This tutorial demonstrates how to perform panel linear regression using the {plm} package in R. Panel regression is a statistical technique used to analyze datasets that combine both cross-sectional and time-series data, known as panel data or longitudinal data. This method accounts for multiple observations of the same entities (e.g., individuals, firms, countries) over time, enabling researchers to control for variables that vary across entities or time periods but are unobserved or unmeasured.
Overview
Panel data, also known as longitudinal or cross-sectional time-series data, consists of observations on multiple entities (such as individuals, firms, or countries) over multiple time periods. Linear models for panel data are statistical methods used to analyze such data, accounting for both cross-sectional and time-series variations.
The {plm} package in R provides tools and functions for econometric analysis of panel data. It allows for the estimation of linear panel models, which are useful for analyzing datasets that contain observations on multiple entities (such as individuals, firms, or countries) over multiple time periods.
Several models can be estimated with plm by filling the model argument:
the fixed effects model ("within"), the default,
the pooling model ("pooling"),
the first-difference model ("fd"),
the between model ("between"), -
the error components model ("random").
Install Required R Packages
Following R packages are required to run this notebook. If any of these packages are not installed, you can install them using the code below:
For this tutorial, we will use the Cost Data for U.S. Airlines. The dataset is derived from the NYU Stern School of Business’s Econometric Analysis, 5th Edition. It includes cross-sectional data on the costs of U.S. airlines over 15 years, from 1970 to 1984, with 90 observations on 6 airline firms. The dataset contains the following variables:
I (Airline): Refers to six different airline companies being examined.
T (Year): Represents the years under analysis, spanning from 1970 to 1984 (15 years).
PF (Fuel Price): Indicates the global average price for aviation jet fuel at refineries. Prices are set by multi-year contracts between airlines and suppliers, remaining stable despite market fluctuations.
LF (Load Factor): Measures how much of an airline’s passenger capacity is utilized, influenced by seating capacity, routes, and demand.
Q (Revenue Passenger Miles): A key metric showing the miles traveled by paying passengers, commonly used in airline traffic statistics.
C (Cost) (in thousands): Influenced by Fuel Price, Load Factor, Lease and Depreciation, Aircraft Maintenance, Labor, and Airport Handling Charges.
Rows: 90 Columns: 6
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (6): I, T, C, Q, PF, LF
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
# assigening names to the columnslookup <-c(Airline ="I",Year ="T",Cost ="C" )my.data<-mf |># Rename using a named vector and `all_of()` dplyr::rename(all_of(lookup)) |># Convert to factors dplyr::mutate(across(c(Airline, Year), factor)) |># Rename the factor levels dplyr::mutate(Year = dplyr::recode(Year, '1'='1970','2'='1971','3'='1972','4'='1973','5'='1974','6'='1975','7'='1976','8'='1977','9'='1978','10'='1979','11'='1980','12'='1981','13'='1982','14'='1983','15'='1984' ) ) str(my.data)
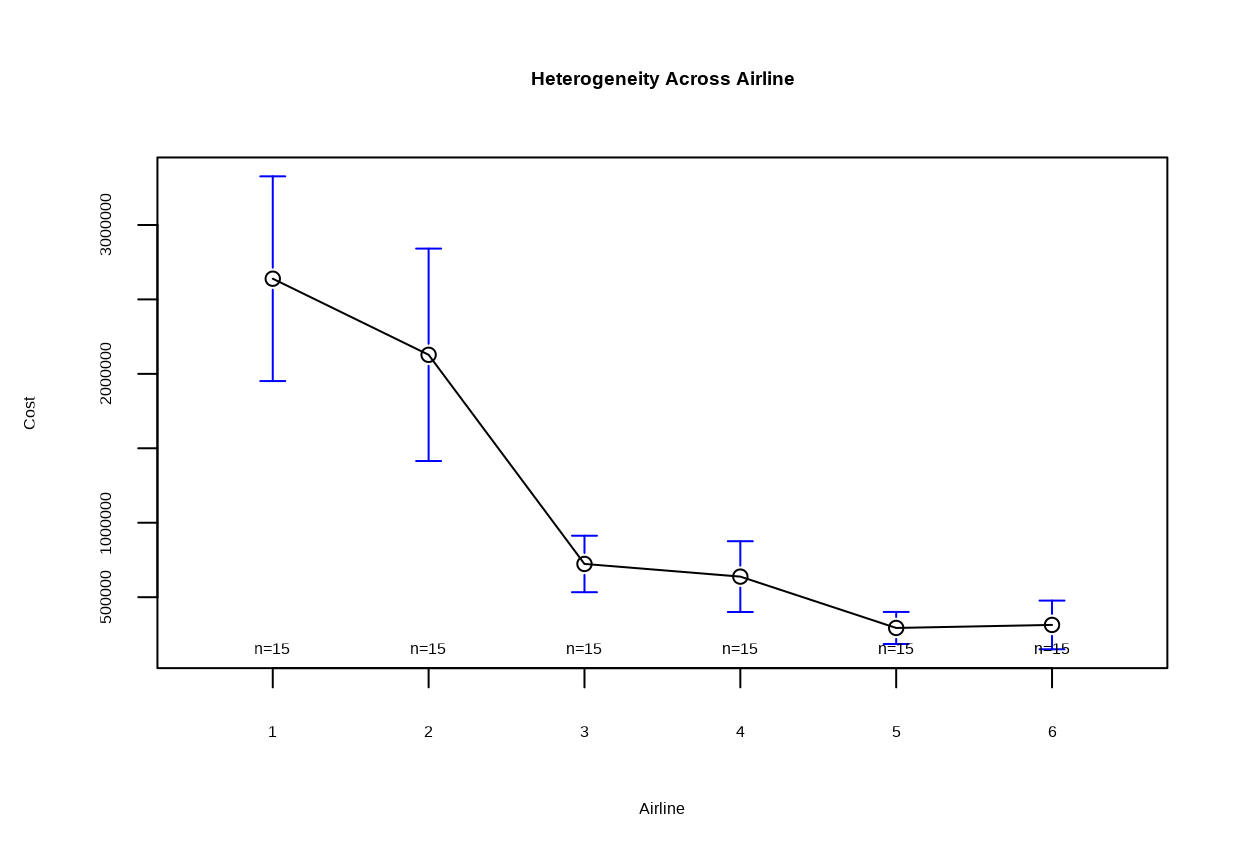
Hterogeneity across airlines can be visualized using a plotmean() function of {gplots} package. The plot shows the distribution of mean costs with CI for each airline, allowing us to compare the cost structures of different airlines.
