A generalized linear model (GLM) is a statistical framework that extends the traditional linear regression model to accommodate a broader range of response variables and model assumptions. The GLM allows for the response variable to follow a distribution other than the normal distribution and allows for the relationship between the response variable and the predictor variables to be modeled using a nonlinear function.
The GLM consists of three components:
The random component: specifies the distribution of the response variable (e.g., normal, Poisson, binomial, gamma, etc.). The distribution is chosen based on the nature of the response variable and the model’s assumptions.
The systematic component: specifies the linear predictor function that relates the predictor variables to the response variable. The predictor function is modeled using a combination of linear and nonlinear functions.
The link function: relates the expected value of the response variable to the linear predictor function. The link function can transform the response variable to ensure that it follows the appropriate distribution for the model. For example, in logistic regression, which is used to model binary data, the link function is the logistic function, which maps the linear predictor to a probability between 0 and 1. In Poisson regression, which is used to model count data, the link function is the natural logarithm function, which maps the linear predictor to the mean of the Poisson distribution.
The GLM is a flexible framework that can be used for various statistical applications, including regression analysis, classification, and survival analysis. It allows for the modeling of complex relationships between the response variable and the predictor variables and can accommodate both continuous and discrete response variables.
Linear Regression vs Generalized Linear Models
Linear regression assumes that the response variable is normally distributed, while GLMs allow for different distributions, such as binomial or Poisson.
Linear regression models the mean of the response variable as a linear function of the predictor variables. In contrast, GLMs model the relationship between the predictor variables and the response variable through a link function and a linear combination of the predictor variables.
Linear regression is used for continuous response variables, while GLMs can be used for continuous and categorical response variables.
The assumptions of linear regression are more restrictive than those of GLMs, which makes GLMs more flexible and appropriate for a wider range of data.
The Caret package (short for Classification And REgression Training) is a popular R package for machine learning. It provides a consistent interface to train and evaluate a wide range of machine learning models.The caret package in R provides a unified interface to train and tune machine learning models.
Some of the key features of the Caret package include:
Data Preprocessing: It provides a comprehensive set of tools to preprocess the data, such as missing value imputation, feature scaling, feature selection, and data partitioning.
Model Training: It supports a wide range of machine learning algorithms for classification, regression, and survival analysis, including decision trees, random forests, support vector machines, gradient boosting, and neural networks.
Model Tuning: It provides tools for tuning the hyperparameters of the models using various techniques such as grid search, random search, and Bayesian optimization.
Model Evaluation: It provides tools for evaluating the performance of the models using various metrics such as accuracy, AUC, F1-score, and log-loss.
To train a generalized linear model (GLM) using caret, you can follow these steps:
Create Dummy Variables
dummyVars() creates a full set of dummy variables (i.e. less than full rank parameterization)
The function createDataPartition can be used to create balanced splits of the data
Code
set.seed(3456)#| warning: false#| error: falsetrainIndex <-createDataPartition(dummies.df$SOC, p = .80, list =FALSE, times =1)df_train <- dummies.df[ trainIndex,]df_test <- dummies.df[-trainIndex,]
Code
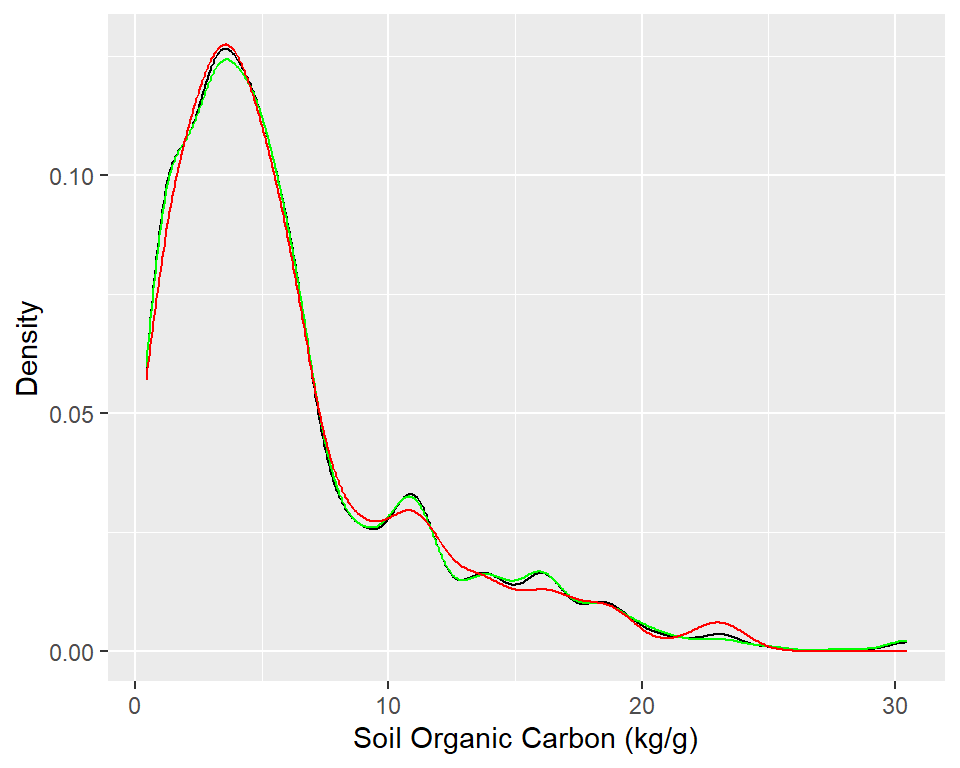
# Density plot all, train and test data ggplot()+geom_density(data = dummies.df, aes(SOC))+geom_density(data = df_train, aes(SOC), color ="green")+geom_density(data = df_test, aes(SOC), color ="red") +xlab("Soil Organic Carbon (kg/g)") +ylab("Density")
Set control prameters
traincontrol() is is used for controlling the training process. It allows us to specify various options related to resampling, cross-validation, and model tuning during the training process.
Code
set.seed(123)train.control <-trainControl(method ="repeatedcv", number =10, repeats =5,preProc =c("center", "scale", "nzv"))
Train the model
train() is used for training machine learning models. It provides a unified interface for a wide range of machine learning algorithms, making it easier to compare and evaluate different models on a given dataset. The train() function takes a formula and a dataset as input, and allows you to specify the type of model to train, as well as various tuning parameters and performance metrics. It uses a resampling method specified by trainControl() to estimate the performance of the model on new, unseen data, and returns a trained model object.
