3.4. Mutilevel or Mixed Effect Poisson Model (MLPM)
Multi-level count data is commonly found in ecology, epidemiology, and social sciences, representing occurrences like disease cases or animal sightings. When this data is clustered or hierarchical, mixed-effects Poisson models offer a robust analytical framework. This tutorial provides an overview of mixed-effects Poisson models for count data and step-by-step instructions for fitting these models in R, highlighting the underlying principles. We will also explore several R packages, including {lme4}, {glmmTMB}, and {MASS}, to fit various Poisson models, with a particular emphasis on managing overdispersion using quasi-Poisson and negative binomial models. By the end of this tutorial, readers will gain theoretical knowledge and practical skills to analyze count data effectively, enabling informed, data-driven decision-making.
Overview
A mixed-effects Poisson model is a type of regression model used to analyze count data while accounting for both fixed effects (effects that are constant across observations) and random effects (effects that vary across groups or clusters). This model is widely used in fields such as biostatistics, epidemiology, and ecology to analyze data with hierarchical or clustered structures.
Model Description:
The general form of a mixed-effects Poisson model can be written as:
\(X_{ij}\) is a vector of fixed-effect covariates for the \(i\)-th observation in the \(j\)-th group.
\(\beta\) is the vector of fixed-effect coefficients (parameters).
\(Z_j\) is a vector of random-effect covariates associated with the \(j\)-th group.
\(u_j\) is the random-effect vector for the \(j\)-th group, typically assumed to follow a multivariate normal distribution: \(u_j \sim N(0, \Sigma_u)\).
Key Components:
Fixed Effects (\(X_{ij}^T \beta\)):
Represent the population-level effects that are consistent across all groups.
For example, the effect of a treatment or other covariates like age or gender.
Random Effects (\(Z_j^T u_j\)):
Capture the group-specific variability.
Allow for the inclusion of cluster-level heterogeneity.
Poisson Assumption:
The response variable \(Y_{ij}\) is assumed to follow a Poisson distribution with mean \(\lambda_{ij}\).
Variance equals the mean in a standard Poisson model, but overdispersion (variance greater than the mean) can be handled by extending the model (e.g., using a negative binomial distribution).
\(\beta_k\) are fixed-effect coefficients for covariates \(X_{ijk}\).
\(u_{jm}\) are random effects for covariates (Z_{ijm}).
Variance-Covariance Structure
The random effects, (u_j), are assumed to follow a multivariate normal distribution:
\[ u_j \sim N(0, \Sigma_u) \]
where \(\Sigma_u\) is the variance-covariance matrix that describes the structure of the random effects.
Inference and Estimation:
Parameters $$ (fixed effects) and \(\Sigma_u\) (random effects variance-covariance) are typically estimated using maximum likelihood estimation (MLE) or Bayesian methods.
Numerical techniques like Laplace approximation or Gauss-Hermite quadrature are often used due to the complexity of the likelihood function.
Multilevel Poisson Model from Scratch
Fitting a multilevel Poisson model from scratch in R without relying on any specific packages is a computationally intensive task, as it requires implementing iterative optimization for the likelihood function. Below is a step-by-step implementation outline:
Simulated Hierarchical Data: Simulate or provide hierarchical count data with fixed and random effects.
Model Specification: Specify the likelihood function for a Poisson distribution with both fixed and random effects.
Optimization: Use numerical methods like gradient descent or Newton-Raphson to optimize the parameters.
Estimation of Random Effects: Use an iterative approach to account for random effects (e.g., via the expectation-maximization (EM) algorithm).
Simulated Hierarchical Data
Let’s start by simulating hierarchical count data with fixed and random effects. We will generate a dataset with multiple groups, each containing observations with a Poisson-distributed response variable. The data will include a covariate (e.g., age) and group-level random effects.