Across Airlines
Code
plotmeans(Cost~Airline , main ='Heterogeneity Across Airline', data = my.data)
The plot shows the mean cost for each airline over the 15-year period, with confidence intervals indicating the variability in costs. The plot provides a visual representation of the heterogeneity in costs across airlines.
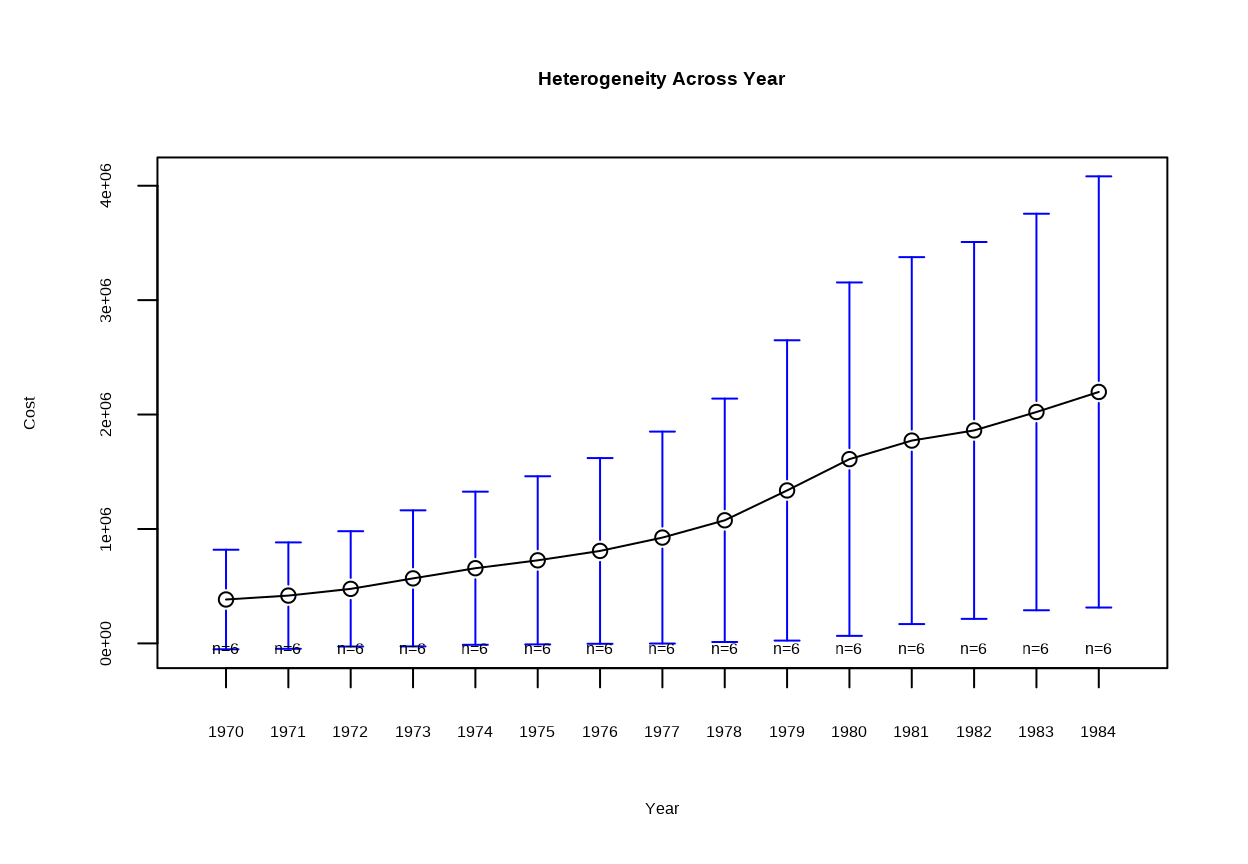
Across Years
Code
plotmeans(Cost~Year , main ='Heterogeneity Across Year', data = my.data)
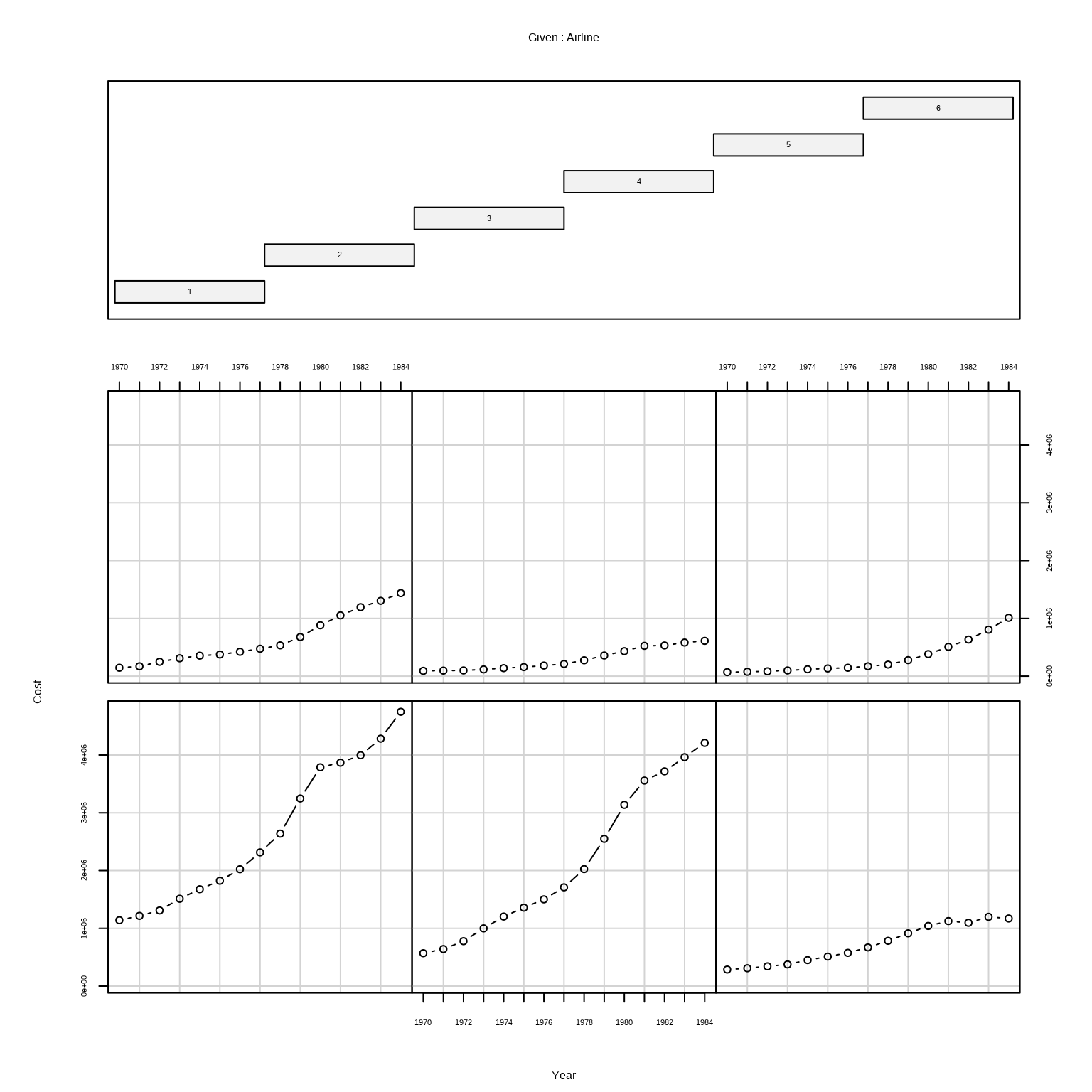
coplot() function of {gplots} package can be used to create a conditioned scatterplot matrix of the Cost variable by Year and Airline. This plot allows us to visualize the relationship between Cost and Year for each airline separately.
Panel data is typically transformed into a pdata.frame() object for panel regression analysis. This object includes an index that identifies the entity (e.g., individual, firm) and the time period.
Code
my.pd <-pdata.frame(my.data, index =c("Airline", "Year"))head(my.pd)
Pooled OLS Regression is a statistical method that applies the Ordinary Least Squares (OLS) technique to panel data (data with both cross-sectional and time-series dimensions) without accounting for the panel structure. It treats all observations as independent, even if they belong to the same entity (e.g., firm, country, or individual) over time.
Here’s how it differs from standard OLS regression:
Aspect
Pooled OLS
Standard OLS
Data Type
Panel data (cross-sectional + time-series).
Cross-sectional or time-series data.
Independence
Assumes all observations are independent (often unrealistic in panel data).
Assumes independence (valid for non-panel data).
Unobserved Effects
Does not control for entity/time effects (risk of omitted variable bias).
No need to control for panel-specific effects.
Efficiency
Likely inefficient due to autocorrelation/heteroscedasticity.
Efficient if Gauss-Markov assumptions hold.
A study analyzing the impact of education (\(X\)) on income (\(Y\)) across 10 countries over 5 years without considering country-specific or time-specific differences:
\[ Y_{it} = \beta_0 + \beta_1 X_{it} + u_{it} \]
where:
\(i\) represents the country,
\(t\) represents the time period,
\(u_{it}\) is the error term.