Code
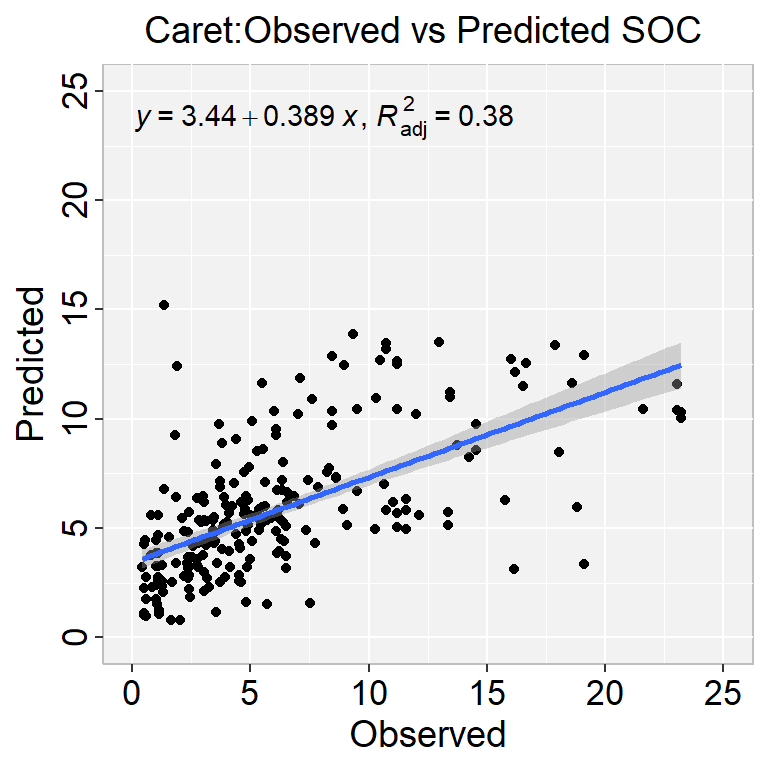
# Train the modelmodel.glm <-train(SOC ~., data = df_train, method ="glm",trControl = train.control)
Summary GLM model
Code
print(model.glm)
Generalized Linear Model
1127 samples
16 predictor
No pre-processing
Resampling: Cross-Validated (10 fold, repeated 5 times)
Summary of sample sizes: 1014, 1015, 1014, 1015, 1014, 1014, ...
Resampling results:
RMSE Rsquared MAE
3.916384 0.4047959 2.821143
Tidymodels is a collection of R packages for modeling and machine learning using a tidyverse approach. The tidyverse is a set of R packages that share a common philosophy of data manipulation and visualization. Tidymodels extends this philosophy to modeling by providing a consistent set of functions for modeling, resampling, and tuning models.
The core packages in tidymodels include:
parsnip: A package for creating a consistent interface to different model types.
dials: A package for tuning model hyperparameters using a tidy interface.
rsample: A package for resampling data to estimate model performance.
recipes: A package for preprocessing data in a tidy way.
infer: A package for statistical inference using tidy data principles.
These packages can be used together or separately to build and evaluate models using a tidy workflow. Tidymodels also integrates with other tidyverse packages like ggplot2 for visualization and purrr for functional programming.
Overall, tidymodels provides a comprehensive framework for building, tuning, and evaluating machine learning models in R while following the principles of the tidyverse.
The steps in most machine learning projects with tidy model are as follows:
Loading necessary packages and data
split data into train and test ({rsample})
light preprocessing ({recipes})
find the best hyperparameters by
creating crossvalidation folds ({rsample})
creating a model specification ({tune, parsnip, treesnip, dials})
creating a grid of values ({dials})
using a workflow to contain the model and formula ({workflows})
tune the model ({tune})
find the best model from tuning
retrain on entire test data
evaluate on test data ({yardstick})
check residuals and model diagnostics
install.packages(“tidymodels”)
Split Data
We use rsample package, install with tidymodels, to split data into training (70%) and test data (30%) set with Stratified Random Sampling. initial_split() creates a single binary split of the data into a training set and testing set.
Note
Stratified random sampling is a technique for selecting a representative sample from a population, where the sample is chosen in a way that ensures that certain subgroups within the population are adequately represented in the sample.
Code
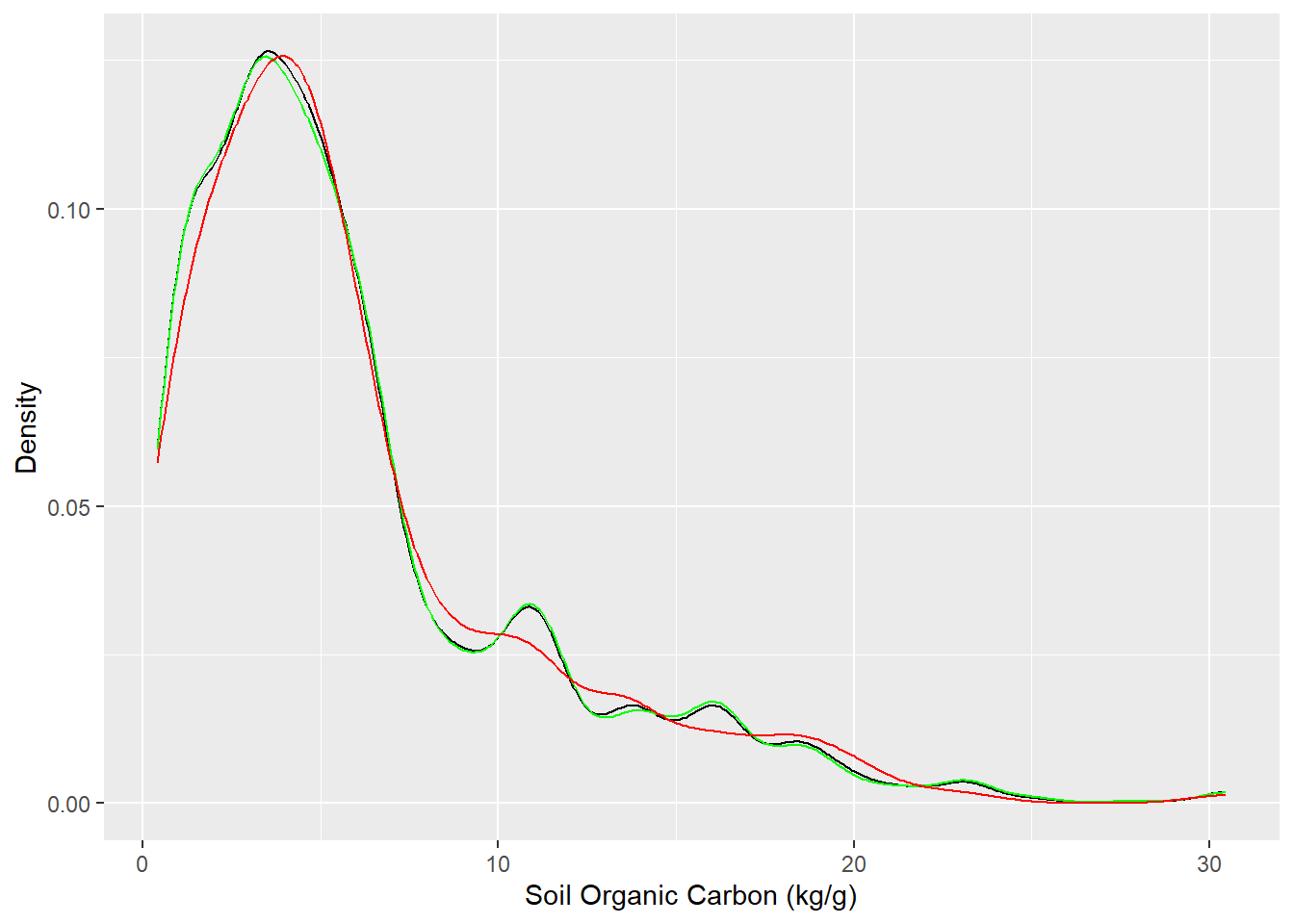
##| fig.width: 4#| fig.height: 4library(tidymodels)set.seed(1245) # for reproducibilitysplit <-initial_split(df, prop =0.8, strata = SOC)train <- split %>%training()test <- split %>%testing()# Density plot all, train and test data ggplot()+geom_density(data = df, aes(SOC))+geom_density(data = train, aes(SOC), color ="green")+geom_density(data = test, aes(SOC), color ="red") +xlab("Soil Organic Carbon (kg/g)") +ylab("Density")
Create Recipe
A recipe is a description of the steps to be applied to a data set in order to prepare it for data analysis. Before training the model, we can use a recipe to do some preprocessing required by the model.