Code
# Step 1: Simulate Example Dataset.seed(123)# Number of groups and observations per groupn_groups <-10n_obs_per_group <-50# Fixed effect parametersbeta_0 <-1.5# Interceptbeta_1 <-0.3# Slope for fixed effect (e.g., covariate effect)# Random effect standard deviationsigma_u <-0.5# Generate group-level random effectsgroup_ids <-rep(1:n_groups, each = n_obs_per_group)u <-rnorm(n_groups, mean =0, sd = sigma_u)# Covariate (e.g., age)x <-runif(n_groups * n_obs_per_group, 0, 10)# Generate response variable (Poisson counts)lambda <-exp(beta_0 + beta_1 * x + u[group_ids])y <-rpois(n_groups * n_obs_per_group, lambda)# Data framedata <-data.frame(group = group_ids, x = x, y = y)head(data)
group x y
1 1 8.895393 45
2 1 6.928034 17
3 1 6.405068 29
4 1 9.942698 85
5 1 6.557058 31
6 1 7.085305 27
Log-Likelihood Function
Next, we define the log-likelihood function for the mixed-effects Poisson model. The function takes the model parameters (fixed effects, random effects, and variance of random effects) as input and returns the negative log-likelihood value to be minimized during optimization. The log-likelihood consists of two components: the Poisson log-likelihood for the response variable and the log-likelihood for the random effects (prior distribution). The random effects are assumed to follow a normal distribution with mean 0 and variance \(\sigma_u^2\). The total log-likelihood is the sum of these two components.
Code
# Step 2: Log-Likelihood Functionlog_likelihood <-function(params) { beta_0 <- params[1] # Intercept (fixed effect) beta_1 <- params[2] # Covariate effect (fixed effect) sigma_u <-exp(params[3]) # Variance of random effects (positive)# Extract group-level random effects u <- params[4:(3+ n_groups)]# Calculate linear predictor eta <- beta_0 + beta_1 * data$x + u[data$group]# Poisson log-likelihood ll <-sum(data$y * eta -exp(eta))# Random effect log-likelihood (prior) ll_random <-sum(dnorm(u, mean =0, sd = sigma_u, log =TRUE))# Total log-likelihoodreturn(-(ll + ll_random)) # Return negative for minimization}
Optimize Parameters using optim() and fit the model
We use the optim() function to optimize the log-likelihood function and estimate the fixed and random effects parameters. The initial values for the parameters are set based on prior knowledge or random values. The optimization method (e.g., BFGS) and control parameters (e.g., maximum iterations) can be specified to fine-tune the optimization process.
Finally, we extract the estimated fixed effects, random effects, and variance of random effects from the optimization results. These estimates provide insights into the relationships between the covariates and the response variable, as well as the variability across groups.
Multilevel Poisson models can be fitted using various R packages that provide robust and efficient implementations for analyzing hierarchical count data. In this section, we will demonstrate how to fit mixed-effects Poisson models using the {lme4}, {glmmTMB}, and {MASS} packages in R, highlighting the key steps involved in the modeling process.
Install Required R Packages
Following R packages are required to run this notebook. If any of these packages are not installed, you can install them using the code below:
In this section we use the Salamanders data set from the {glmmTMB} package. The data set containing counts of salamanders with site covariates and sampling covariates. Each of 23 sites was sampled 4 times. (Price et al. (2016); Price et al. 2015).