Limitations of Pooled OLS are below:
Omitted Variable Bias:
Fails to account for unobserved heterogeneity (e.g., company culture, geography) that is constant over time or across entities.
Example: If firms have unobserved traits affecting, Pooled OLS estimates will be biased.
Autocorrelation:
Repeated observations of the same entity over time often violate the “no autocorrelation” assumption.
Inefficient Standard Errors:
Heteroscedasticity (unequal variance) across entities or time is common but unaddressed.
Use Pooled OLS:
When entity/time effects are negligible (rare in practice).
As a baseline model before applying more advanced panel methods (e.g., fixed effects, random effects).
When data is insufficient for advanced techniques (e.g., short time periods).
Fit Pooled OLS Model
plm() function of {plm} package is used to estimate the Pooled OLS model. The model formula specifies the dependent variable (Cost) and independent variables (Q, PF, LF). The data argument specifies the panel data frame, and the model argument specifies the estimation method ("pooling" for Pooled OLS).
Code
# Fit Pooled OLS model pooled.model<-plm(Cost ~ Q + PF + LF, data = my.data, model ="pooling")
From above results, we can see that the Pooled OLS model estimates the coefficients for each independent variable. The Q, PF, and LF variables are included in the model. The coefficients, standard errors, t-statistics, and p-values are reported for each variable. The R-squared value indicates the proportion of variance explained by the model. The effect of these variales on coast is statistically significant at the 5% level.
coeftest() function {lmtest} package performs z and (quasi-) Wald tests of estimated coefficients. coefci() computes the corresponding Wald confidence intervals. The vcovHC() function of {plm} package computes heteroskedasticity-robust covariance matrix estimators for panel data models. The type argument specifies the type of robust standard errors to compute (e.g., HC0, HC1, HC2, HC3). The cluster argument specifies the variable used for clustering standard errors (e.g., “group” for entity-level clustering). Wald tests are used to test the null hypothesis that the coefficients are equal to zero.
