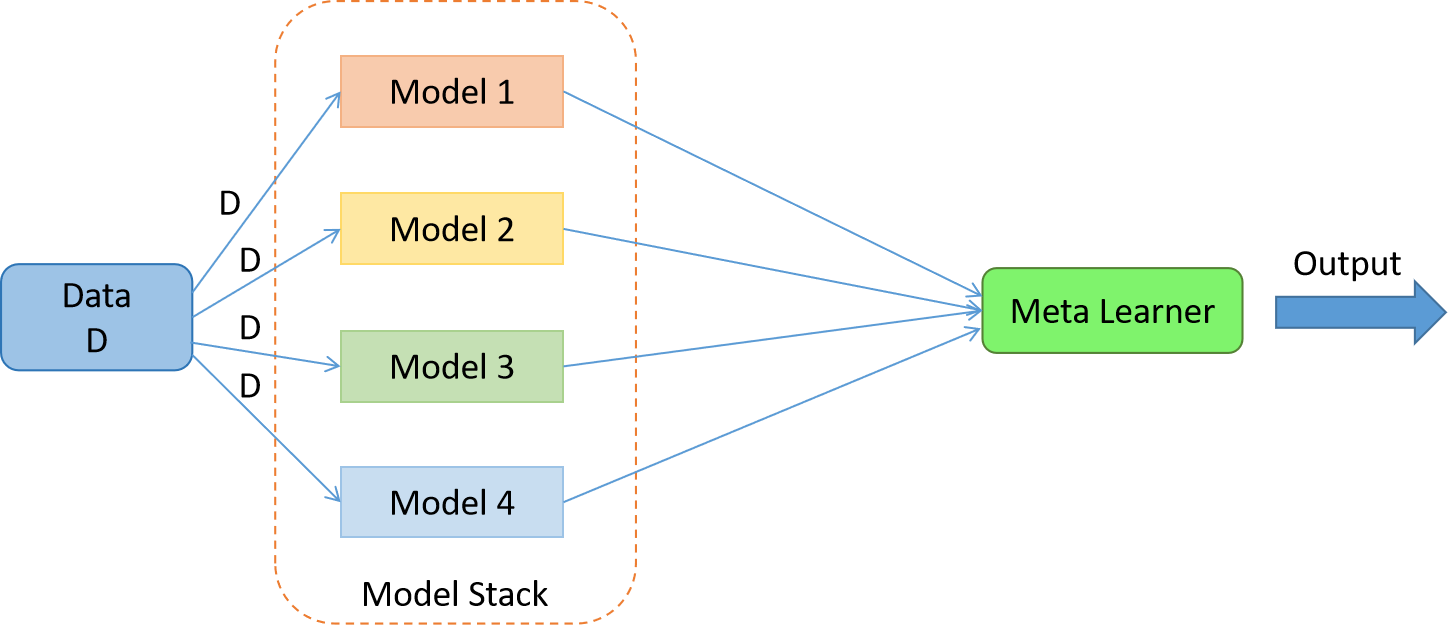
The idea behind stack ensemble learning is that the base models capture different aspects or patterns in the data. By combining their predictions using a meta-model, the stack ensemble can potentially achieve better predictive accuracy than any individual base model.
Stacking can be a powerful technique, but it is important to be cautious about potential overfitting. The meta-model may become too specialized to the training data, leading to poor generalization performance on unseen data. Proper validation and regularization techniques, such as cross-validation and regularization methods like L1 or L2 regularization, can help mitigate overfitting in stack ensemble learning.
Overall, stack ensemble learning is a versatile technique that allows for combining the strengths of multiple models and can potentially lead to improved predictive performance in machine learning tasks.