A data frame with 644 observations on the following 10 variables:
site: name of a location where repeated samples were taken
mined: factor indicating whether the site was affected by mountain top removal coal mining
cover: amount of cover objects in the stream (scaled)
sample: repeated sample
DOP:Days since precipitation (scaled)
Wtemp:water temperature (scaled)
DOY:day of year (scaled)
spp:abbreviated species name, possibly also life stage
count:number of salamanders observed
Price SJ, Muncy BL, Bonner SJ, Drayer AN, Barton CD (2016) Effects of mountaintop removal mining and valley filling on the occupancy and abundance of stream salamanders. Journal of Applied Ecology 53 459–468. doi:10.1111/1365-2664.12585
Price SJ, Muncy BL, Bonner SJ, Drayer AN, Barton CD (2015) Data from: Effects of mountaintop removal mining and valley filling on the occupancy and abundance of stream salamanders. Dryad Digital Repository. doi:10.5061/dryad.5m8f6
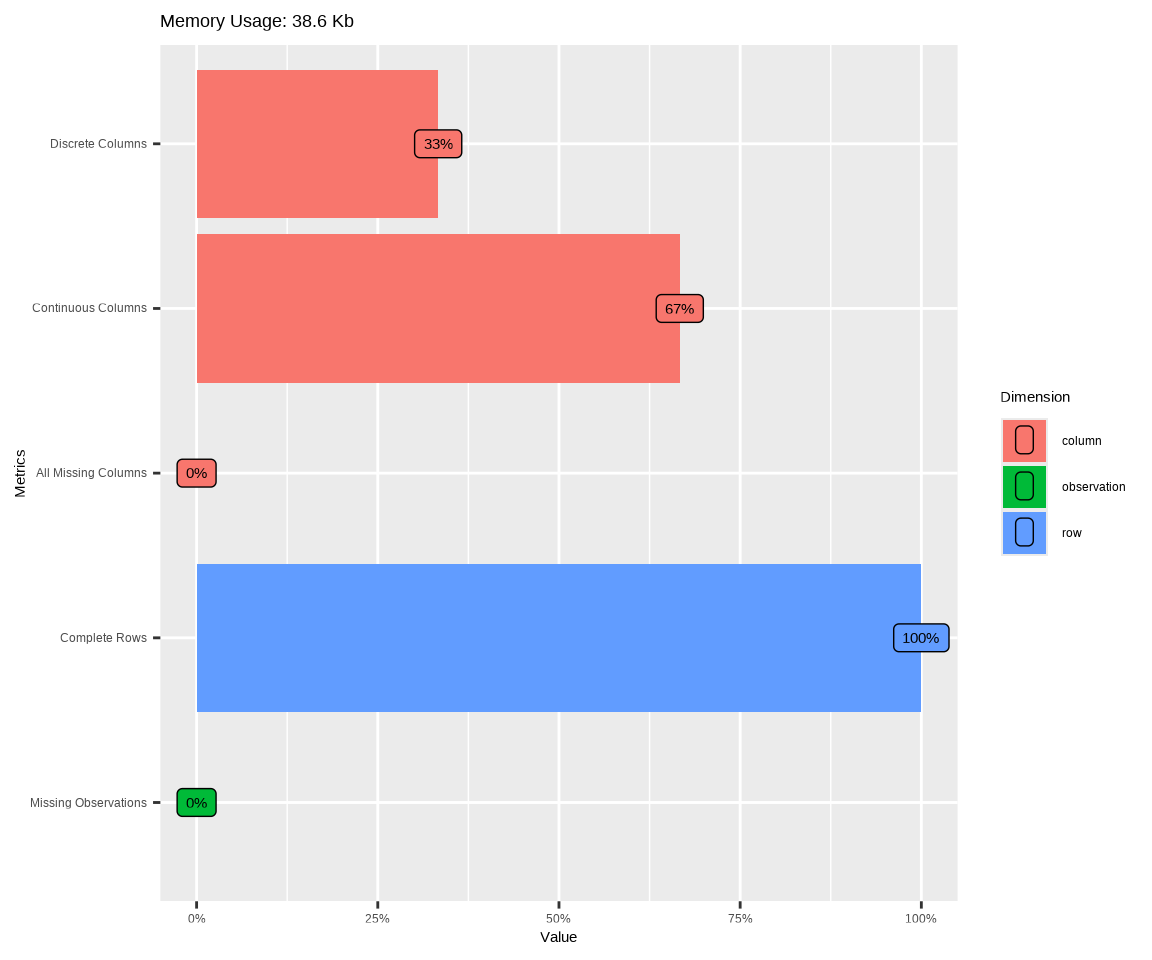
DataExplorer::plot_intro() plot basic information (from introduce) for input data.