Code
tbl.pooled.model <-tidy(lmtest::coeftest(pooled.model, vcov=vcovHC(pooled.model,type="HC0",cluster="group")))kable(tbl.pooled.model, digits=5, caption="Pooled OLS model with cluster robust standard errors")
Pooled OLS model with cluster robust standard errors
term
estimate
std.error
statistic
p.value
(Intercept)
1.158559e+06
4.084793e+05
2.83627
0.00569
Q
2.026114e+06
7.951013e+04
25.48247
0.00000
PF
1.225350e+00
3.487600e-01
3.51345
0.00071
LF
-3.065753e+06
1.017051e+06
-3.01436
0.00338
The performance() function of {performance} package computes various performance metrics for the model, including the R-squared, adjusted R-squared, F-statistic, and p-value. These metrics help evaluate the goodness of fit and statistical significance of the model.
Heteroscedasticity refers to the situation where the variance of the errors differs across observations. One common way to test for heteroscedasticity in R is by using the Breusch-Pagan test. The bptest() function of {lmtest} package performs the Breusch-Pagan test for heteroscedasticity in the residuals of the model. The test assesses whether the variance of the residuals is constant across observations. The null hypothesis is that the residuals are homoscedastic (constant variance).
Code
# Perform the Breusch-Pagan testlmtest::bptest(pooled.model)
studentized Breusch-Pagan test
data: pooled.model
BP = 24.082, df = 3, p-value = 2.401e-05
From above results, the p-value of the Breusch-Pagan test is less than 0.05, indicating that we reject the null hypothesis of homoscedasticity. This suggests that the residuals in the Pooled OLS model exhibit heteroscedasticity.
Fixed Effects Model
Fixed Effects (FE) Panel Regression is a method designed to analyze panel data (data with both cross-sectional and time-series dimensions) by controlling for unobserved, time-invariant heterogeneity across entities (e.g., firms, countries, individuals). Unlike Pooled OLS, which ignores the panel structure, FE explicitly accounts for entity-specific or time-specific characteristics that could bias results.
A study analyzing the effect of working hours (\(X\)) on employee productivity ((Y)) in different companies over time, accounting for company-specific characteristics.
\[ Y_{it} = \beta X_{it} + \alpha_i + u_{it} \]
where:
\(\alpha_i\) is the individual-specific effect (company-specific fixed effect).
The Within Transformation is used to eliminate \(\alpha_i\), typically by demeaning the data.
How FE Differs from Pooled OLS:
Aspect
Fixed Effects (FE)
Pooled OLS
Unobserved Heterogeneity
Controls for entity-specific/time-specific effects (e.g., firm culture, stable policies).
Ignores unobserved heterogeneity, leading to omitted variable bias if \(\alpha_i\) correlates with \(X_{it}\).
Data Used
Uses only within-entity variation (changes over time).
Uses both within and between variation (treats all observations as independent).
Efficiency
Less efficient than Pooled OLS (loses between-variation), but unbiased if \(\alpha_i\) correlates with \(X_{it}\).
More efficient if no omitted variable bias, but biased if \(\alpha_i\) correlates with \(X_{it}\).
Time-Invariant Variables
Cannot estimate coefficients for variables that do not vary over time (e.g., country area).
Can estimate coefficients for time-invariant variables.
Error Structure
Allows for autocorrelation within entities (clustered standard errors often used).
Assumes i.i.d errors, which is often violated in panel data.
When to Use FE vs. Pooled OLS:
Use FE if*:
Unobserved entity-specific factors (e.g., corporate culture, geography) are suspected to correlate with regressors.
Focus is on within-entity relationships (e.g., “How does increasing R&D within a firm affect its profits?”).
Use Pooled OLS if:
Entity/time effects are negligible (unlikely in practice).
You need to estimate effects of time-invariant variables (e.g., gender, geography).
The fixed effects model can be estimated using various methods, including:
Least Squares Dummy Variable (LSDV) Approach: This involves including dummy variables for each entity to capture the individual-specific intercepts.
Within Transformation: This method involves subtracting the entity-specific means from the variables to eliminate the individual-specific intercepts.
First Differences: This approach involves differencing the data to remove the individual-specific intercepts.
Fixed Effects regression addresses the critical flaw of Pooled OLS— omitted variable bias from unobserved heterogeneity—by isolating within-entity variation. While less efficient, FE provides unbiased estimates when entity-specific traits correlate with regressors. Pooled OLS, though simpler, risks severe bias in such cases and is best used as a baseline or when heterogeneity is irrelevant.
Least Squares Dummy Variable (LSDV) Approach
The Least Squares Dummy Variable (LSDV) model is a method used in fixed effect panel regression to account for individual-specific effects by including dummy variables for each entity. This method allows us to control for unobserved heterogeneity by including a separate intercept for each entity (Ariline).
\(y_{it}\) is the dependent variable for entity \(i\) at time \(t\)
\(\alpha\) is the overall intercept
\(x_{it}\) is the explanatory variable for entity \(i\) at time \(t\)
\(\beta\) is the coefficient for the explanatory variable \(x_{it}\)
\(D_i\) is a dummy variable for entity \(i\) (1 if the observation belongs to entity \(i\), 0 otherwise)
\(\gamma_i\) is the coefficient for the dummy variable \(D_i\)
\(\epsilon_{it}\) is the error term
The LSDV model allows us to estimate the effect of the explanatory variable \(x_{it}\) while controlling for entity-specific effects. The dummy variables capture the entity-specific intercepts, allowing us to account for unobserved heterogeneity that is constant over time.