Code
# Create a recipeglm_recipe <-recipe(SOC ~ ., data = train) %>%step_zv(all_predictors()) %>%step_dummy(all_nominal()) %>%step_normalize(all_numeric_predictors())
Build a model
set_engine() is used to specify which package or system will be used to fit the model, along with any arguments specific to that software. We will use “glm” without any regularization parameters
Code
glm_mod <-linear_reg() %>%set_engine("glm")
Creatae a workflow
A workflow is a container object that aggregates information required to fit and predict from a model. This information might be a recipe used in preprocessing, specified through add_recipe(), or the model specification to fit, specified through add_model().
Now, there is a single function that can be used to prepare the recipe and train the model from the resulting predictors:
Code
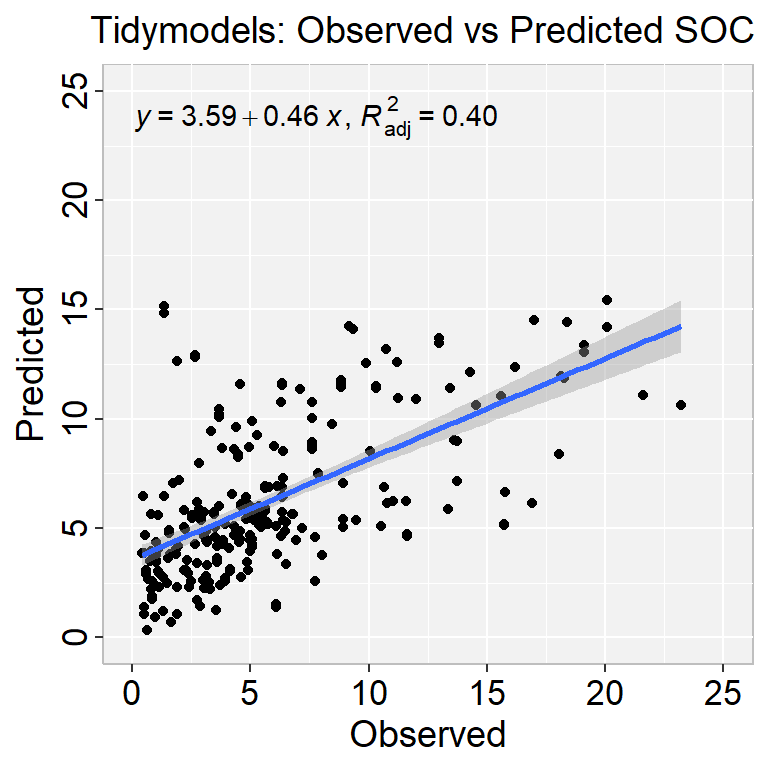
glm_fit <- glm_wflow %>%fit(data = train)
This object has the finalized recipe and fitted model objects inside. You may want to extract the model or recipe objects from the workflow. To do this, you can use the helper functions extract_fit_parsnip():
The H2O package is an open-source software for data analysis and machine learning. It is designed to be fast, scalable, and easy to use. The package can be used in R, Python, and other programming languages, and it provides a variety of machine learning algorithms, including deep learning, gradient boosting, generalized linear models, and others.
H2O is particularly well-suited for large datasets and can run on a single machine or a distributed cluster. It also offers automated machine learning (AutoML) capabilities, which can help users select the best algorithm and hyperparameters for their data.
Some of the key features of the H2O package include:
Distributed computing: H2O can run on a cluster of machines and scale up to handle very large datasets. GPU acceleration: H2O supports GPU acceleration for certain algorithms, which can significantly speed up computation.
Automated machine learning: H2O’s AutoML feature can automatically select the best algorithm and hyperparameters for a given dataset.
Interpretable machine learning: H2O provides tools for interpreting machine learning models and understanding their predictions.
Integration with popular programming languages: H2O can be used with R, Python, and other programming languages, making it accessible to a wide range of users.
The h2o package provides an open-source implementation of GLM that is specifically designed for big data. To use the GLM function in h2o, you will need to first install and load the package in your R environment. Once the package is loaded, you can use the h2o.glm() function to fit a GLM model.
Downloading & Installing H2O
Detail instruction of downloading & installing H2O in R could be found here
Anyway, perform the following steps in R to install H2O. Copy and paste these commands one line at a time.
The following two commands remove any previously installed H2O packages for R.
if (“package:h2o” %in% search()) { detach(“package:h2o”, unload=TRUE) }
if (“h2o” %in% rownames(installed.packages())) { remove.packages(“h2o”) }
Next, download packages that H2O depends on
pkgs <- c(“RCurl”,“jsonlite”)
for (pkg in pkgs) { if (! (pkg %in% rownames(installed.packages()))) { install.packages(pkg) } }
H2O is not running yet, starting it now...
Note: In case of errors look at the following log files:
C:\Users\zahmed2\AppData\Local\Temp\1\RtmpcBMmjK\file91942400b18/h2o_zahmed2_started_from_r.out
C:\Users\zahmed2\AppData\Local\Temp\1\RtmpcBMmjK\file91947d42847/h2o_zahmed2_started_from_r.err
Starting H2O JVM and connecting: Connection successful!
