Rows: 2,000
Columns: 15
$ pupil <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 1…
$ class <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
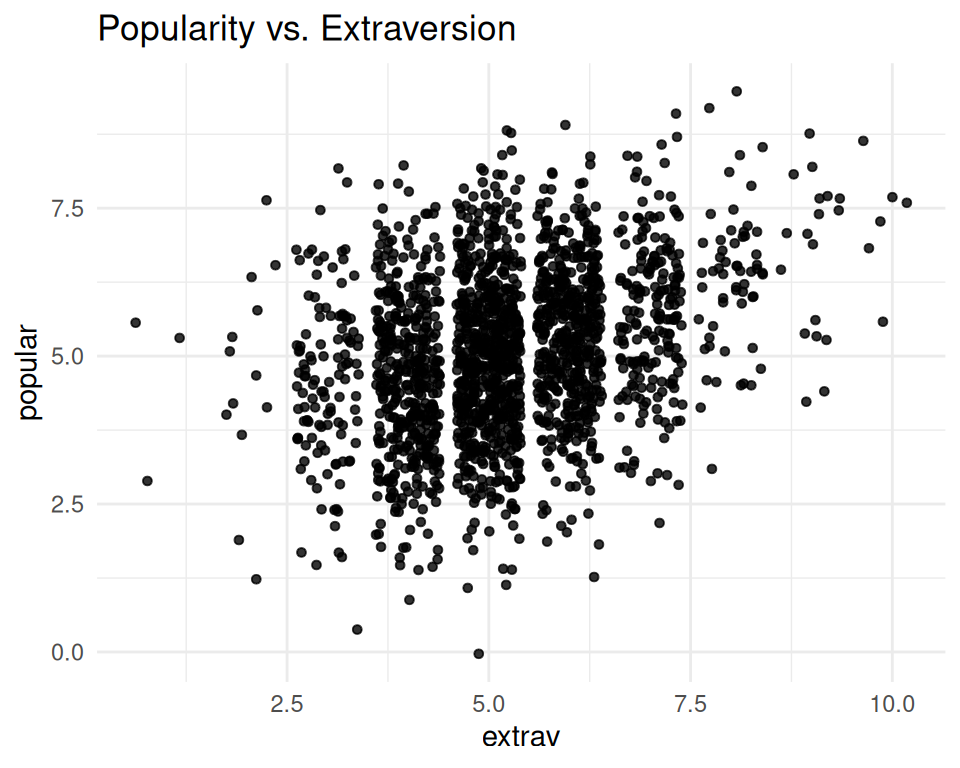
$ extrav <dbl> 5, 7, 4, 3, 5, 4, 5, 4, 5, 5, 5, 5, 5, 5, 5, 6, 4, 4, 7, 4, …
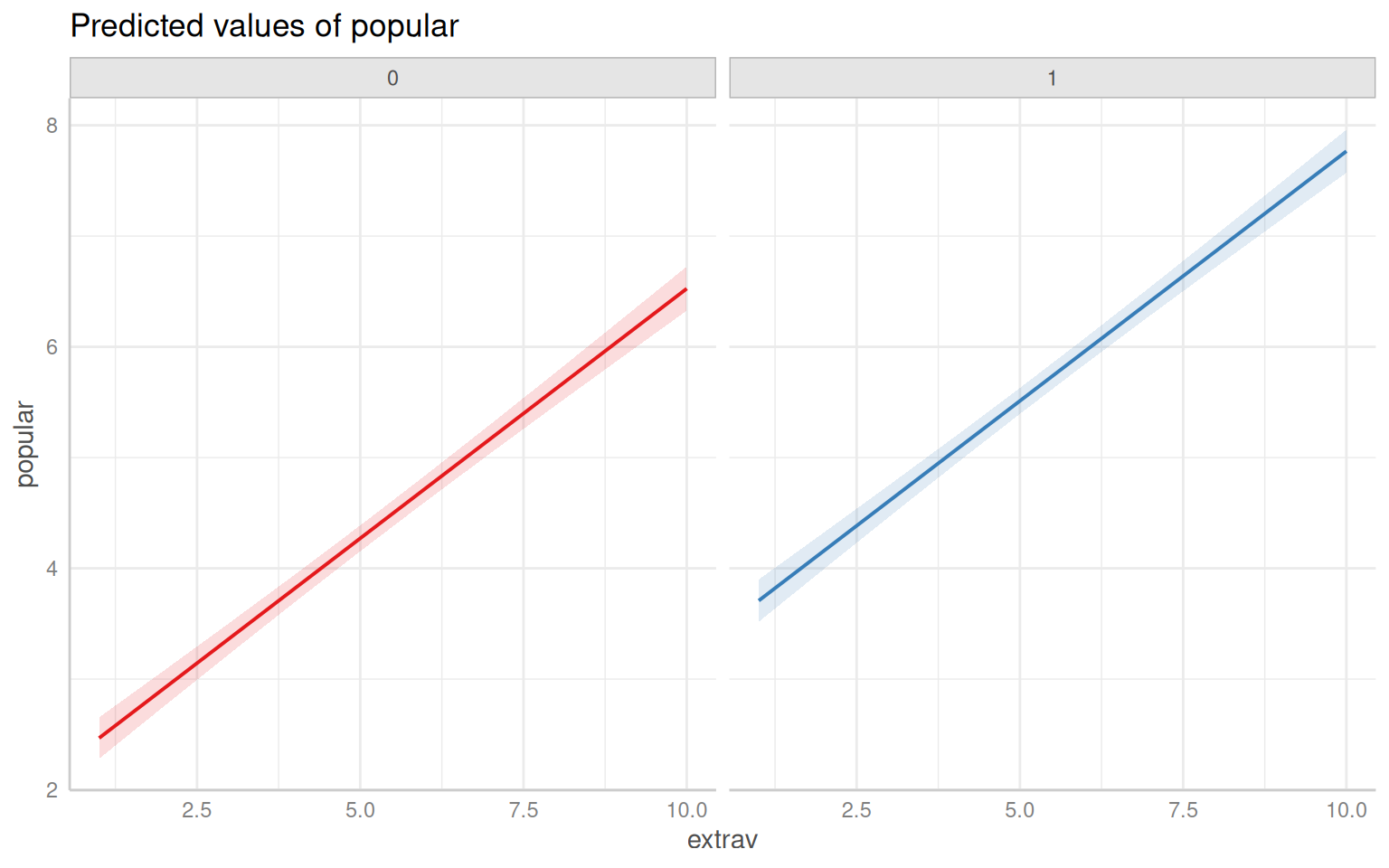
$ sex <dbl> 1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 0, …
$ texp <dbl> 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, 24, …
$ popular <dbl> 6.3, 4.9, 5.3, 4.7, 6.0, 4.7, 5.9, 4.2, 5.2, 3.9, 5.7, 4.8, …
$ popteach <dbl> 6, 5, 6, 5, 6, 5, 5, 5, 5, 3, 5, 5, 5, 6, 5, 5, 2, 3, 7, 4, …
$ Zextrav <dbl> -0.1703149, 1.4140098, -0.9624772, -1.7546396, -0.1703149, -…
$ Zsex <dbl> 0.9888125, -1.0108084, 0.9888125, 0.9888125, 0.9888125, -1.0…
$ Ztexp <dbl> 1.48615283, 1.48615283, 1.48615283, 1.48615283, 1.48615283, …
$ Zpopular <dbl> 0.88501327, -0.12762911, 0.16169729, -0.27229230, 0.66801848…
$ Zpopteach <dbl> 0.66905609, -0.04308451, 0.66905609, -0.04308451, 0.66905609…
$ Cextrav <dbl> -0.215, 1.785, -1.215, -2.215, -0.215, -1.215, -0.215, -1.21…
$ Ctexp <dbl> 9.737, 9.737, 9.737, 9.737, 9.737, 9.737, 9.737, 9.737, 9.73…
$ Csex <dbl> 0.5, -0.5, 0.5, 0.5, 0.5, -0.5, -0.5, -0.5, -0.5, -0.5, 0.5,…