The plm() function of {plm} package is used to estimate the Fixed Effects (FE) model using the Least Squares Dummy Variable (LSDV) approach. The model formula specifies the dependent variable (Cost) and independent variables (Q, PF, LF).
Code
# Fit fixedx-effect model fixed.lsdv<-plm(Cost ~ Q + PF + LF+factor(Airline)-1,data = my.pd)
plm() function of {plm} package is used to estimate the Fixed Effects (FE) model. The model formula specifies the dependent variable (Cost) and independent variables (Q, PF, LF). The data argument specifies the panel data frame, and the model argument specifies the estimation method ("within" for FE).
One-way Fixed Effects Model
One-way fixed effect model is used to estimate the effect of the explanatory variables while controlling for individual-specific effects. The within transformation is applied to the data to remove the individual-specific intercepts. The model formula specifies the dependent variable (Cost) and independent variables (Q, PF, LF).
Code
# Fit fixedx-effect model fixed.model.one<-plm(Cost ~ Q + PF + LF, data = my.pd, model ="within")
========================================
Dependent variable:
---------------------------
Cost
----------------------------------------
Q 3,319,023.000***
(171,354.100)
t = 19.369
p = 0.000
PF 0.773***
(0.097)
t = 7.944
p = 0.000
LF -3,797,368.000***
(613,773.100)
t = -6.187
p = 0.00000
----------------------------------------
Observations 90
R2 0.929
Adjusted R2 0.922
F Statistic 355.254*** (df = 3; 81)
========================================
Note: *p<0.1; **p<0.05; ***p<0.01
The fixed effects of a fixed effects model may be extracted easily using fixef(). An argument type indicates how fixed effects should be computed: in levels by type = "level" (the default), in deviations from the overall mean by type = "dmean" or in deviations from the first individual by type = "dfirst"
In case of a two-ways fixed effect model, argument effect is relevant in function fixef to extract specific effect fixed effects with possible values "individual" for individual fixed effects (default for two-ways fixed effect models), "time" for time fixed effects, and "twoways" for the sum of individual and time fixed effects. Example to extract the time fixed effects from a two-ways model:
Code
# Fit fixedx-effect model fixed.model.two<-plm(Cost ~ Q + PF + LF, data = my.pd, model ="within",effect ="twoways")
Testing for Fixed Effects (Observed Heterogeneity)
The pFtest() function is used to perform the F-test for fixed effects in panel data regression models. This test is used to determine whether the fixed effects model is significantly better than the pooled OLS model. In other words, it tests whether individual-specific effects are necessary to account for unobserved heterogeneity in the data.
Code
pFtest(fixed.lsdv, pooled.model)
F test for individual effects
data: Cost ~ Q + PF + LF + factor(Airline) - 1
F = 14.595, df1 = 5, df2 = 81, p-value = 3.467e-10
alternative hypothesis: significant effects
Code
# Perform the F-test for fixed effectspFtest(fixed.model.one, pooled.model)
F test for individual effects
data: Cost ~ Q + PF + LF
F = 14.595, df1 = 5, df2 = 81, p-value = 3.467e-10
alternative hypothesis: significant effects
Code
# Perform the F-test for fixed effectspFtest(fixed.model.two, pooled.model)
F test for twoways effects
data: Cost ~ Q + PF + LF
F = 3.7313, df1 = 19, df2 = 67, p-value = 3.319e-05
alternative hypothesis: significant effects
The p-value of the F-test is lower than 0.05 (reject the null hypothesis), indicating that the fixed model is significantly better than the pooled model. This suggests that individual-specific effects are necessary to account for unobserved heterogeneity in the data.
Random Effect Model
Random Effects (RE) Panel Regression is a method used to analyze panel data by accounting for unobserved heterogeneity across entities (e.g., firms, countries, individuals) that is uncorrelated with the explanatory variables. Unlike Fixed Effects (FE) models, which control for entity-specific effects, Random Effects models allow for entity-specific effects that are uncorrelated with the regressors. In RE models, it is assumed that the individual-specific effects are uncorrelated with the explanatory variables. This method allows for more efficient estimates compared to fixed effects (FE) models when the assumption of no correlation holds true.
Key Features of Random Effects Model are:
Random Individual-specific Effects: The RE model includes random individual-specific effects that are assumed to be uncorrelated with the explanatory variables. These effects capture unobserved heterogeneity across entities.
Efficiency: By assuming that individual-specific effects are random, the RE model uses both within-entity and between-entity variations, making it more efficient than the fixed effects model.
Generalization: The RE model generalizes the fixed effects model by allowing for the possibility that individual-specific effects are not fixed but random.
\(y_{it}\) is the dependent variable for entity \(i\) at time \(t\)
\(\alpha\) is the overall intercept
\(x_{it}\) is the explanatory variable for entity \(i\) at time \(t\)
\(\beta\) is the coefficient for the explanatory variable \(x_{it}\)
\(u_i\) is the random effect specific to entity \(i\)
\(\epsilon_{it}\) is the idiosyncratic error term
In the RE model, \(u_i\) is treated as a random variable that follows a normal distribution with mean zero and variance \(\sigma_u^2\).
Differences between Random Effects and Fixed Effects Models are summarized below:
Feature
Random Effects (RE) Model
Fixed Effects (FE) Model
Correlation
Assumes no correlation between \(u_i\) and \(x_{it}\)
Assumes \(u_i\) is correlated with \(x_{it}\)
Efficiency
More efficient if the assumption holds true
Less efficient due to loss of degrees of freedom
Estimation
Uses Generalized Least Squares (GLS)
Uses Least Squares Dummy Variable (LSDV) or Within Estimator
Interpretation
Considers both within and between variation
Considers only within variation
Dummy Variables
Does not include dummy variables for entities
Includes dummy variables for each entity
Fit Random Effects Model
The plm() function of {plm} package is used to estimate the Random Effects (RE) model. The model formula specifies the dependent variable (Cost) and independent variables (Q, PF, LF). The data argument specifies the panel data frame, and the model argument specifies the estimation method ("random" for RE). Argument random.method is the variance component the random effects model. The default is swar (the Swamy-Arora estimator).
