Introduction to Machine Learning
Machine learning is a sub-field of artificial intelligence that focuses on developing algorithms and statistical models that enable computer systems to learn and improve from experience without being explicitly programmed automatically. In other words, machine learning involves training computers to learn patterns and make predictions based on large amounts of data. Machine learning is used in various applications, such as image recognition, speech recognition, natural language processing, recommendation systems, and fraud detection. Machine learning is also often called predictive analytics or predictive modeling.
Machine Learning Versus Statistical Learning
Statistical and machine learning are two related but distinct fields with many similarities and some significant differences.
Statistical modeling is a branch of mathematics that deals with data collection, analysis, interpretation, presentation, and organization. Statistical models are often used to identify relationships between variables, test hypotheses, and make inferences about populations based on samples.
Machine learning, on the other hand, uses algorithms that receive and analyze input data to predict output values within an acceptable range. As new data is fed to these algorithms, they learn and optimize their operations to improve performance, developing ‘intelligence’ over time.
One key difference between statistical modeling and machine learning is that statistical modeling focuses more on understanding the underlying processes that generate the data. In contrast, machine learning focuses more on making accurate predictions or decisions based on the data. In other words, statistical modeling is often used to develop theories and test hypotheses. In contrast, machine learning is often used to build predictive models that can be used to make decisions in real-world applications. Another difference between the two fields is the types of data they tend to work with. Statistical modeling is often used to analyze structured data, such as data in tables or spreadsheets. In contrast, machine learning is often used to analyze structured and unstructured data, such as text, images, or audio.
Finally, the methods and tools used in statistical modeling and machine learning are often different. Statistical modeling typically uses traditional statistical techniques such as regression analysis, hypothesis testing, and confidence intervals. On the other hand, machine learning often involves using more complex algorithms such as neural networks, decision trees, and support vector machines.
Prediction Versus Inference
Inference and prediction are concepts commonly used in statistics, machine learning, and data analysis. While they are related, they refer to different processes.
Inference uses data and statistical methods to conclude a population based on a sample. It involves making estimates and testing hypotheses about the characteristics of the population based on the available data. Inference is often used in survey research, public health, and social sciences.
On the other hand, prediction can be defined as the process of applying machine learning or statistical models, or algorithms to data to predict new or future events or outcomes. It involves building models based on known or past data to predict new or future data points.
Types of Machine Learning Models
There are three main types of models in statistical modeling: parametric, semiparametric, and nonparametric.
Parametric Models:
Parametric models assume that the data follows a specific distribution, such as a standard or exponential distribution. The model has a fixed number of parameters estimated from the data using techniques such as maximum likelihood estimation or Bayesian inference. Once the parameters are estimated, the model can predict new data. Examples of parametric models include linear regression and logistic regression.
Nonparametric Models:
Nonparametric models make no assumptions about the underlying distribution of the data. They are based on flexible, functional forms, such as splines or kernel functions, that can adapt to the shape of the data. Nonparametric models do not have a fixed number of parameters, and the number of parameters grows with the size of the data. They are estimated using techniques such as kernel density estimation or decision trees. Examples of nonparametric models include k-nearest neighbors and random forests.
Semiparametric Models
Semiparametric models combine parametric and nonparametric elements. They assume that some aspects of the data follow a specific distribution while others do not. The model has a mix of fixed and flexible parameters estimated from the data using maximum or partial likelihood estimation techniques. Examples of semiparametric models include Cox proportional hazards regression and generalized linear mixed models.
Types Learning Algorithms
There are three main types of learning algorithms:
Supervised Learning
In supervised learning, the algorithm is trained on labeled data, where the input data is paired with corresponding output labels. The algorithm learns to map inputs to outputs and can then make predictions on new, unlabeled data. Examples of supervised learning include image classification, speech recognition, and regression analysis.
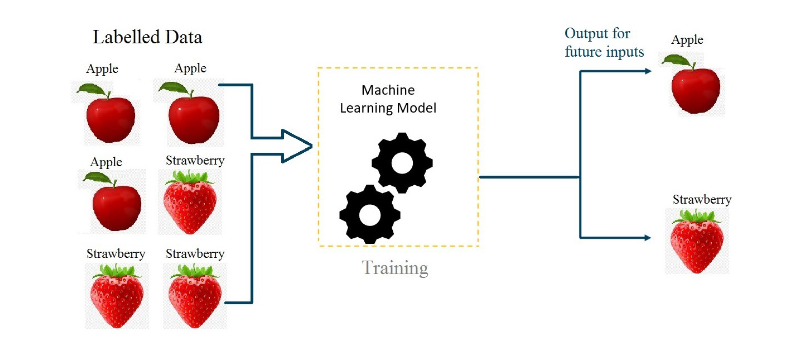
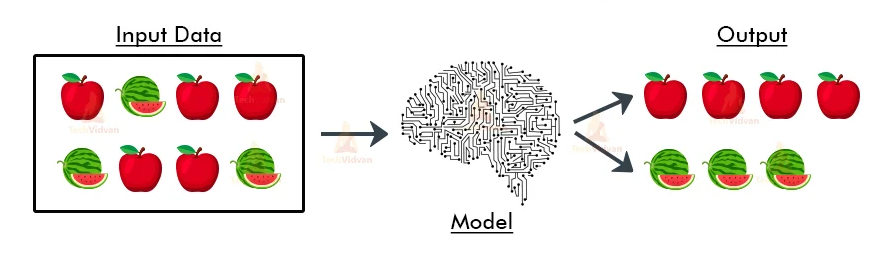
Regression and classification are two common types of supervised learning tasks in machine learning.
