Conditional survival analysis is a statistical method used to estimate the probability of surviving a specific period of time given that a patient has already survived a certain amount of time. This method is particularly useful in cancer research, where patients may have already survived for a certain period after diagnosis or treatment. Conditional survival analysis can provide more accurate estimates of survival probabilities by taking into account the time that has already elapsed since diagnosis or treatment.
Overview
Ordered multivariate failure time data refers to datasets where multiple failure times are recorded for each subject, and these times have a natural order (e.g., times to successive events for the same subject). The conditional survival function in this context represents the probability of surviving beyond a specific time point for one event, given the survival status of previous events.
Let \(T_1, T_2, \ldots, T_k\) denote the ordered failure times for a subject, where \(T_1 \leq T_2 \leq \ldots \leq T_k\).
The conditional survival function for the \(j\)-th failure time, \(T_j\), given that the first \(i\) events have already occurred (i.e., \(T_1, T_2, \ldots, T_i \leq t\)), is defined as:
Modeling times to recurrent events (e.g., cancer relapse).
Estimating survival probabilities for successive treatments.
Reliability Engineering:
Time to failure for components in a system with dependent failure risks.
Actuarial Science:
Modeling dependent life events in joint-life insurance policies.
This framework combines the joint survival function and marginal survival to provide dynamic risk assessments in multivariate contexts.
Conditional Survival Analysis in R
The {condSURV} package in R provides a comprehensive set of tools for estimating the conditional survival function for ordered multivariate failure time data. This package is particularly useful for analyzing survival data in the presence of multiple events, where the occurrence of one event may affect the risk of subsequent events. This package allows to estimation of the (conditional) survival function for ordered multivariate failure time data.
We will use the colonCS data set from the condSURV package which contains data from a a large clinical trial on Duke’s stage II patients with colon cancer that underwent a curative surgery for colorectal cancer Out of a total of 929 patients, 468 experienced a recurrence, and of those, 414 died. For each patient, key data was recorded, including their final vital status (whether censored or not), survival times (time to recurrence and time to death measured in days from the start of the study), and a set of covariates such as age (in years) and recurrence status (coded as 1 for yes and 0 for no). It’s important to note that the recurrence covariate is a time-dependent variable that can be considered an intermediate event.
The data frame clononCS consists of 16 variables and 686 observations. Cancer clinical trials provide numerous examples of methods used for analyzing time-to-event data.
A data frame with 929 observations on the following 15 variables. Below a brief description is given for some of these variables.
time1: Time to recurrence/censoring/death, whichever occurs first.
The individuals mentioned in lines 1, 3, 4, 5, and 6 have unfortunately faced a recurrence of their tumors and have subsequently died as a result. In contrast, the individual represented in line 2 is currently alive and has shown no signs of recurrence by the conclusion of the follow-up period. It is important to note that when we refer to “event1 = 1,” we are indicating those individuals who experienced a recurrence but are still alive at the end of the follow-up. Conversely, “event = 0” signifies individuals who have not had any recurrence of their tumors.
Survival Object and Conditional Survival Probabilities
The survCS() function in the {condSURV} package creates a survival object based on the selected variables for analysis. This function checks whether the data has been entered correctly and generates a survCS object. The arguments for this function must be provided in the following order: time1, event1, time2, event2, …, Stime, and event, where time1, time2, …, Stime represent the ordered event times, and event1, event2, …, event are their corresponding indicator statuses. This function serves a similar purpose to the Surv() function in the {survival} package.
Recurrence profoundly impacts patient outcomes, significantly influencing the course of treatment and survival rates. To better understand this impact, we can analyze ordered multivariate event time data that tracks the timeline from patient enrollment to the occurrence of cancer recurrence and ultimately to death. By estimating the conditional survival probabilities, which are mathematically represented as \(S(y | x) = P(T > y | T_1 > x)\), we can gain valuable insights into the prognosis of patients who have undergone surgery for cancer. This approach allows us to identify those individuals who, despite not experiencing a recurrence of cancer, have a higher likelihood of surviving their illness over time. The findings generated from this analysis can play a crucial role in clinical decision-making. They can guide healthcare providers in tailoring personalized care plans for patients, determining who may require more frequent follow-ups and intensified monitoring. This can ultimately enhance the quality of care and support improved survival outcomes for patients navigating their cancer journey.