Four estimators of this parameter are available, depending on the value of the argument random.method:
"swar": from Swamy and Arora (1972), the default value,
"walhus": from Wallace and Hussain (1969),
"amemiya": from T. Amemiya (1971),
"nerlove": from Nerlove (1971).
"ht": for Hausman-Taylor-type instrumental variable (IV) estimation,
One-way Random-effect model
Code
# Fit One-way Random-effect model random.model.one<-plm(Cost ~ Q + PF + LF, data = my.pd, model ="random",random.method="swar")
========================================
Dependent variable:
---------------------------
Cost
----------------------------------------
Q 2,288,588.000***
(109,493.700)
t = 20.902
p = 0.000
PF 1.124***
(0.103)
t = 10.862
p = 0.000
LF -3,084,994.000***
(725,679.800)
t = -4.251
p = 0.00003
Constant 1,074,293.000***
(377,468.000)
t = 2.846
p = 0.005
----------------------------------------
Observations 90
R2 0.911
Adjusted R2 0.908
F Statistic 883.501***
========================================
Note: *p<0.1; **p<0.05; ***p<0.01
The estimation of the variance of the error components are performed using the ercomp() function, which has a method and an effect argument, and can be used by itself:
The H`ausman test is used to compare the random effects model with the fixed effects model. It tests whether the individual-specific effects are correlated with the explanatory variables. If the p-value is less than the chosen significance level (e.g., 0.05), we reject the null hypothesis and conclude that the fixed effects model is more appropriate.
Null Hypothesis (H0): The individual-specific effects are uncorrelated with the explanatory variables (RE model is appropriate).
Alternative Hypothesis (H1): The individual-specific effects are correlated with the explanatory variables (FE model is appropriate).
If the p-value is less than the chosen significance level, we reject the null hypothesis and conclude that the fixed effects model is more appropriate.
The phtest() function is used to perform the Hausman test, which helps compare the fixed effects (FE) model with the random effects (RE) model in panel data analysis.
Code
phtest(fixed.model.one, random.model.one)
Hausman Test
data: Cost ~ Q + PF + LF
chisq = 60.87, df = 3, p-value = 3.832e-13
alternative hypothesis: one model is inconsistent
Code
phtest(fixed.model.two, random.model.two)
Hausman Test
data: Cost ~ Q + PF + LF
chisq = 45.813, df = 3, p-value = 6.214e-10
alternative hypothesis: one model is inconsistent
The p-value of the Hausman test is less than 0.05, indicating that we reject the null hypothesis of no correlation between individual-specific effects and the explanatory variables. This suggests that the fixed effects model is more appropriate than the random effects model.
Dynamic Panel Regression (GMM)
Dynamic Panel Regression using Generalized Method of Moments (GMM) is a statistical technique used to estimate panel data models that include lagged dependent variables as regressors. This method is particularly useful when dealing with endogeneity issues, where explanatory variables are correlated with the error term. GMM helps in obtaining consistent and efficient estimates by using instrumental variables.
Key Concepts in Dynamic Panel Regression include:
Lagged Dependent Variable: The previous values of the dependent variable are used as regressors.
Endogeneity: When explanatory variables are correlated with the error term.
Instrumental Variables: Variables that are uncorrelated with the error term and can be used as instruments to address endogeneity.
GMM Estimation: A method that uses moment conditions to obtain parameter estimates.
\(y_{it}\) is the dependent variable for entity \(i\) at time \(t\)
\(y_{it-1}\) is the lagged dependent variable
\(x_{it}\) is a vector of explanatory variables
\(\alpha\) and \(\beta\) are the coefficients to be estimated
\(\epsilon_{it}\) is the error term
Data
In this example, we will estimate a dynamic panel model with a lagged dependent variable as a regressor. We use `Produc`` dataset from the {plm} package for this example. Dataset is a panel of 48 observations from 1970 to 1986 and contains following variables:
state: the state
year: the year
region: the region
pcap: public capital stock
hwy: highway and streets
water: water and sewer facilities
util: other public buildings and structures
pc: private capital stock
gsp: gross state product
emp: labor input measured by the employment in non–agricultural payrolls
unemp: state unemployment rate
Code
# Load sample datadata("EmplUK", package ="plm")# Define a panel data framepdata <-pdata.frame(EmplUK, index =c("firm", "year"))head(pdata)
To perform dynamic panel regression using GMM in R, we can use the {plm} package along with the pgmm() function. The pgmm() function estimates the model using the Generalized Method of Moments (GMM) approach.
pgmm function is used to fit a Generalized Method of Moments (GMM) model.
emp ~ lag(emp, 1) + capital + output specifies the regression formula where emp (employment) is the dependent variable, and lagged employment (lag(emp, 1)), capital, and output are the independent variables.
lag(emp, 2:99) specifies the instruments, which in this case are lagged values of employment from the second lag onwards.
effect = "twoways" indicates that both individual and time effects are included in the model.
model = "twosteps" specifies that the two-step GMM estimator is used.