Regression involves predicting a continuous output variable, such as a house’s price, based on its features like size, number of rooms, location, etc. The goal is to learn a function that maps input variables to a continuous output variable, often represented as a line or curve. Various regression algorithms include linear regression, polynomial regression, and regression trees.
On the other hand, classification involves predicting a categorical output variable, such as whether an email is spam or not, based on its content, sender, subject, etc. The goal is to learn a function that maps input variables to a discrete output variable, often represented as a decision boundary or a set of rules. Various classification algorithms include logistic regression, decision trees, random forests, and support vector machines.
Unsupervised Learning:
In unsupervised learning, the algorithm is trained on unlabeled data and tasked with finding patterns or relationships in the data. The algorithm must learn to identify similarities and differences between data points and group them accordingly. Examples of unsupervised learning include clustering, anomaly detection, and dimensionality reduction.
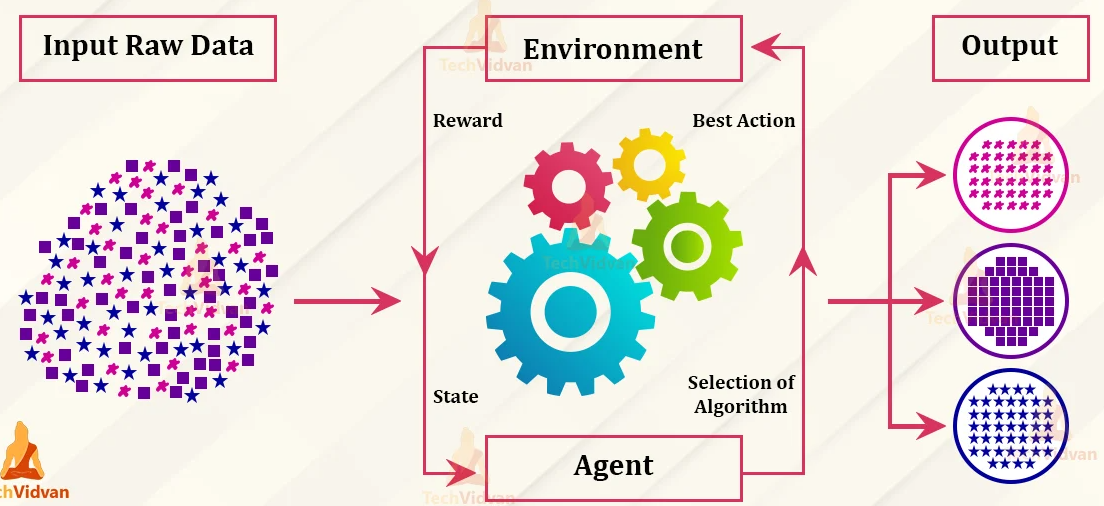
Reinforcement Learning:
In reinforcement learning, the algorithm learns through trial and error. It is given a goal or objective and interacts with an environment, receiving feedback as rewards or penalties based on its actions. The algorithm learns to take actions that maximize its rewards and achieve its goal. Examples of reinforcement learning include game-playing algorithms and robotics.
In addition to these three main types, hybrid approaches combine elements of different types of machine learning. For example, semi-supervised learning uses labeled and unlabeled data to improve performance, while transfer learning applies knowledge learned from one domain to another.
Hyperparameters in Machine Learning
Hyperparameters are the configuration settings the machine learning engineer or data scientist sets before training a machine learning algorithm. These parameters determine how the algorithm will learn from the data and make predictions. The importance of hyperparameters includes the fact that algorithm hyperparameters influence both the speed and learning mechanism. Hyperparameters are crucial as they can significantly affect the efficiency of the model being trained as well as the behavior of the training algorithm.
Hyperparameter tuning
It is also known as hyperparameter optimization, which is searching for the best combination of hyperparameters that results in the best performance of a machine learning algorithm on a given task.
The process of hyperparameter tuning involves the following steps:
1. Define a search space:
A search space is a range of possible values for each hyperparameter. The search space can be defined manually based on intuition or automatically using grid or random search techniques.
2. Select a performance metric:
A performance metric is a measure of how well the model is performing on a given task. Standard performance metrics include accuracy, precision, recall, F1 score, and mean squared error.
3. Choose a search strategy:
A search strategy is a method for exploring the search space to find the best hyperparameters. Common search strategies include grid search, random search, and Bayesian optimization.
3.1.Grid search:
Grid search is a set of hyperparameters defined along with their possible values. The algorithm then trains and evaluates the model for all possible combinations of hyperparameter values on a grid or a matrix. The model’s performance is measured using a performance metric such as accuracy, precision, or recall.
3.2. Random search
Like grid search, hyperparameters are defined along with their possible values. Still, instead of iterating over all possible combinations, random search randomly selects a set of hyperparameters from the defined range of values. The advantage of random search over grid search is that it can cover a larger hyperparameter space with fewer iterations, making it a more efficient technique for hyperparameter tuning.
3.3. Bayesian optimization
Bayesian optimization is a sequential model-based optimization method that uses previous iterations to inform the next set of hyperparameters to evaluate. Here, a prior distribution is defined for the hyperparameters. As the model is trained and evaluated, a posterior distribution is updated based on the model’s performance with the selected hyperparameters. The posterior distribution represents the uncertainty of the model’s performance for different hyperparameters.
4. Evaluate hyperparameters:
The selected search strategy evaluates different hyperparameter combinations using the chosen performance metric.
5. Select the best hyperparameters:
After evaluating all hyperparameter combinations, the best-performing set is selected based on the chosen performance metric.
6. Test the model:
The final step is to test the model’s performance on a separate test set to ensure that the model generalizes well to new data.