You can estimate conditional survival probabilities using the survCOND() function. Start by providing a formula, with the response on the left side of the tilde (~) symbol. This response needs to be a “survCS” object, which you create with the survCS() function. You can add one covariate - either qualitative or quantitative - on the right side of the formula. This allows you to estimate survival probabilities based on current or past covariate measures. In the absence of covariates, researchers can utilize two primary methods to estimate conditional survival probabilities. The first method is based on Kaplan-Meier weights (KMW), which allow for the calculation of survival probabilities by accounting for censored data and providing a step function that estimates survival over time. The second method employs the landmarkapproach, which focuses on specific time points, using data from patients who have survived up to those points to estimate survival probabilities moving forward. Moreover, a smoothed version of the landmark approach is also available, which employs statistical techniques to produce a more refined and continuous estimate of survival probabilities over time. This smoothing can help to reduce the variability in estimates and provide clearer insights into survival trends.
Kaplan-Meier Weights
First, we estimate the survival probability \(S(y | x) = P(T > y | T_1 > x)\) given \(x = 365\) (one year) and \(y = 1825\) (five years). We use the function survCOND() with the method based on Kaplan-Meier weights (method = "KMW").
Code
# set seed for reproducibilityset.seed(123)# Conditional survival probabilitiescolon.kmw.1<-survCOND(survCS(time1, event1, Stime, event) ~1, x =365, y =1825,data = colonCS,method ="KMW")# summarysummary(colon.kmw.1)
P(T>y|T1>365)
y estimate lower 95% CI upper 95% CI
1825 0.7303216 0.7003249 0.7643409
The output provides the estimated conditional survival probabilities from one year to five years, along with the 95% confidence intervals (conf = TRUE) using 200 bootstrap replicates (n.boot = 200). The results indicate that the estimated survival probability at one year is 0.73, with a 95% confidence interval of [0.70, 0.76].
When a specific value of \(x\), estimates for conditional survival rates can be derived for a vector of \(y\) values. This process allows us to analyze how survival probabilities change with time. In the following example, we will illustrate this concept by providing a detailed analysis of the estimated conditional survival associated with a given \(x\) value across a range of corresponding \(y\) values.
The landmark approach is another method for estimating conditional survival probabilities. This method focuses on specific time points, using data from patients who have survived up to those points to estimate survival probabilities moving forward. The landmark approach is particularly useful when researchers want to assess survival probabilities at specific time points, such as one year, two years, or five years after a particular event. This method allows for a more focused analysis of survival trends at key time intervals, providing valuable insights into patient prognosis and treatment outcomes.
You can estimate the conditional survival probability \(S(y | x) = P(T > y | T_1 > x)\) using landmark methods, specifically LDM (landmark method) and PLDM (presmoothed landmark method), using the same function, survCOND(). To calculate the unsmoothed landmark estimator, set the argument method = "LDM".
Code
colon.ldm.1<-survCOND(survCS(time1, event1, Stime, event) ~1, x =365,data = colonCS, method ="LDM")summary(colon.ldm.1, times =365*1:7) # summary for 1 to 7 years
If are interested in calculating the conditional survival function, denoted as \(S(y | x) = P(T > y | T_1 \leq x)\). This function represents the probability that an individual is alive at time \(y\), given that they were alive with a recurrence at a prior time \(x\). This quantity can also be estimated using the function survCOND() by setting the argument lower.tail = TRUE.
It’s important to note that, for a given value of x, setting lower.tail = TRUE offers survival estimates based on the condition \(T1 ≤ x\). In contrast, setting lower.tail = FALSE provides survival estimates under the condition \(T1 > x\). Additionally, it’s worth mentioning that the default behavior of survCOND() is to condition on \(T1 > x\).