Code
# Fit the GMM model# Example model: Employment (emp) as a function of lagged employment (lag(emp)), capital (capital), and output (output)gmm_model <-pgmm(emp ~lag(emp, 1) + capital + output |lag(emp, 2:99), data = pdata, effect ="twoways", model ="twosteps")summary(gmm_model)
Twoways effects Two-steps model Difference GMM
Call:
pgmm(formula = emp ~ lag(emp, 1) + capital + output | lag(emp,
2:99), data = pdata, effect = "twoways", model = "twosteps")
Unbalanced Panel: n = 140, T = 7-9, N = 1031
Number of Observations Used: 751
Residuals:
Min. 1st Qu. Median Mean 3rd Qu. Max.
-26.2233 -0.1014 0.0000 -0.0489 0.1542 24.0927
Coefficients:
Estimate Std. Error z-value Pr(>|z|)
lag(emp, 1) 0.73118 0.25733 2.8414 0.004491 **
capital 0.77554 0.65885 1.1771 0.239151
output -0.02177 0.02082 -1.0456 0.295729
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Sargan test: chisq(27) = 56.24425 (p-value = 0.00080133)
Autocorrelation test (1): normal = -1.264517 (p-value = 0.20604)
Autocorrelation test (2): normal = -1.609374 (p-value = 0.10753)
Wald test for coefficients: chisq(3) = 67.09298 (p-value = 1.7888e-14)
Wald test for time dummies: chisq(7) = 9.752898 (p-value = 0.20301)
Coefficients**:` The coefficients for the lagged dependent variable and the explanatory variables represent their effects on the dependent variable.
Sargan Test: Tests the validity of the instruments. A high p-value indicates that the instruments are valid.
AR(1) and AR(2) Tests: Test for serial correlation in the error term. The AR(1) test should reject the null hypothesis (indicating first-order serial correlation), while the AR(2) test should not reject the null hypothesis (indicating no second-order serial correlation).
waldtest: Tests the joint significance of the coefficients. A low p-value indicates that at least one coefficient is significantly different from zero.
Variable Coefficients Model
Variable Coefficients Model for Panel Data allow regression coefficients to vary across entities (e.g., firms, states) or time periods. Unlike standard fixed/random effects models (which assume constant slopes), these models capture heterogeneity in how variables affect outcomes. Common types include:
Random Coefficients Models (RCM)**:
Coefficients are treated as random variables drawn from a distribution (e.g., normal).
Example: Swamy’s model, which estimates mean coefficients and their variance across entities.
Fixed Coefficients by Group:
Coefficients differ across predefined groups (e.g., regions) but are fixed within groups.
Key Differences Between Models are as follows:
Model
Assumption
Use Case
Fixed Coefficients
Coefficients differ across entities (fixed).
When group-specific effects are distinct (e.g., policy impacts vary by state).
Random Coefficients
Coefficients follow a distribution.
When coefficients are heterogeneous but share a common structure.
Variable Coefficients Models` are useful when:
Policy Analysis: If a tax policy’s effect differs across states.
Firm Studies: When R&D spending impacts vary by industry.
Efficiency: Use random coefficients if you want to generalize beyond the sample.
Limitations
Fixed Models: Lose efficiency if many groups exist.
Random Models: Require distributional assumptions (e.g., normality).
Data
The Produc dataset (from the plm package) contains U.S. state-level macroeconomic data (1970–1986). We’ll model gross state product (gsp) as a function of public capital (pcap), private capital (pc), employment (emp), and unemployment rate (unemp).
Code
data("Produc", package ="plm")# Convert to panel data formatpdata <-pdata.frame(Produc, index =c("state", "year"))
Fixed Coefficients Model (by State)
Estimate separate coefficients for each state using the pvcm() function with model = "within":
Code
# Fixed coefficients (by state)fe_variable <-pvcm(log(gsp) ~log(pcap) +log(pc) +log(emp) + unemp, data = pdata, model ="within")summary(fe_variable)
Oneway (individual) effect No-pooling model
Call:
pvcm(formula = log(gsp) ~ log(pcap) + log(pc) + log(emp) + unemp,
data = pdata, model = "within")
Balanced Panel: n = 48, T = 17, N = 816
Residuals:
Min. 1st Qu. Median 3rd Qu. Max.
-0.0828078889 -0.0118150348 0.0004246566 0.0126479124 0.1189647497
Coefficients:
(Intercept) log(pcap) log(pc) log(emp)
Min. :-3.708 Min. :-1.4426 Min. :-0.52365 Min. :-0.02584
1st Qu.: 1.229 1st Qu.:-0.5065 1st Qu.:-0.02584 1st Qu.: 0.61569
Median : 2.733 Median :-0.1086 Median : 0.23335 Median : 0.87256
Mean : 2.672 Mean :-0.1049 Mean : 0.21825 Mean : 0.93348
3rd Qu.: 4.214 3rd Qu.: 0.2682 3rd Qu.: 0.41768 3rd Qu.: 1.25307
Max. : 9.338 Max. : 1.0312 Max. : 1.23217 Max. : 2.10582
unemp
Min. :-0.027617
1st Qu.:-0.012080
Median :-0.003905
Mean :-0.003722
3rd Qu.: 0.002948
Max. : 0.029017
Total Sum of Squares: 19352
Residual Sum of Squares: 0.33009
Multiple R-Squared: 0.99998
Each state has its own coefficients (not shown here for brevity).
Use fe_variable$coefficients to view state-specific estimates.
Random Coefficients Model (Swamy’s Model)
Estimate the mean and variance of coefficients across states using model = "random":
Code
# Random coefficients (Swamy’s model)re_variable <-pvcm(log(gsp) ~log(pcap) +log(pc) +log(emp) + unemp, data = pdata, model ="random")summary(re_variable)
Oneway (individual) effect Random coefficients model
Call:
pvcm(formula = log(gsp) ~ log(pcap) + log(pc) + log(emp) + unemp,
data = pdata, model = "random")
Balanced Panel: n = 48, T = 17, N = 816
Residuals:
Min. 1st Qu. Median Mean 3rd Qu. Max.
