6.3. Poisson Regression Models for Overdispersed Data
When analyzing count data, you may encounter overdispersion, which occurs when the observed variability in the data is more significant than what a standard Poisson model would predict. Overdispersion often arises in real-world datasets because natural processes can introduce more variability than a simple Poisson model can accommodate. Ignoring overdispersion can lead to underestimated standard errors, unreliable confidence intervals, and misleading conclusions.
In this tutorial, we will explore methods for modeling overdispersed count data in R, focusing on approaches such as quasi-Poisson and negative binomial models, which can manage the extra variability in the data. We will begin by discussing the implications of overdispersion, then move on to fitting models from scratch and using R’s glm() function. After that, we’ll examine model diagnostics to detect overdispersion, evaluate the models to ensure a proper fit, and interpret incidence rate ratios (IRRs).
Overview
Poisson regression is used to model count data where the response variable represents the number of occurrences of an event. A key assumption of the Poisson model is that the mean and the variance of the response variable are equal:
\[ \text{Var}(Y) = \mu \]
Where \((Y)\) is the count response variable, and \(\mu\) is the mean (expected value) of the counts. However, in many real-world datasets, this assumption is often violated. When the variance is greater than the mean, the data exhibit overdispersion. Overdispersion can lead to underestimated standard errors and, as a result, inflated Type I error rates (i.e., falsely concluding that a predictor is significant).
Causes of Overdispersion
Overdispersion in count data can occur for several reasons, including:
Unobserved heterogeneity: There might be additional variables or factors influencing the count data that are not included in the model.
Zero-inflation: There might be an excess of zeros in the data compared to what the Poisson model predicts.
Clustering: Observations within clusters may be more similar than those across clusters, leading to greater variability than assumed.
Identifying Overdispersion
The variance is much greater than the mean, which suggests that we will have over-dispersion in the model.
Deviance: If the deviance is much larger than the degrees of freedom, it suggests overdispersion. We can estimate a dispersion parameter, \(ϕ\) by dividing the model deviance by its corresponding degrees of freedom; i.e.,
\[ ϕ^2 = \frac{\sum Residuals^2}{n-p} \]
If this statistic is significantly greater than 1, it suggests the presence of overdispersion.
You can also examine the Pearson Chi-Square statistic divided by the degrees of freedom as another indicator of overdispersion.
Handling Overdispersion in Poisson Regression
When overdispersion is present, Poisson regression is not appropriate, and alternative models are needed. There are several approaches to address overdispersion:
Quasi-Poisson Regression: A simple extension where the Poisson model is adjusted to allow for overdispersion by adding a dispersion parameter.
Negative Binomial Regression: A more flexible model that explicitly accounts for overdispersion by allowing the variance to differ from the mean.
Zero-Inflated Models: Useful when the overdispersion is caused by excess zeros in the data.
Quasi-Poisson model
Quasi-Poisson regression addresses the issue of overdispersion by allowing the variance to be a multiple of the mean, rather than strictly equal to the mean in traditional Poisson regression. This multiple, known as the dispersion parameter, is estimated from the data. By relaxing the assumption of equal mean and variance, quasi-Poisson regression can provide a more flexible model that better fits count data with overdispersion.
The quasi-Poisson model is a generalized linear model used for count data that assumes the variance of the response variable is proportional to its mean. It’s particularly useful when dealing with count data that exhibits overdispersion, where the variance is greater than the mean.
Let’s denote the response variable as \(Y\), the predictor variables as \(X_1, X_2, ..., X_p\), and the parameters of the model as \(\beta_0, \beta_1, ..., \beta_p\). The model can be represented as:
\[ Y \sim \text{Poisson}(\lambda) \]
where \(\lambda\) is the mean parameter of the Poisson distribution, given by:
In the quasi-Poisson model, the variance of \(Y\) is allowed to be a multiple \(\phi\) of the mean, so the variance function is given by:
\[ \text{Var}(Y) = \phi \lambda \]
where \(\phi\) is the dispersion parameter. When \(\phi = 1\), the quasi-Poisson model reduces to a standard Poisson model. When \(\phi > 1\), it indicates overdispersion, and when \(\phi < 1\), it indicates underdispersion.
