Introduction to Data Wrangling
Data Wrangling, also known as data munging, is the process of cleaning, transforming, and mapping data from one format to another to make it suitable for analysis and visualization. It involves resolving issues such as missing or duplicate values, inconsistent formatting, and dealing with outliers. Data wrangling is a crucial step in the data science process as it ensures that the data is reliable and trustworthy for further analysis and modeling. Data Wrangling of environmental data is the very important steps for building geospatial and machine Learning models.
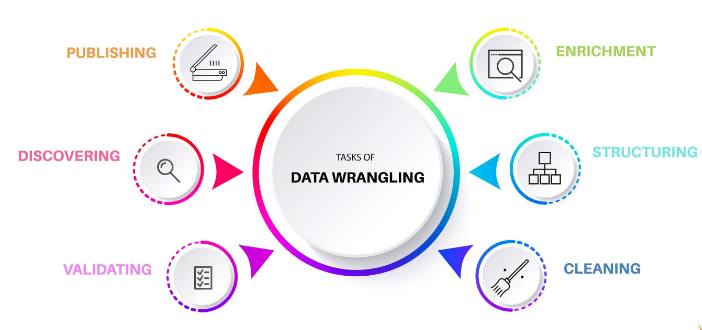
Steps of Data Wrangling
Here below 6 steps of data wrangling:
Discovering: systematic wrangling based on some criteria which could restrict and divide the data accordingly.
Structuring: the raw data should be restructured to suit the analytically method. Feature engineering can be done in this stage,
Cleaning: outliers and missing values identification, transformation and imputation
Enriching upscale, downsample, or perform data augmentation.
Validating: validation data after processing.
Publishing: process for further use