R is connected to the H2O cluster:
H2O cluster uptime: 3 seconds 107 milliseconds
H2O cluster timezone: America/New_York
H2O data parsing timezone: UTC
H2O cluster version: 3.40.0.4
H2O cluster version age: 3 months and 23 days
H2O cluster name: H2O_started_from_R_zahmed2_yqz807
H2O cluster total nodes: 1
H2O cluster total memory: 148.00 GB
H2O cluster total cores: 40
H2O cluster allowed cores: 40
H2O cluster healthy: TRUE
H2O Connection ip: localhost
H2O Connection port: 54321
H2O Connection proxy: NA
H2O Internal Security: FALSE
R Version: R version 4.3.1 (2023-06-16 ucrt)
Code
#disable progress bar for RMarkdownh2o.no_progress() # Optional: remove anything from previous sessionh2o.removeAll()
glm_h2o <-h2o.glm( ## h2o.glm functiontraining_frame = h_train, ## the H2O frame for training# validation_frame = valid, ## the H2O frame for validation (not required)x=x, ## the predictor columns, by column indexy=y, ## the target index (what we are predicting)model_id ="GLM_MODEL_ID", ## name the model in H2O## not required, but helps use Flowfamily ="gaussian", ## Family. Use binomial for classification with ## logistic regression, others are for regression problems. ## Must be one of: "AUTO", "gaussian", "binomial", ## "fractionalbinomial", "quasibinomial", "ordinal",## "multinomial", "poisson", "gamma", "tweedie", ## "negativebinomial". ## Defaults to AUTOcompute_p_values =TRUE, ## Logical. Request p-values computation, p-values ## work only with IRLSM solver and no regularization ## Defaults to FALSE.nfolds =10, ## umber of folds for K-fold cross-validation ## (0 to disable or >= 2). ## Defaults to 0.keep_cross_validation_models =TRUE, ## logical. Whether to keep the cross-validation models. ## Defaults to TRUE.early_stopping =TRUE, ## Logical. Stop early when there is no more relative ## improvement on train or validation (if provided) ## Defaults to TRUE.stopping_rounds =2, ## Early stopping based on convergence of stopping_metric. ## Stop if simple moving average of length k ## of the stopping_metric does not improve for ## k:=stopping_rounds scoring events (0 to disable) ## Defaults to 0.stopping_metric ="RMSE", ## Metric to use for early stoppingremove_collinear_columns =TRUE, ## Logical. In case of linearly dependent columns, ## remove some of the dependent columns Defaults to FALSE.standardize =TRUE, ## Logical. Standardize numeric columns to have zero mean ## and unit variance ## Defaults to TRUE.seed =212) ## Set the random seed so that this can be## reproduced.
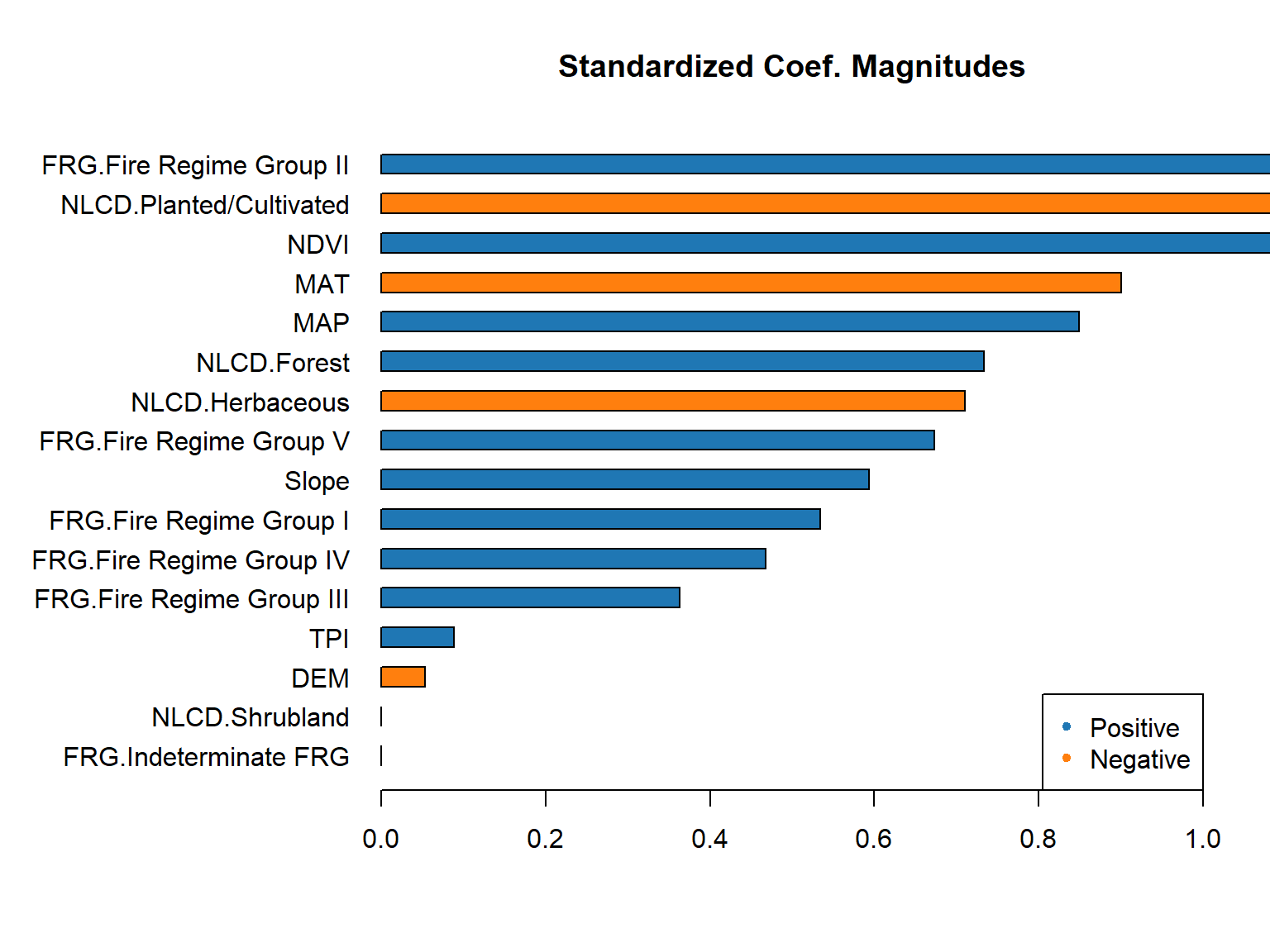
Coefficients table
Code
glm_h2o@model$coefficients_table
Coefficients: glm coefficients
names coefficients std_error z_value p_value
1 Intercept -0.365883 1.765136 -0.207283 0.835827
2 FRG.Fire Regime Group I 0.534452 1.447050 0.369339 0.711946
3 FRG.Fire Regime Group II 1.759501 1.340118 1.312944 0.189473
4 FRG.Fire Regime Group III 0.362598 1.349955 0.268600 0.788287
5 FRG.Fire Regime Group IV 0.467249 1.350144 0.346073 0.729353
6 FRG.Fire Regime Group V 0.673536 1.453193 0.463487 0.643106
7 FRG.Indeterminate FRG 0.000000 NA NA NA
8 NLCD.Forest 0.733379 0.506133 1.448984 0.147624
9 NLCD.Herbaceous -0.710060 0.401525 -1.768410 0.077267
10 NLCD.Planted/Cultivated -1.562316 0.546477 -2.858888 0.004331
11 NLCD.Shrubland 0.000000 NA NA NA
12 DEM -0.000081 0.000447 -0.180596 0.856718
13 Slope 0.115020 0.038255 3.006650 0.002701
14 TPI 0.021961 0.030608 0.717486 0.473225
15 MAT -0.219361 0.054107 -4.054240 0.000054
16 MAP 0.005763 0.001260 4.573012 0.000005
17 NDVI 10.884941 1.562274 6.967369 0.000000
standardized_coefficients
1 5.256297
2 0.534452
3 1.759501
4 0.362598
5 0.467249
6 0.673536
7 0.000000
8 0.733379
9 -0.710060
10 -1.562316
11 0.000000
12 -0.053244
13 0.593587
14 0.088585
15 -0.900295
16 0.849533
17 1.561699
Retrieve a graphical plot of the standardized coefficient magnitudes
Code
h2o.std_coef_plot(glm_h2o)
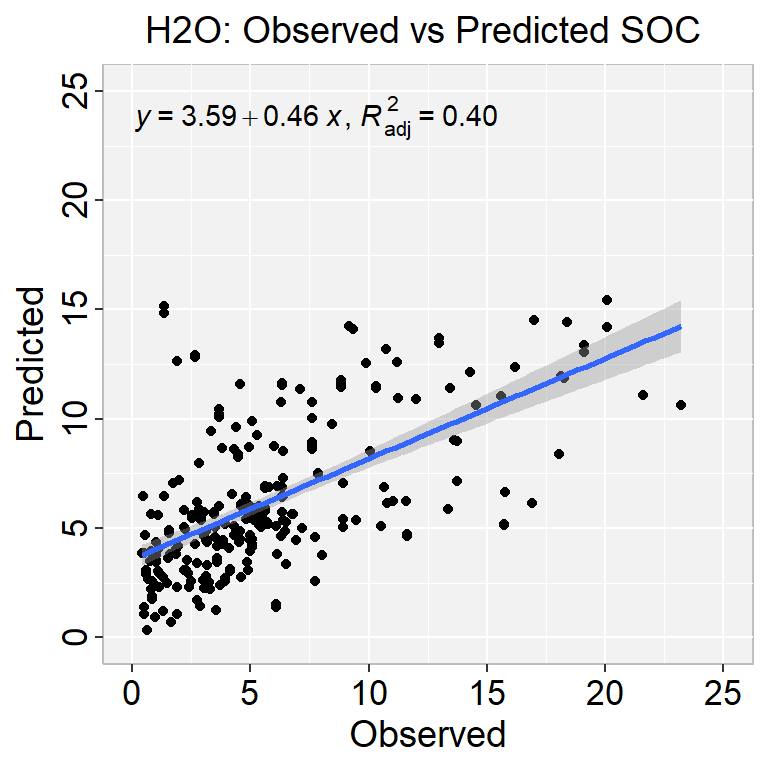
Model Performance
Code
# training performanceh2o.performance(glm_h2o, h_train)
Google Colab is a cloud-based platform provided by Google for running and executing Python code. It is built on top of Jupyter Notebook and offers a free, convenient, and collaborative environment for data analysis, machine learning, and general-purpose Python programming. Colab allows you to create and share Jupyter notebooks that include code, text, images, and visualizations.
Key features of Google Colab include:
Free GPU and TPU Support: Colab provides free access to a limited amount of GPU (Graphics Processing Unit) and TPU (Tensor Processing Unit) resources, which can significantly accelerate deep learning computations.
Collaborative Editing: Multiple users can collaborate in real-time on the same Colab notebook, making it useful for team projects or sharing knowledge.
Google Drive Integration: You can easily save and load files to and from your Google Drive, enabling seamless data storage and retrieval.
Rich Text and Media Support: Colab notebooks support rich media integration, allowing you to include images, videos, and other multimedia elements in your notebooks.
Pre-installed Libraries: Many popular Python libraries for data analysis, machine learning, and deep learning (e.g., NumPy, Pandas, TensorFlow, PyTorch) come pre-installed on Colab, reducing setup time.
Easy Sharing: Colab notebooks can be easily shared with others by generating a shareable link. It’s a convenient way to showcase your work or collaborate with others.
To get started with Google Colab, you can visit the official website at https://colab.research.google.com/. You can either create a new notebook or open an existing one from your Google Drive. The notebooks run on virtual machines hosted by Google, and once you close the browser, the virtual machine and its contents are discarded, but your notebook will be automatically saved to your Google Drive.
Keep in mind that the available resources, such as GPU and TPU quotas, may be limited for free users. Also, the specific features and limitations of Google Colab may evolve over time, so it’s always a good idea to check the official website or documentation for the latest information.
Although Google Colab is primarily designed for Python, it also supports R. You can run R code in a Colab notebook by creating an R runtime environment. Here’s how you can set it up:
Open Google Colab in your web browser at https://colab.research.google.com/.
Click on the “File” menu and select “New notebook” to create a new notebook.
In the toolbar, click on the “Runtime” menu and select “Change runtime type.”