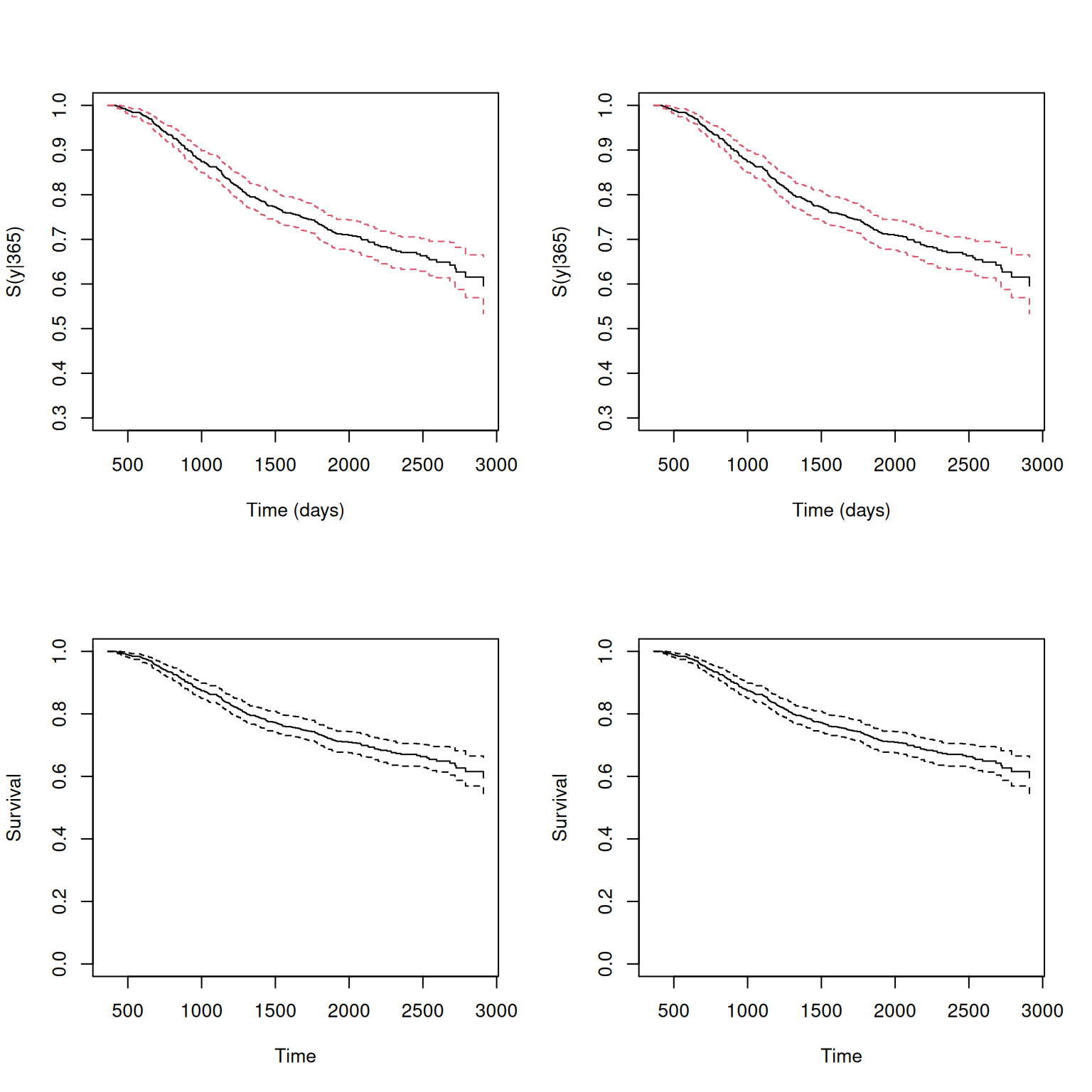
The plot() function can be used to visualize the estimated conditional survival probabilities. The function plot() can be applied to the output of the survCOND() function to generate a plot of the estimated conditional survival probabilities. The plot() function allows you to customize the appearance of the plot by specifying the color of the lines, the confidence intervals, the x-axis label, the y-axis label, and the y-axis limits. You can also adjust the layout of the plot using the par() function to create multiple plots in a single window.