The estimation of parameters \(\beta_0, \beta_1, ..., \beta_p\) in a quasi-Poisson model is typically done using maximum likelihood estimation (MLE). Maximum Likelihood Estimation (MLE) is a method used for estimating the parameters of a statistical model. It’s based on the principle of maximizing the likelihood function, which represents the probability of observing the given data given the parameters of the model.Additionally, the dispersion parameter \(\phi\) can also be estimated from the data.
Quasi-Poisson regression is particularly useful for count data where there may be unobserved or unaccounted-for sources of variation leading to greater variability than expected under a strict Poisson distribution. It is commonly used in fields such as epidemiology, ecology, and social sciences where count data is prevalent..
Below is a summary of the comparison between Poisson inference, which assumes no overdispersion, and quasi-Poisson inference, which accounts for overdispersion, in terms of tests and confidence intervals.
.
To fit a Quasi-Poisson model manually without using glm() function in R, you can follow will steps below:
Create a sample dataset with overdispersion
Fit a Poisson model
Estimate overdispersion parameter
Adjusting Standard Errors, t-test and Confidence Intervals
Generate a Sample Data
To create overdispersed count data for a Poisson regression model with 4 covariates and an offset, we can start with a basic Poisson model, then introduce extra variability by adding random noise from a Gamma distribution (often used to simulate overdispersion).
Code
# set seedset.seed(42) # for reproducibility# Number of observationsn <-500# Generate covariatesx1 <-rnorm(n)x2 <-rnorm(n)x3 <-rnorm(n)x4 <-rnorm(n)# Generate offset variable (positive values, often log-transformed)offset_var <-log(1+abs(rnorm(n)))# Define the true coefficients for each covariate and the interceptbeta <-c(0.5, -0.3, 0.2, 0.1, 0.7) # intercept and 4 coefficients# Calculate the linear predictor (eta) and expected Poisson meaneta <- beta[1] + beta[2] * x1 + beta[3] * x2 + beta[4] * x3 + beta[5] * x4 + offset_varmu <-exp(eta) # Poisson mean# Add overdispersion by using a Gamma distribution to introduce extra variation# Gamma mean = 1, shape parameter controls the level of overdispersion# Smaller shape (e.g., < 1) introduces more overdispersionshape_param <-0.5overdispersion_noise <-rgamma(n, shape = shape_param, scale =1/ shape_param)# Multiply the Poisson mean by the overdispersion noise to get the final meany_overdispersed <-rpois(n, lambda = mu * overdispersion_noise)# Compile into a data framedata <-data.frame(y = y_overdispersed, x1 = x1, x2 = x2, x3 = x3, x4 = x4, offset_var = offset_var)# View the structure and first few rows of the data to checkhead(data)
In a Quasi-Poisson model, overdispersion can be accounted for by using the estimated dispersion parameter to adjust model fit statistics, including the standard errors of the coefficient estimates, hypothesis tests, and other inferential measures. Here’s a detailed explanation of how this works:
# If the dispersion statistic is much greater than 1, overdispersion is presentif (dispersion_statistic >1.2) {cat("Warning: Evidence of overdispersion\n")} else {cat("No evidence of overdispersion\n")}
Warning: Evidence of overdispersion
Adjusting Standard Errors, t-test and Confidence Intervals
When overdispersion is present, the standard errors calculated in a Poisson model underestimate the variability in the data. In the Quasi-Poisson approach, the standard errors are adjusted by multiplying by the square root of the dispersion parameter, \(\phi\) (also called the quasi-likelihood variance or scale parameter).
If the dispersion parameter, \(\phi\), is estimated as:
where: - \(y_i\) is the observed response, - \(\hat{y}_i\) is the fitted response, - \(n\) is the number of observations, and - \(p\) is the number of estimated parameters in the model.
Then, the adjusted standard error of each coefficient, \(SE_{\text{adjusted}}\), is calculated as:
where \(SE_{\text{Poisson}}\) is the standard error from the original Poisson model.
With the adjusted standard errors, hypothesis tests for coefficients (using \(t\)-tests) and confidence intervals are also adjusted. For each coefficient ( _j ):
Adjusted\(t\)-statistic: The \(t\)-statistic is calculated as \(t_j = \frac{\hat{\beta_j}}{SE_{\text{adjusted}}}\).