In the dialog box that appears, select “R” from the “Runtime type” dropdown.
Click on the “Save” button to apply the changes.
Once you have set up the R runtime environment, you can start writing and executing R code in the notebook cells. To run a code cell, press Shift+Enter or click on the “Play” button next to the cell.
You can install R packages in Colab by using the install.packages() function.
Exercise
Create a R-Markdown document (name homework_11.rmd) in this project and do all Tasks using the data shown below.
Submit all codes and output as a HTML document (homework_11.html) before class of next week.
[{fig-align="right" width="176" height="64"}](https://github.com/zia207/r-colab/blob/main/generalized_linear_models.ipynb)# Generalized Linear Models {.unnumbered}A generalized linear model (GLM) is a statistical framework that extends the traditional linear regression model to accommodate a broader range of response variables and model assumptions. The GLM allows for the response variable to follow a distribution other than the normal distribution and allows for the relationship between the response variable and the predictor variables to be modeled using a nonlinear function.The GLM consists of three components:1. The random component: specifies the distribution of the response variable (e.g., normal, Poisson, binomial, gamma, etc.). The distribution is chosen based on the nature of the response variable and the model's assumptions.2. The systematic component: specifies the linear predictor function that relates the predictor variables to the response variable. The predictor function is modeled using a combination of linear and nonlinear functions.3. The link function: relates the expected value of the response variable to the linear predictor function. The link function can transform the response variable to ensure that it follows the appropriate distribution for the model. For example, in logistic regression, which is used to model binary data, the link function is the logistic function, which maps the linear predictor to a probability between 0 and 1. In Poisson regression, which is used to model count data, the link function is the natural logarithm function, which maps the linear predictor to the mean of the Poisson distribution.The GLM is a flexible framework that can be used for various statistical applications, including regression analysis, classification, and survival analysis. It allows for the modeling of complex relationships between the response variable and the predictor variables and can accommodate both continuous and discrete response variables.### Linear Regression vs Generalized Linear Models1. Linear regression assumes that the response variable is normally distributed, while GLMs allow for different distributions, such as binomial or Poisson.2. Linear regression models the mean of the response variable as a linear function of the predictor variables. In contrast, GLMs model the relationship between the predictor variables and the response variable through a link function and a linear combination of the predictor variables.3. Linear regression is used for continuous response variables, while GLMs can be used for continuous and categorical response variables.4. The assumptions of linear regression are more restrictive than those of GLMs, which makes GLMs more flexible and appropriate for a wider range of data.This exercise will fit GLM with the following:1. [GLM with Caret Package](#glm-with-caret-package)2. [GLM with tidymodel](#glm-with-tidymodel)3. [GLM-with-h2o](#glm-with-h2o)4. Run all three in Google Colab.### DataIn this exercise, we will use following data set.[gp_soil_data_syn.csv](https://www.dropbox.com/s/9ikm5yct36oflei/gp_soil_data.csv?dl=0).```{r}#| warning: false#| error: false# load tidyverselibrary(tidyverse)# define data folderurlfile ="https://github.com//zia207/r-colab/raw/main/Data/USA/gp_soil_data_syn.csv"mf<-read_csv(url(urlfile))# Create a data-framedf<-mf %>% dplyr::select(SOC, DEM, Slope, TPI,MAT, MAP,NDVI, NLCD, FRG)%>%glimpse()```## GLM with Caret Package {#glm-with-caret-package}{width="194"}The Caret package (short for Classification And REgression Training) is a popular R package for machine learning. It provides a consistent interface to train and evaluate a wide range of machine learning models.The caret package in R provides a unified interface to train and tune machine learning models.Some of the key features of the Caret package include:1. Data Preprocessing: It provides a comprehensive set of tools to preprocess the data, such as missing value imputation, feature scaling, feature selection, and data partitioning.2. Model Training: It supports a wide range of machine learning algorithms for classification, regression, and survival analysis, including decision trees, random forests, support vector machines, gradient boosting, and neural networks.3. Model Tuning: It provides tools for tuning the hyperparameters of the models using various techniques such as grid search, random search, and Bayesian optimization.4. Model Evaluation: It provides tools for evaluating the performance of the models using various metrics such as accuracy, AUC, F1-score, and log-loss.To train a generalized linear model (GLM) using caret, you can follow these steps:### Create Dummy VariablesdummyVars() creates a full set of dummy variables (i.e. less than full rank parameterization)```{r}#| warning: false#| error: false# load caretlibrary(caret)dummies <-dummyVars(SOC ~ ., data = df)dummies.df<-as.data.frame(predict(dummies, newdata = df))dummies.df$SOC<-df$SOC```### Data SplittingThe function createDataPartition can be used to create balanced splits of the data```{r}set.seed(3456)#| warning: false#| error: falsetrainIndex <-createDataPartition(dummies.df$SOC, p = .80, list =FALSE, times =1)df_train <- dummies.df[ trainIndex,]df_test <- dummies.df[-trainIndex,]``````{r}#| warning: false#| error: false#| fig.width: 5#| fig.height: 4# Density plot all, train and test data ggplot()+geom_density(data = dummies.df, aes(SOC))+geom_density(data = df_train, aes(SOC), color ="green")+geom_density(data = df_test, aes(SOC), color ="red") +xlab("Soil Organic Carbon (kg/g)") +ylab("Density") ```### Set control prameterstraincontrol() is is used for controlling the training process. It allows us to specify various options related to resampling, cross-validation, and model tuning during the training process.