-0.27874 -0.03826 0.03301 0.03531 0.08882 0.71105
Estimated mean of the coefficients:
Estimate Std. Error z-value Pr(>|z|)
(Intercept) 2.5660617 0.4646077 5.5231 3.331e-08 ***
log(pcap) -0.0786281 0.0890076 -0.8834 0.3770276
log(pc) 0.2124359 0.0569555 3.7299 0.0001916 ***
log(emp) 0.9245679 0.0837552 11.0389 < 2.2e-16 ***
unemp -0.0040549 0.0018892 -2.1464 0.0318437 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Estimated variance of the coefficients:
(Intercept) log(pcap) log(pc) log(emp) unemp
(Intercept) 8.1735012 -1.124405 0.1967614 0.0736650 0.00495130
log(pcap) -1.1244046 0.306534 -0.0874932 -0.1182381 -0.00234697
log(pc) 0.1967614 -0.087493 0.1204141 -0.0871019 -0.00188835
log(emp) 0.0736650 -0.118238 -0.0871019 0.2700516 0.00511478
unemp 0.0049513 -0.002347 -0.0018884 0.0051148 0.00012953
Total Sum of Squares: 19352
Residual Sum of Squares: 12.785
Multiple R-Squared: 0.99934
Chisq: 946.626 on 4 DF, p-value: < 2.22e-16
Test for parameter homogeneity: Chisq = 11425.2 on 235 DF, p-value: < 2.22e-16
Mean coefficients: Average effect across states (similar to pooled OLS but accounts for heterogeneity).
Variance: Measures how much coefficients vary across states.
General Feasible Generalized Least Squares (FGGLS) Models
General Feasible Generalized Least Squares (FGGLS) Models is an estimation technique used to address heteroscedasticity (unequal error variance) and autocorrelation (correlated errors over time/space) in regression models. Unlike OLS, which assumes constant variance and uncorrelated errors, FGLS estimates the error structure from the data and uses it to weight observations, yielding efficient and unbiased coefficients. In panel data, FGLS often models random effects or correlated errors across entities/time.
FGLS Workflow are as follows:
Estimate Initial Model: Fit a model via OLS and extract residuals.
Estimate Error Structure: Use residuals to model heteroscedasticity/autocorrelation (e.g., using variance components).
Re-estimate Model: Apply weights derived from the error structure to compute FGLS estimates.
Key Features of FGLS in Panel Data are as follows:
1.Handles Heteroscedasticity/Autocorrelation: Adjusts standard errors for efficiency.
2. Random Effects: Models unobserved state-specific effects as uncorrelated with regressors (unlike fixed effects).
3. Flexible Covariance Structures: Can model time-series correlation (e.g., AR(1)) with additional arguments.
Comparison with Other Models are as follows: | Model | Pros | Cons | |—————–|——————————————-|——————————————-| | Pooled OLS | Simple, estimates time-invariant variables. | Biased if unobserved heterogeneity exists. | | Fixed Effects | Controls for entity-specific effects. | Inefficient if no autocorrelation/heteroscedasticity. | | FGLS | Efficient, handles complex error structures. | Requires correct specification of error structure. |
Data
In this example, we’ll use the Produc dataset from the plm package, which contains U.S. state-level macroeconomic data (1970–1986). We’ll model gross state product (gsp) as a function of public capital (pcap), private capital (pc), employment (emp), and unemployment rate (unemp).
Fit FGLS Model with pggls()
The pggls() function in plm fits FGLS models for panel data. Use model = "random" for random effects FGLS:
Code
# Fit FGLS model (random effects with general covariance structure)fgls_model <-pggls(log(gsp) ~log(pcap) +log(pc) +log(emp) + unemp,data = pdata,model ="random", # Adjust for random effectseffect ="individual") # State-specific effects# View resultssummary(fgls_model)
Oneway (individual) effect General FGLS model
Call:
pggls(formula = log(gsp) ~ log(pcap) + log(pc) + log(emp) + unemp,
data = pdata, effect = "individual", model = "random")
Balanced Panel: n = 48, T = 17, N = 816
Residuals:
Min. 1st Qu. Median Mean 3rd Qu. Max.
-0.255736 -0.070199 -0.014124 -0.008909 0.039118 0.455461
Coefficients:
Estimate Std. Error z-value Pr(>|z|)
(Intercept) 2.26388494 0.10077679 22.4643 < 2.2e-16 ***
log(pcap) 0.10566584 0.02004106 5.2725 1.346e-07 ***
log(pc) 0.21643137 0.01539471 14.0588 < 2.2e-16 ***
log(emp) 0.71293894 0.01863632 38.2553 < 2.2e-16 ***
unemp -0.00447265 0.00045214 -9.8921 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Total Sum of Squares: 849.81
Residual Sum of Squares: 7.5587
Multiple R-squared: 0.99111
Coefficients:
A 1% increase in private capital (pc) is associated with a 0.31% increase in gross state product (significant at 1%).
Theta (0.752): Weight given to between-state variation vs. within-state variation.
Summary and Conclusions
This tutorial demonstrated how to perform panel linear regression using the {plm} package in R. Panel regression is a statistical technique used to analyze datasets that combine both cross-sectional and time-series data, known as panel data or longitudinal data. This method accounts for multiple observations of the same entities (e.g., individuals, firms, countries) over time, enabling researchers to control for variables that vary across entities or time periods but are unobserved or unmeasured. We covered different types of linear panel regression models, including Pooled OLS, Fixed Effects, Random Effects, Dynamic Panel Regression, Variable Coefficients Model, and General Feasible Generalized Least Squares (FGLS) Models. Each model has its own assumptions, advantages, and limitations, making it suitable for different research questions and data structures. By using panel regression techniques, researchers can obtain more accurate and reliable estimates of the relationships between variables in panel data, leading to better insights and policy recommendations.