Confidence Intervals: Adjusted confidence intervals are calculated as:
This table provides adjusted standard errors, \(t\)-values, and confidence intervals for the coefficients, accounting for overdispersion in the Quasi-Poisson model.
Negative Binomial Regression model
When dealing with overdispersion, one alternative approach is to use a negative binomial model instead of a Poisson distribution. This approach introduces an additional parameter in addition to the mean parameter, \(λ\), which gives the model more flexibility to handle a wider range of count data. This means that the negative binomial model can accommodate situations where the variance is greater than the mean, which is often the case in count data.
In contrast to the quasi-Poisson model, the negative binomial model assumes an explicit likelihood function or simply likelihood function that explicitly models the extra variation in the data. Negative binomial random variables are discrete probability distributions that are useful for modeling count data since they only take on non-negative integer values. This model posits that a \(λ\) value is selected for each institution, which is then used to generate a count using a Poisson random variable with the selected “λ”.
It relaxes the assumption that the variance equals the mean, allowing the variance to exceed the mean by a function of a dispersion parameter \(\theta\):
\[ \text{Var}(Y) = \mu + \frac{\mu^2}{\theta} \]
Where:
\(\theta\) is the dispersion parameter, estimated from the data.
As \(\theta \to \infty\), the model reduces to the standard Poisson regression.
The advantage of using a negative binomial model is that it can handle overdispersed data more effectively than a Poisson model alone. When using a Poisson model, the variance of the data is equal to the mean, which is often not the case in count data. The negative binomial model, on the other hand, can accommodate a wider range of variance-to-mean ratios, allowing it to fit the data more accurately. By using this approach, the counts will be more dispersed than what would be expected for observations based on a single Poisson variable with a rate of \(λ\).
For the Negative Binomial (NB) model, we need to estimate both regression coefficients and the dispersion parameter \(𝜃\) simultaneously. Define the log-likelihood function accordingly. Here below R code to fit a NB without any R Package:
# 4. Calculate Standard Errors# The standard errors are obtained from the Hessian (inverse of the matrix of second derivatives)hessian_matrix <- fit$hessiancov_matrix <-solve(hessian_matrix) # Variance-covariance matrixstandard_errors <-sqrt(diag(cov_matrix))# Display summary statisticssummary_stats <-data.frame(Coefficients = coef_estimates,`Std. Error`= standard_errors[1:5],`z value`= coef_estimates / standard_errors[1:5],`Pr(>|z|)`=2*pnorm(-abs(coef_estimates / standard_errors[1:5])))theta_se <- standard_errors[6] # Standard error for thetacat("Summary Statistics for Negative Binomial Model:\n")
cat("Dispersion Parameter (Theta) Standard Error:\n", theta_se, "\n")
Dispersion Parameter (Theta) Standard Error:
0.08914934
Poisson Model With Overdispersion in R
In this section, we will fit a Poisson regression model to count data with overdispersion in R. We will use the glm() function to fit the model and then check for overdispersion using diagnostic tests. If overdispersion is present, we will explore alternative models such as the quasi-Poisson and negative binomial models to handle the extra variability in the data.
Install Required R Packages
Following R packages are required to run this notebook. If any of these packages are not installed, you can install them using the code below:
Rows: 3107 Columns: 15
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): State, County, Urban_Rural
dbl (12): FIPS, X, Y, POP_Total, Diabetes_count, Diabetes_per, Obesity, Acce...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
To check for overdispersion or underdispersion in count data, you can compare the variance and mean of the response variable (i.e., the count data). Here’s how to check for overdispersion and underdispersion:
Poisson Distribution Assumption: In a standard Poisson model, the mean and variance of the count variable are equal. That is:
# Perform the dispersion testdispersiontest(fit.pois)
Overdispersion test
data: fit.pois
z = 20.558, p-value < 2.2e-16
alternative hypothesis: true dispersion is greater than 1
sample estimates:
dispersion
8.519496
Check for Overdispersion using {performance} packages
Code
performance::check_overdispersion(fit.pois)
# Overdispersion test
dispersion ratio = 9.842
Pearson's Chi-Squared = 21318.216
p-value = < 0.001
Overdispersion detected.