```{r }#| warning: false#| error: falseset.seed(123)train.control <-trainControl(method ="repeatedcv", number =10, repeats =5,preProc =c("center", "scale", "nzv"))```### Train the modeltrain() is used for training machine learning models. It provides a unified interface for a wide range of machine learning algorithms, making it easier to compare and evaluate different models on a given dataset. The train() function takes a formula and a dataset as input, and allows you to specify the type of model to train, as well as various tuning parameters and performance metrics. It uses a resampling method specified by trainControl() to estimate the performance of the model on new, unseen data, and returns a trained model object.```{r }#| warning: false#| error: false# Train the modelmodel.glm <-train(SOC ~., data = df_train, method ="glm",trControl = train.control)```### Summary GLM model```{r }#| warning: false#| error: falseprint(model.glm)```### Training Performance```{r}#| warning: false#| error: falsegetTrainPerf(model.glm)```### Prediction```{r}#| warning: false#| error: falsedf_test$Pred.SOC =predict(model.glm, df_test)```### Prediction Performance```{r}#| warning: false#| error: falselibrary(Metrics)RMSE<- Metrics::rmse(df_test$SOC, df_test$Pred.SOC)MAE<- Metrics::mae(df_test$SOC, df_test$Pred.SOC)MSE<- Metrics::mse(df_test$SOC, df_test$Pred.SOC)MDAE<- Metrics::mdae(df_test$SOC, df_test$Pred.SOC)# Print resultspaste0("RMSE: ", round(RMSE,2))paste0("MAE: ", round(MAE,2))paste0("MSE: ", round(MSE,2))paste0("MDAE: ", round(MDAE,2))```We can plot observed and predicted values with fitted regression line with ggplot2```{r}#| warning: false#| error: false#| fig.width: 4#| fig.height: 4library(ggpmisc)formula<-y~xggplot(df_test, aes(SOC,Pred.SOC)) +geom_point() +geom_smooth(method ="lm")+stat_poly_eq(use_label(c("eq", "adj.R2")), formula = formula) +ggtitle("Caret:Observed vs Predicted SOC ") +xlab("Observed") +ylab("Predicted") +scale_x_continuous(limits=c(0,25), breaks=seq(0, 25, 5))+scale_y_continuous(limits=c(0,25), breaks=seq(0, 25, 5)) +# Flip the barstheme(panel.background =element_rect(fill ="grey95",colour ="gray75",size =0.5, linetype ="solid"),axis.line =element_line(colour ="grey"),plot.title =element_text(size =14, hjust =0.5),axis.title.x =element_text(size =14),axis.title.y =element_text(size =14),axis.text.x=element_text(size=13, colour="black"),axis.text.y=element_text(size=13,angle =90,vjust =0.5, hjust=0.5, colour='black'))```## GLM with tidymodels{width="193"}Tidymodels is a collection of R packages for modeling and machine learning using a tidyverse approach. The tidyverse is a set of R packages that share a common philosophy of data manipulation and visualization. Tidymodels extends this philosophy to modeling by providing a consistent set of functions for modeling, resampling, and tuning models.The core packages in tidymodels include:**parsnip**: A package for creating a consistent interface to different model types.**dials**: A package for tuning model hyperparameters using a tidy interface.**rsample**: A package for resampling data to estimate model performance.**recipes**: A package for preprocessing data in a tidy way.**infer**: A package for statistical inference using tidy data principles.These packages can be used together or separately to build and evaluate models using a tidy workflow. Tidymodels also integrates with other tidyverse packages like ggplot2 for visualization and purrr for functional programming.Overall, tidymodels provides a comprehensive framework for building, tuning, and evaluating machine learning models in R while following the principles of the tidyverse.The steps in most machine learning projects with tidy model are as follows:- Loading necessary packages and data- split data into train and test ({rsample})- light preprocessing ({recipes})- find the best hyperparameters by - creating crossvalidation folds ({rsample}) - creating a model specification ({tune, parsnip, treesnip, dials}) - creating a grid of values ({dials}) - using a workflow to contain the model and formula ({workflows}) - tune the model ({tune}) - find the best model from tuning- retrain on entire test data- evaluate on test data ({yardstick})- check residuals and model diagnostics> install.packages("tidymodels")### Split DataWe use **rsample** package, install with **tidymodels**, to split data into training (70%) and test data (30%) set with Stratified Random Sampling. initial_split() creates a single binary split of the data into a training set and testing set.::: callout-noteStratified random sampling is a technique for selecting a representative sample from a population, where the sample is chosen in a way that ensures that certain subgroups within the population are adequately represented in the sample.:::```{r }#| warning: false#| error: false##| fig.width: 4#| fig.height: 4library(tidymodels)set.seed(1245) # for reproducibilitysplit <-initial_split(df, prop =0.8, strata = SOC)train <- split %>%training()test <- split %>%testing()# Density plot all, train and test data ggplot()+geom_density(data = df, aes(SOC))+geom_density(data = train, aes(SOC), color ="green")+geom_density(data = test, aes(SOC), color ="red") +xlab("Soil Organic Carbon (kg/g)") +ylab("Density") ```### Create RecipeA recipe is a description of the steps to be applied to a data set in order to prepare it for data analysis. Before training the model, we can use a recipe to do some preprocessing required by the model.```{r}#| warning: false#| error: false# Create a recipeglm_recipe <-recipe(SOC ~ ., data = train) %>%step_zv(all_predictors()) %>%step_dummy(all_nominal()) %>%step_normalize(all_numeric_predictors())```### Build a modelset_engine() is used to specify which package or system will be used to fit the model, along with any arguments specific to that software. We will use "glm" without any regularization parameters```{r}glm_mod <-linear_reg() %>%set_engine("glm")```### Creatae a workflowA workflow is a container object that aggregates information required to fit and predict from a model. This information might be a recipe used in preprocessing, specified through add_recipe(), or the model specification to fit, specified through add_model().