When comparing the results from the two methods, LDM and PLDM, it is evident that the semiparametric estimator, PLDM, exhibits less variability, particularly at the right tail where it has more jump points. Additionally, the semiparametric estimator tends to yield higher values at the right tail. This is because the PLDM method employs a smoothing technique that reduces the variability in the estimates, resulting in a more continuous and refined estimate of the conditional survival probabilities over time. This smoothing process helps to produce a more accurate representation of the survival trends, making it easier to interpret the results and draw meaningful conclusions from the data.
Conditional Survival Probabilities with Covariates
The survCOND() function can also be used to estimate conditional survival probabilities with covariates. This allows you to assess how different factors influence the survival outcomes of patients over time. By including covariates in the analysis, you can identify the key predictors that impact patient prognosis and tailor treatment strategies accordingly. The conditional survival probabilities can be estimated based on the covariate values, providing valuable insights into the relationship between the covariates and survival outcomes.
Conditional Survival Probabilities with Treatment Covariate (rx)
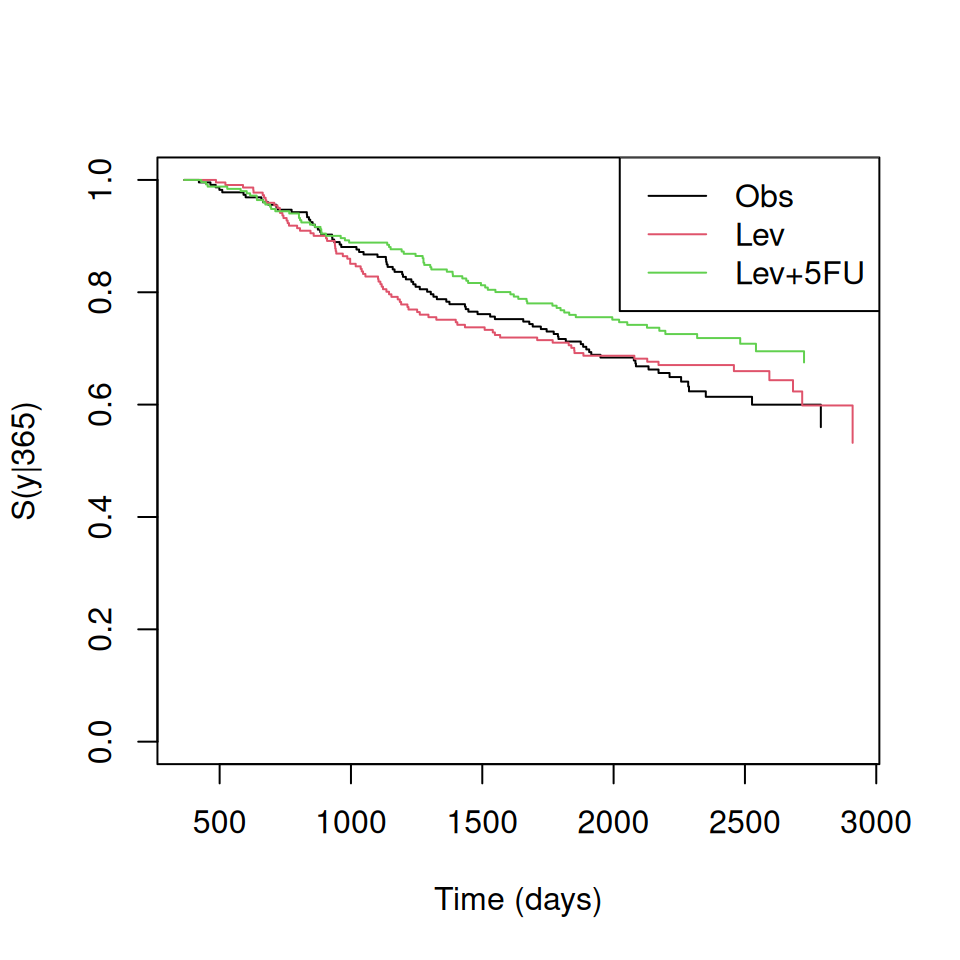
The current version of the {condSURV} package allows for the inclusion of a single covariate. The following input commands provide estimates of the conditional survival function \(S(y | x) = P(T > y | T_1 > x)\) for the three treatment groups by incorporating the covariate (rx) on the right-hand side of the formula argument:
Code
colon.rx.ldm <-survCOND(survCS(time1, event1, Stime, event) ~ rx, x =365,data = colonCS,method ="LDM")summary(colon.rx.ldm, times =365*1:6)
The results show that the estimated conditional survival probabilities for the three treatment groups (Obs, Lev, Lev+5-FU) from one year ato six years. The confidence intervals for these estimates are also provided, allowing for a more comprehensive interpretation of the results. By including covariates in the analysis, researchers can gain valuable insights into how different factors influence patient survival outcomes and tailor treatment strategies accordingly.