Fit a Quasi-Pisson Model
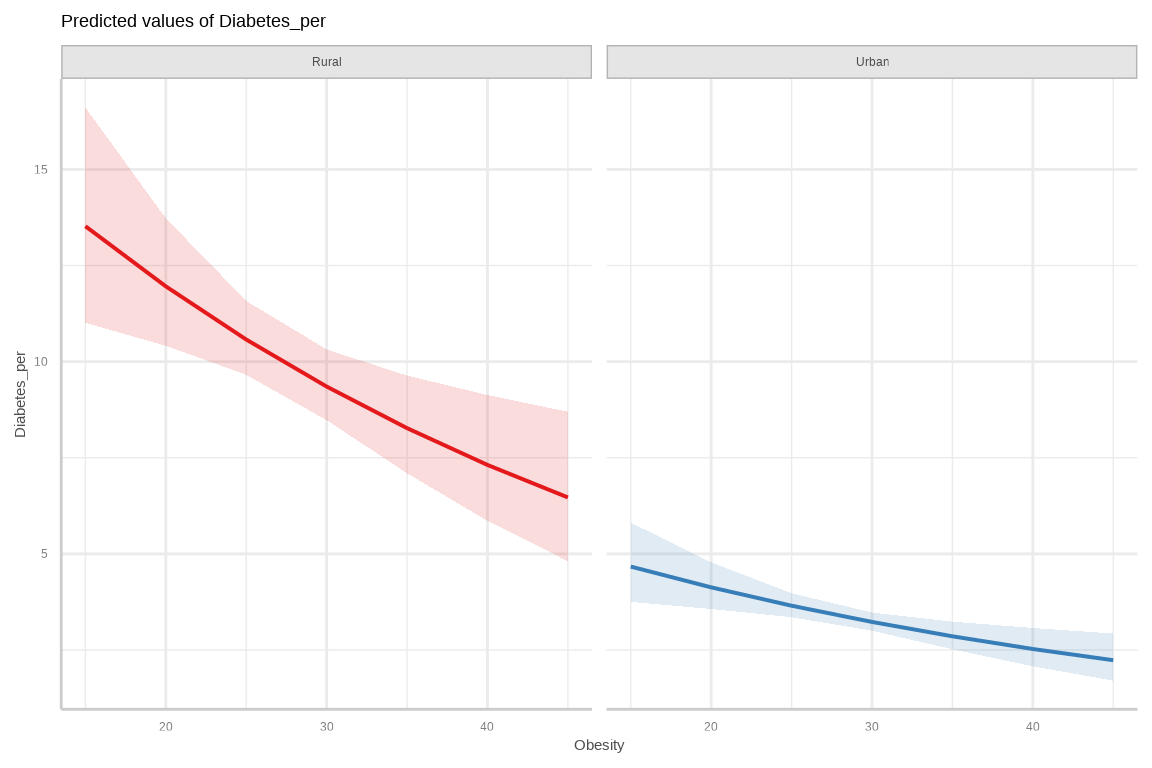
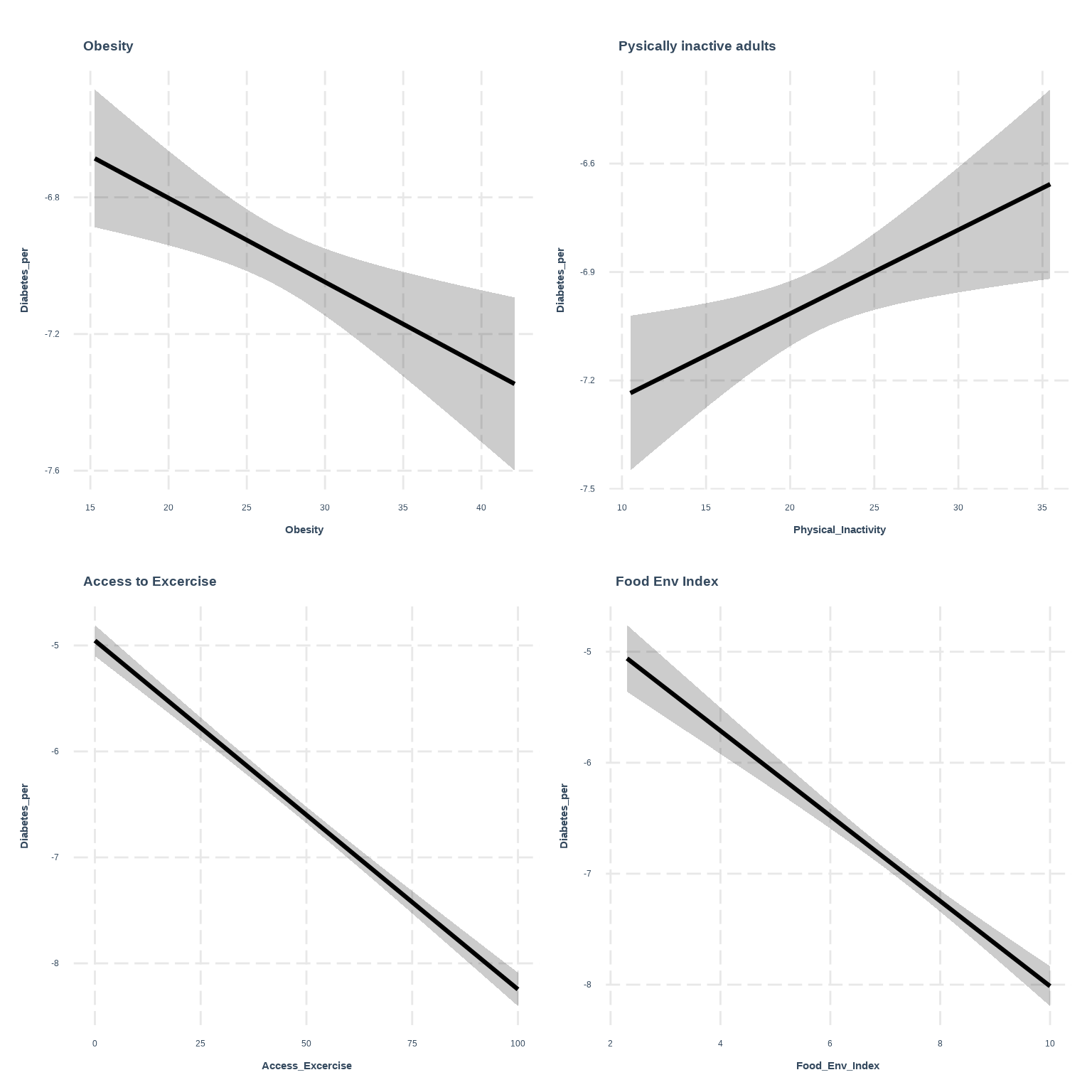
We will fit a quasi-Poisson regression model using the glm() function. In the family argument, we specify quasi with the linkfunction as “log” and variance function as mu, indicating a logarithmic link function and using the variance equal to the mean (quasi-Poisson).