```{r}glm_wflow <-workflow() %>%add_model(glm_mod) %>%add_recipe(glm_recipe)```### Fit GLM modelNow, there is a single function that can be used to prepare the recipe and train the model from the resulting predictors:```{r}glm_fit <- glm_wflow %>%fit(data = train)```This object has the finalized recipe and fitted model objects inside. You may want to extract the model or recipe objects from the workflow. To do this, you can use the helper functions extract_fit_parsnip():```{r}glm_fit %>%extract_fit_parsnip() %>%tidy()```### Prediction```{r}test_df<-as.data.frame(test)test_df$GLM.SOC<-predict(glm_fit, new_data = test)head(test_df) ``````{r}#| warning: false#| error: falselibrary(Metrics)GLM.RMSE<- Metrics::rmse(test_df$SOC, test_df$GLM.SOC$.pred)GLM.MAE<- Metrics::mae(test_df$SOC, test_df$GLM.SOC$.pred)GLM.MSE<- Metrics::mse(test_df$SOC, test_df$GLM.SOC$.pred)GLM.MDAE<- Metrics::mdae(test_df$SOC, test_df$GLM.SOC$.pred)# Print resultspaste0("GLM.RMSE: ", round(GLM.RMSE,2))paste0("GLM.MAE: ", round(GLM.MAE,2))paste0("GLM.MSE: ", round(GLM.MSE,2))paste0("GLM. MDAE: ", round(GLM.MDAE,2))```We can plot observed and predicted values with fitted regression line with ggplot2```{r}#| warning: false#| error: false#| fig.width: 4#| fig.height: 4library(ggpmisc)formula<-y~xggplot(test_df, aes(SOC,GLM.SOC$.pred)) +geom_point() +geom_smooth(method ="lm")+stat_poly_eq(use_label(c("eq", "adj.R2")), formula = formula) +ggtitle("Tidymodels: Observed vs Predicted SOC ") +xlab("Observed") +ylab("Predicted") +scale_x_continuous(limits=c(0,25), breaks=seq(0, 25, 5))+scale_y_continuous(limits=c(0,25), breaks=seq(0, 25, 5)) +# Flip the barstheme(panel.background =element_rect(fill ="grey95",colour ="gray75",size =0.5, linetype ="solid"),axis.line =element_line(colour ="grey"),plot.title =element_text(size =14, hjust =0.5),axis.title.x =element_text(size =14),axis.title.y =element_text(size =14),axis.text.x=element_text(size=13, colour="black"),axis.text.y=element_text(size=13,angle =90,vjust =0.5, hjust=0.5, colour='black'))```## GLM with h20{width="271"}The H2O package is an open-source software for data analysis and machine learning. It is designed to be fast, scalable, and easy to use. The package can be used in R, Python, and other programming languages, and it provides a variety of machine learning algorithms, including deep learning, gradient boosting, generalized linear models, and others.H2O is particularly well-suited for large datasets and can run on a single machine or a distributed cluster. It also offers automated machine learning (AutoML) capabilities, which can help users select the best algorithm and hyperparameters for their data.Some of the key features of the H2O package include:1. Distributed computing: H2O can run on a cluster of machines and scale up to handle very large datasets. GPU acceleration: H2O supports GPU acceleration for certain algorithms, which can significantly speed up computation.2. Automated machine learning: H2O's AutoML feature can automatically select the best algorithm and hyperparameters for a given dataset.3. Interpretable machine learning: H2O provides tools for interpreting machine learning models and understanding their predictions.4. Integration with popular programming languages: H2O can be used with R, Python, and other programming languages, making it accessible to a wide range of users.The h2o package provides an open-source implementation of GLM that is specifically designed for big data. To use the GLM function in h2o, you will need to first install and load the package in your R environment. Once the package is loaded, you can use the h2o.glm() function to fit a GLM model.### Downloading & Installing H2ODetail instruction of downloading & installing H2O in R could be found [here](https://docs.h2o.ai/h2o/latest-stable/h2o-docs/downloading.html)Anyway, perform the following steps in R to install H2O. Copy and paste these commands one line at a time.1. The following two commands remove any previously installed H2O packages for R.> if ("package:h2o" %in% search()) { detach("package:h2o", unload=TRUE) }> if ("h2o" %in% rownames(installed.packages())) { remove.packages("h2o") }2. Next, download packages that H2O depends on> pkgs \<- c("RCurl","jsonlite")> for (pkg in pkgs) { if (! (pkg %in% rownames(installed.packages()))) { install.packages(pkg) } }3. Download and install the H2O package for R.> install.packages("h2o", type="source", repos=(c("http://h2o-release.s3.amazonaws.com/h2o/latest_stable_R")))### Convert to factor```{r}#| warning: false#| error: falsedf$NLCD <-as.factor(df$NLCD)df$FRG <-as.factor(df$FRG)```### Data split```{r}#| warning: false#| error: falselibrary(tidymodels)set.seed(1245) # for reproducibilitysplit.df <-initial_split(df, prop =0.8, strata = SOC)train.df <- split.df %>%training()test.df <- split.df %>%testing()```### Import h2o```{r}#| warning: false#| error: falselibrary(h2o)h2o.init(nthreads =-1, max_mem_size ="148g", enable_assertions =FALSE) #disable progress bar for RMarkdownh2o.no_progress() # Optional: remove anything from previous sessionh2o.removeAll() ```### Import data to h2o cluster```{r}#| warning: false#| error: falseh_df=as.h2o(df)h_train =as.h2o(train.df)h_test =as.h2o(test.df)``````{r}CV.xy<-as.data.frame(h_train)test.xy<-as.data.frame(h_test)```### Define response and predictors```{r}#| warning: false#| error: falsey <-"SOC"x <-setdiff(names(h_df), y)```### Fit GLM model```{r}#| warning: false#| error: falseglm_h2o <-h2o.glm( ## h2o.glm functiontraining_frame = h_train, ## the H2O frame for training# validation_frame = valid, ## the H2O frame for validation (not required)x=x, ## the predictor columns, by column indexy=y, ## the target index (what we are predicting)model_id ="GLM_MODEL_ID", ## name the model in H2O## not required, but helps use Flowfamily ="gaussian", ## Family. Use binomial for classification with ## logistic regression, others are for regression problems. ## Must be one of: "AUTO", "gaussian", "binomial", ## "fractionalbinomial", "quasibinomial", "ordinal",## "multinomial", "poisson", "gamma", "tweedie", ## "negativebinomial". ## Defaults to AUTOcompute_p_values =TRUE, ## Logical. Request p-values computation, p-values ## work only with IRLSM solver and no regularization ## Defaults to FALSE.nfolds =10, ## umber of folds for K-fold cross-validation ## (0 to disable or >= 2). ## Defaults to 0.keep_cross_validation_models =TRUE, ## logical. Whether to keep the cross-validation models. ## Defaults to TRUE.early_stopping =TRUE, ## Logical. Stop early when there is no more relative ## improvement on train or validation (if provided) ## Defaults to TRUE.stopping_rounds =2, ## Early stopping based on convergence of stopping_metric. ## Stop if simple moving average of length k ## of the stopping_metric does not improve for ## k:=stopping_rounds scoring events (0 to disable) ## Defaults to 0.stopping_metric ="RMSE", ## Metric to use for early stoppingremove_collinear_columns =TRUE, ## Logical. In case of linearly dependent columns, ## remove some of the dependent columns Defaults to FALSE.standardize =TRUE, ## Logical. Standardize numeric columns to have zero mean ## and unit variance ## Defaults to TRUE.seed =212) ## Set the random seed so that this can be## reproduced.