We can plot the estimated conditional survival probabilities for the three treatment groups using the plot() function.
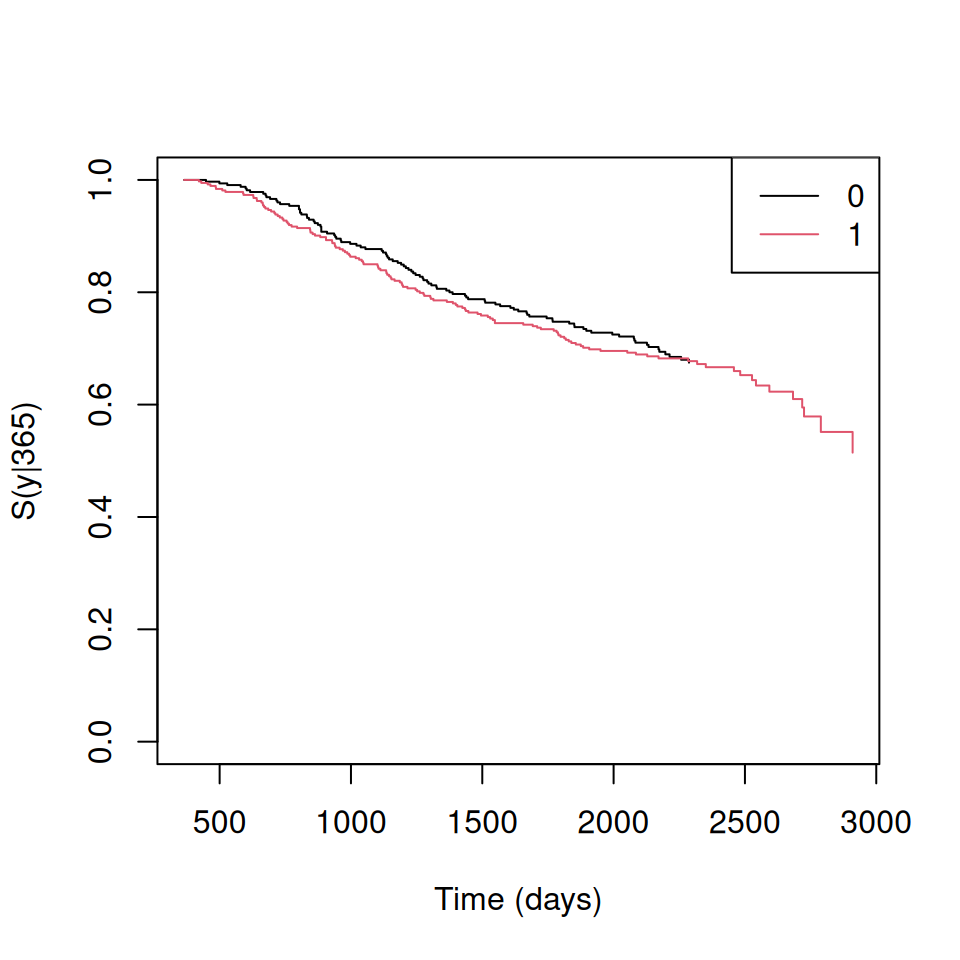
Conditional Survival Probabilities for Male and Female Patients
We one can obtain the corresponding survival probabilities \(S(y | x) = P(T > y|T_1 ≤ x)\) forboth genders (1 – male). Since this variable in the data.frame colonCS is of class “integer” it must be included in the formula using function factor.