{ggeffects} supports labelled data and the plot()- method automatically sets titles, axis - and legend-labels depending on the value and variable labels of the data
Abbreviations: CI = Confidence Interval, IRR = Incidence Rate Ratio
Model Comparison
Code
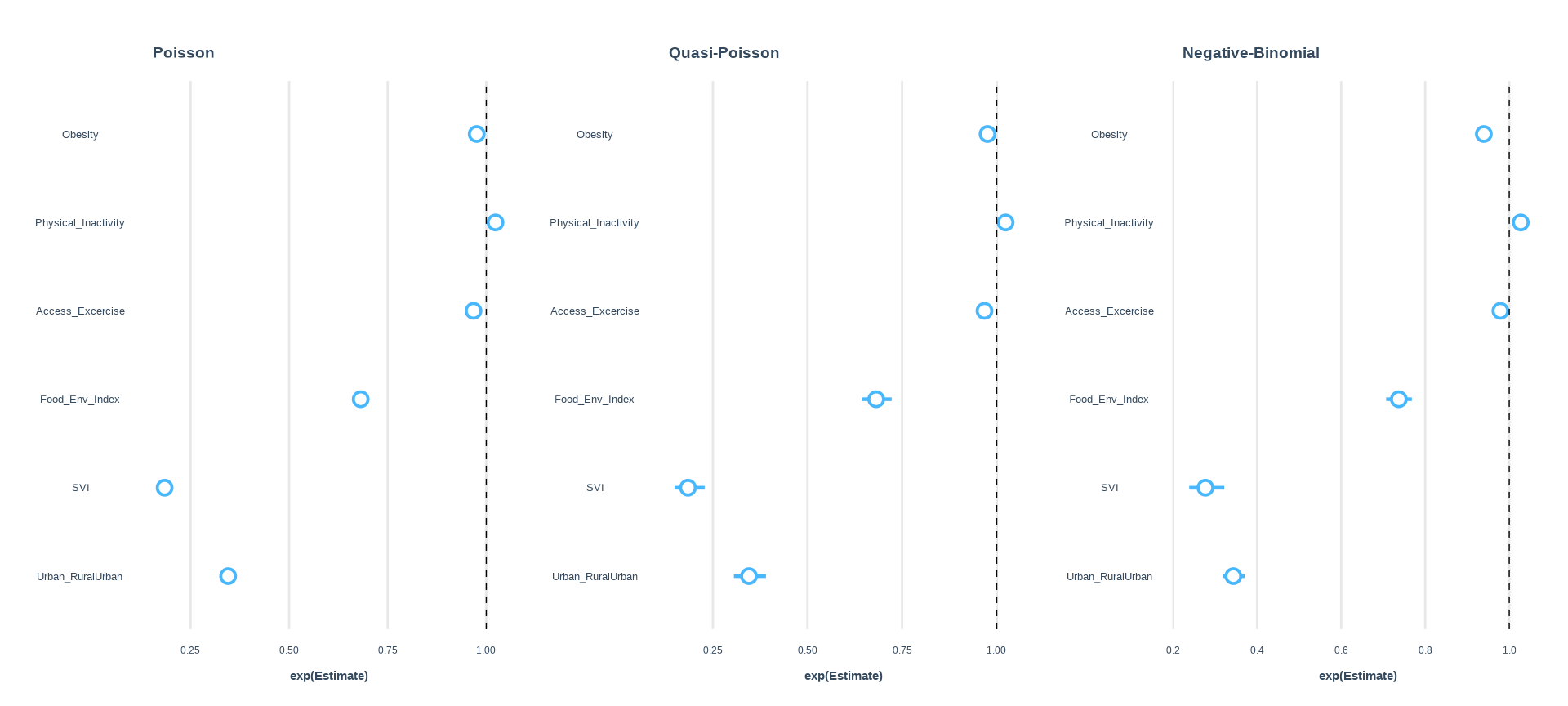
# extract coefficients from poisson model using 'coef()'coef1 =coef(fit.pois)# extract coefficients from quasi-model modelcoef2 =coef(fit.qpois)# extract coefficients from negtive binomial modelcoef3 =coef(fit.nb)# extract standard errors fse.coef1 =summary(fit.pois)$coefficients[, 2]se.coef2 =summary(fit.qpois)$coefficients[, 2]se.coef3 =summary(fit.nb)$coefficients[, 2]# use 'cbind()' to combine values into one dataframemodel.all <-cbind(coef1, se.coef1, coef2, se.coef2, coef3, se.coef3 )model.all
The output figure illustrates that the coefficients in both the Poisson and Quasi-Poisson models are identical. However, the standard errors of the coefficients are different. Specifically, fitting a Quasi-Poisson result in larger standard errors for Food ENV Index, and Urban/Rural compared to a Poisson and Negative Binomial models. The larger standard errors in this models are due to the model being more flexible, allowing for over-dispersion to be accounted for. These models, therefore, have a larger number of parameters to estimate, which leads to a larger variance in the estimated parameters. As a result, the confidence intervals for the coefficients in the Quasi-Poisson and Negative-Binomial models are wider, indicating a lower level of precision in the parameter estimates.
AIC (Akaike Information Criterion) / BIC (Bayesian Information Criterion):
Both the AIC and BIC are used to compare models based on how well they fit the data, while penalizing for the number of parameters to avoid overfitting.