```### Coefficients table```{r}#| warning: false#| error: falseglm_h2o@model$coefficients_table```### Retrieve a graphical plot of the standardized coefficient magnitudes```{r}#| warning: false#| error: false#| fig.width: 8#| fig.height: 6h2o.std_coef_plot(glm_h2o)```### Model Performance```{r}# training performanceh2o.performance(glm_h2o, h_train)# CV-performanceh2o.performance(glm_h2o, xval=TRUE)# test performanceh2o.performance(glm_h2o, h_test)```### Prediction```{r}pred.glm <-as.data.frame(h2o.predict(object = glm_h2o, newdata = h_test))test_data<-as.data.frame(h_test)test_data$GLM_SOC<-pred.glm$predict ```We can plot observed and predicted values with fitted regression line with ggplot2```{r}#| warning: false#| error: false#| fig.width: 4#| fig.height: 4library(ggpmisc)formula<-y~xggplot(test_data, aes(SOC,GLM_SOC)) +geom_point() +geom_smooth(method ="lm")+stat_poly_eq(use_label(c("eq", "adj.R2")), formula = formula) +ggtitle("H2O: Observed vs Predicted SOC ") +xlab("Observed") +ylab("Predicted") +scale_x_continuous(limits=c(0,25), breaks=seq(0, 25, 5))+scale_y_continuous(limits=c(0,25), breaks=seq(0, 25, 5)) +# Flip the barstheme(panel.background =element_rect(fill ="grey95",colour ="gray75",size =0.5, linetype ="solid"),axis.line =element_line(colour ="grey"),plot.title =element_text(size =14, hjust =0.5),axis.title.x =element_text(size =14),axis.title.y =element_text(size =14),axis.text.x=element_text(size=13, colour="black"),axis.text.y=element_text(size=13,angle =90,vjust =0.5, hjust=0.5, colour='black'))```## Run R-Code in Google Colab[Google Colab](https://colab.research.google.com/) is a cloud-based platform provided by Google for running and executing Python code. It is built on top of Jupyter Notebook and offers a free, convenient, and collaborative environment for data analysis, machine learning, and general-purpose Python programming. Colab allows you to create and share Jupyter notebooks that include code, text, images, and visualizations.Key features of Google Colab include:1. **Free GPU and TPU Support:** Colab provides free access to a limited amount of GPU (Graphics Processing Unit) and TPU (Tensor Processing Unit) resources, which can significantly accelerate deep learning computations.2. **Collaborative Editing:** Multiple users can collaborate in real-time on the same Colab notebook, making it useful for team projects or sharing knowledge.3. **Google Drive Integration:** You can easily save and load files to and from your Google Drive, enabling seamless data storage and retrieval.4. **Rich Text and Media Support:** Colab notebooks support rich media integration, allowing you to include images, videos, and other multimedia elements in your notebooks.5. **Pre-installed Libraries:** Many popular Python libraries for data analysis, machine learning, and deep learning (e.g., NumPy, Pandas, TensorFlow, PyTorch) come pre-installed on Colab, reducing setup time.6. **Easy Sharing:** Colab notebooks can be easily shared with others by generating a shareable link. It's a convenient way to showcase your work or collaborate with others.To get started with Google Colab, you can visit the official website at [**https://colab.research.google.com/**](https://colab.research.google.com/). You can either create a new notebook or open an existing one from your Google Drive. The notebooks run on virtual machines hosted by Google, and once you close the browser, the virtual machine and its contents are discarded, but your notebook will be automatically saved to your Google Drive.Keep in mind that the available resources, such as GPU and TPU quotas, may be limited for free users. Also, the specific features and limitations of Google Colab may evolve over time, so it's always a good idea to check the official website or documentation for the latest information.Although Google Colab is primarily designed for Python, it also supports R. You can run R code in a Colab notebook by creating an R runtime environment. Here's how you can set it up:1. Open Google Colab in your web browser at https://colab.research.google.com/.2. Click on the "File" menu and select "New notebook" to create a new notebook.3. In the toolbar, click on the "Runtime" menu and select "Change runtime type."4. In the dialog box that appears, select "R" from the "Runtime type" dropdown.5. Click on the "Save" button to apply the changes.Once you have set up the R runtime environment, you can start writing and executing R code in the notebook cells. To run a code cell, press Shift+Enter or click on the "Play" button next to the cell.You can install R packages in Colab by using the **install.packages()** function.### Exercise1. Create a R-Markdown document (name homework_11.rmd) in this project and do all Tasks using the data shown below.2. Submit all codes and output as a HTML document (homework_11.html) before class of next week.#### Required R-Packagetidyverse, caret, Metrics, ggpmisc, report, performance, tidymodels#### Data1. [bd_soil_update.csv](https://www.dropbox.com/s/jtzycm4kg3lngu3/bd_soil_update.csv?dl=0)Download the data and save in your project directory. Use read_csv to load the data in your R-session. For example:> mf\<-read_csv("bd_soil_update.csv")#### Tasks1. Create a data-frame for GLM model SOC with following variables for Rajshahi Division: First use filter() to select data from Rajshai division and then use select() functions to create data-frame with following variables: SOM, DEM, NDVI, NDFI, DC, Geo_Description, LT, Land_use2. Fit GLM Models for SOC with caret, tidymodels and h20 packages3. Show all steps from data-processing to prediction on test data set.### Further Reading1. [GLM in R: Generalized Linear Model](https://www.datacamp.com/tutorial/generalized-linear-models)2. [GLM in R: Generalized Linear Model with Example](https://www.guru99.com/r-generalized-linear-model.html)3. [useR! Machine Learning Tutorial](https://koalaverse.github.io/machine-learning-in-R/)4. [caret](https://topepo.github.io/caret/)5. [tidymodels](https://www.tidymodels.org/)6. [H2O Generalized Linear Model (GLM)](https://docs.h2o.ai/h2o/latest-stable/h2o-docs/data-science/glm.html)