Code
colon.sex.ldm <-survCOND(survCS(time1, event1, Stime, event) ~factor(sex), x =365,data = colonCS, method ="LDM")summary(colon.sex.ldm, times =365*1:6)
Conditional Survival Probabilities with Age Covariate
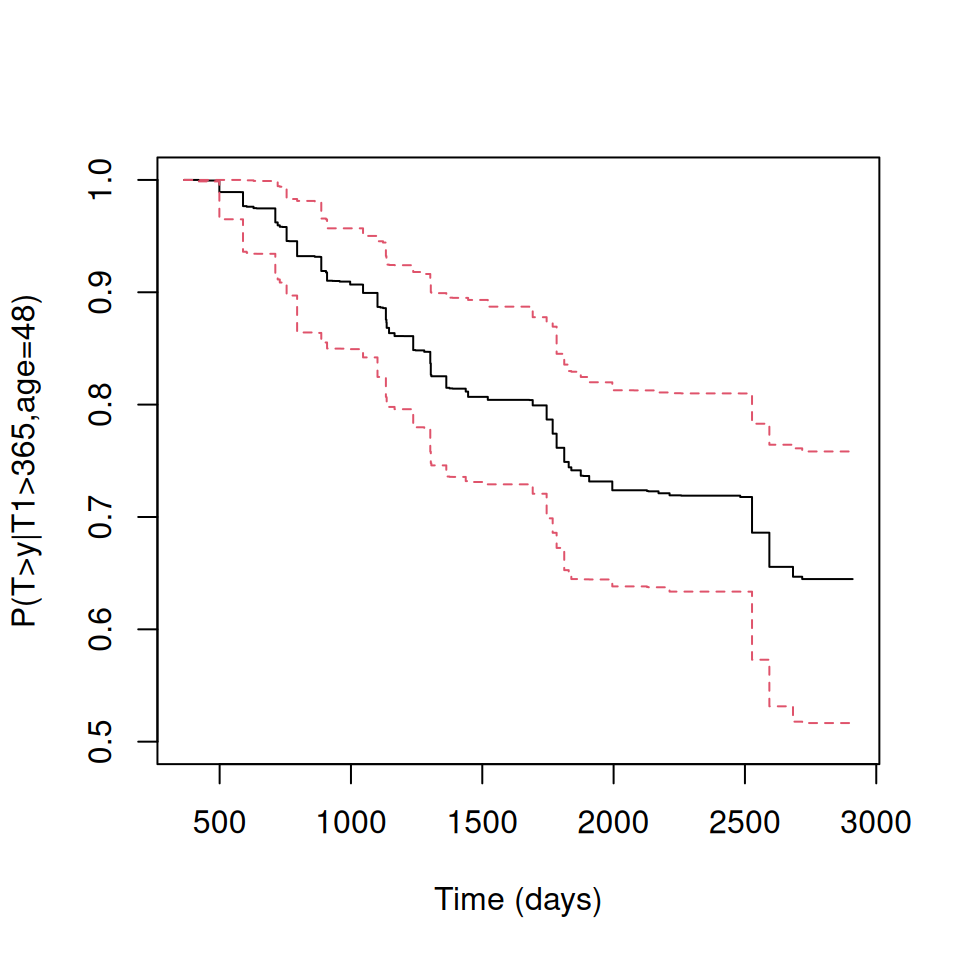
The {condSURV} package enables users to estimate conditional survival based on a continuous covariate, which can be of class “integer” or “numeric”. For instance, the estimates and plots for conditional survival can be computed for individuals aged 48 years, represented as \(S(y|x, Z = z) = P(T > y | T_1 > x, age = 48)\).
Code
colon.ipcw.age <-survCOND(survCS(time1, event1, Stime, event) ~ age,x =365,z.value =48, data = colonCS, lower.tail =FALSE)summary(colon.ipcw.age, times =365*1:7)
This tutorial has provided an overview of conditional survival analysis for ordered multivariate failure time data using the {condSURV} package in R. We have demonstrated how to estimate the conditional survival function for ordered multivariate failure time data and how to interpret the results. By analyzing the conditional survival probabilities, researchers can gain valuable insights into the prognosis of patients who have undergone surgery for cancer and identify those individuals who have a higher likelihood of surviving their illness over time. This information can be used to guide clinical decision-making and tailor personalized care plans for patients, ultimately improving survival outcomes.