The model with the lower AIC/BIC value is preferred.
To compare Quasi and NB models, fit both models and compare their AIC/BIC values
Code
AIC(fit.pois, fit.nb)
df AIC
fit.pois 7 21756.41
fit.nb 8 14582.49
Code
BIC(fit.pois, fit.nb)
df BIC
fit.pois 7 21796.20
fit.nb 8 14627.96
Likelihood Ratio Test (LRT):
The Likelihood Ratio Test (LRT) in R is used to compare two nested models, where one model is a simpler version (restricted) of another, more complex model. In the context of count data models, this can be used to compare a simpler Poisson regression model to a more complex model like a Negative Binomial regression model, provided that they are nested.
The LRT tests the null hypothesis that the simpler model fits the data just as well as the more complex one. The test statistic follows a chi-squared distribution, with degrees of freedom equal to the difference in the number of parameters between the two models.
A likelihood ratio test can be used to compare models that are nested (i.e., one model is a special case of another). However, Poisson and Quasi-piosson are not nested models, so the LRT is not applicable directly for comparing them. You can perform a similar test when comparing simpler versions of the models, like Poisson vs. NB.
cat("Degrees of Freedom Difference:", df_diff, "\n")
Degrees of Freedom Difference: 0
Code
cat("p-value:", p_value, "\n")
p-value: 0
The p-value is very small (e.g., less than 0.05), we reject the null hypothesis that the simpler Poisson model is sufficient. This suggests that the more complex negative binomial model is a better fit.
Prediction Performance
The predict() function will be used to predict the number of diabetes patients the test counties. This will help to validate the accuracy of the these regression models.
Code
# Predictiontest$Pred.pois<-predict(fit.pois, test, type ="response")test$Pred.qpois<-predict(fit.qpois, test, type ="response")test$Pred.nb<-predict(fit.nb, test, type ="response")# RMSErmse.pois<-Metrics::rmse(test$Diabetes_per, test$Pred.pois)rmse.qpois<-Metrics::rmse(test$Diabetes_per, test$Pred.qpois)rmse.nb<-Metrics::rmse(test$Diabetes_per, test$Pred.nb)cat("RMSE Poisson:", rmse.pois, "\n")
RMSE Poisson: 13.34734
Code
cat("RMSE Quasi-Poisson:", rmse.qpois, "\n")
RMSE Quasi-Poisson: 13.34734
Code
cat("RMSE Negative Binomial:", rmse.nb)
RMSE Negative Binomial: 23.25059
Summary and Conclusion
In this R tutorial, we explored the concepts and applications of Poisson, Quasi-Poisson, and Negative Binomial regression models. These models are essential for analyzing count data, where the response variable represents the number of events occurring in a fixed unit of observation.
Initially, we introduced the Poisson regression model, which assumes that the response variable’s mean and variance are equal. However, this assumption may not always be valid in real-world scenarios due to overdispersion, where the variance exceeds the mean. To address this issue, we explored the Quasi-Poisson regression model, which allows for overdispersion by introducing a dispersion parameter.
Furthermore, we discussed the Negative Binomial regression model, which is particularly useful when there is overdispersion and the variance exceeds the mean. This model relaxes the restrictive assumption of equal mean and variance in Poisson regression by incorporating an additional parameter to model the dispersion.
Throughout the tutorial, we provided examples of R code to illustrate the implementation of these regression models using relevant packages such as glm() from the stats package and glm.nb() from the MASS package. We demonstrated how to fit the models, interpret the coefficients, assess model fit using goodness-of-fit tests, and make predictions.
In conclusion, Poisson, Quasi-Poisson, and Negative Binomial regression models offer valuable tools for analyzing count data in various fields such as epidemiology, ecology, and social sciences. Understanding the differences between these models and when to use each one is crucial for accurate and reliable statistical analysis. While Poisson regression assumes equal mean and variance and is suitable for modeling count data with low dispersion, Quasi-Poisson and Negative Binomial regression models provide flexibility to accommodate overdispersion, making them more robust for real-world data. By mastering these regression techniques and leveraging R’s powerful statistical capabilities, researchers and practitioners can gain deeper insights into count data and make informed decisions based on sound statistical analysis.