Code
mf |> DataExplorer::plot_intro()
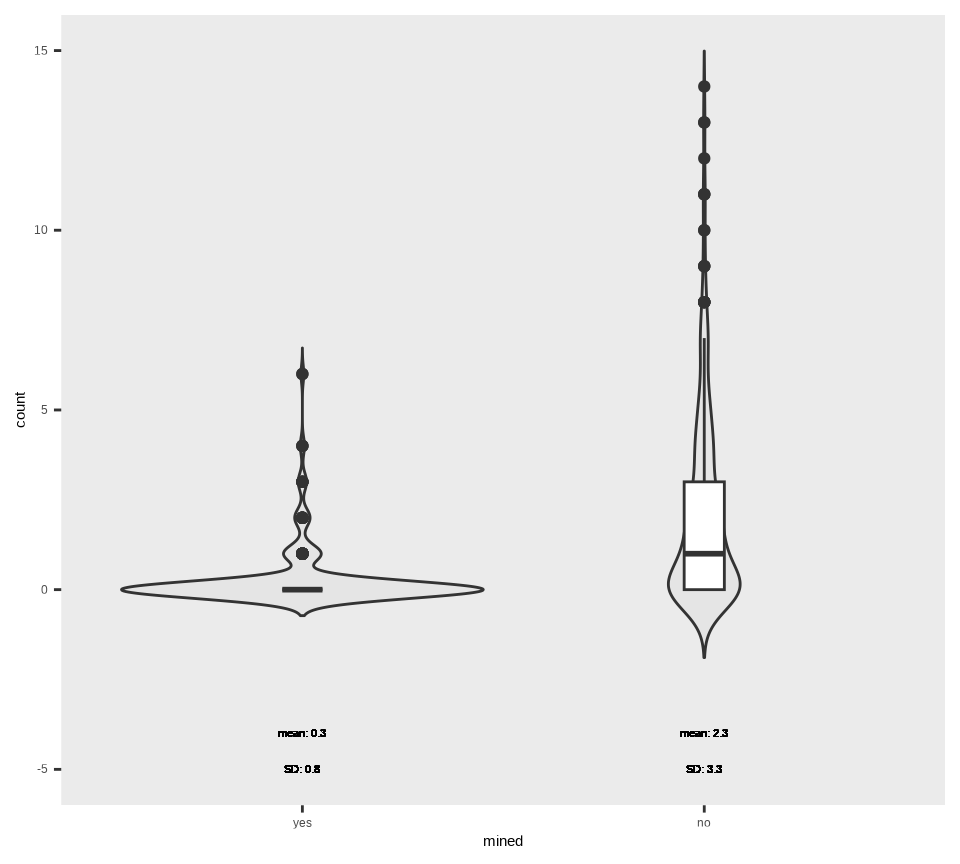
Distribution of the count variable in mined setting is shown below
Code
# output the resultsmf %>%# prepare data dplyr::select(mined, count) %>% dplyr::group_by(mined) %>% dplyr::mutate(Mean =round(mean(count), 1)) %>% dplyr::mutate(SD =round(sd(count), 1)) %>%# start plotggplot(aes(mined, count, color = mined, fill = mined)) +geom_violin(trim=FALSE, color ="gray20")+geom_boxplot(width=0.1, fill="white", color ="gray20") +geom_text(aes(y=-4,label=paste("mean: ", Mean, sep ="")), size =3, color ="black") +geom_text(aes(y=-5,label=paste("SD: ", SD, sep ="")), size =3, color ="black") +scale_fill_manual(values=rep("grey90",4)) +theme_set(theme_bw(base_size =10)) +theme(legend.position="none", legend.title =element_blank(),panel.grid.major =element_blank(),panel.grid.minor =element_blank()) +ylim(-5, 15) +labs(x ="mined", y ="count")
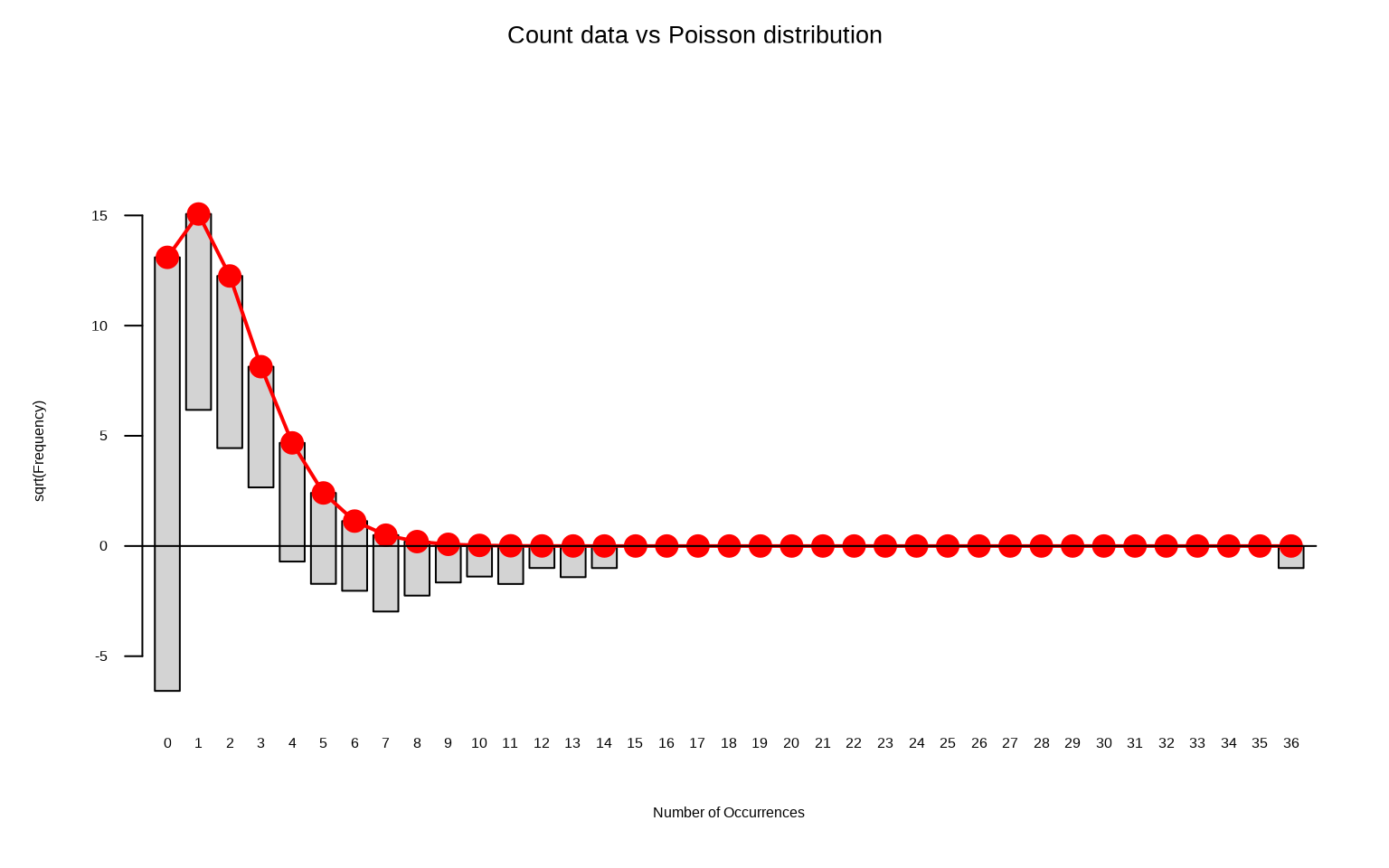
Goodness-of-fit Tests
Code
gf = vcd::goodfit(mf$count,type="poisson", method="ML")plot(gf, main="Count data vs Poisson distribution")
The data does not perfectly match a Poisson distribution. We will use a goodness-of-fit test to determine if it significantly diverges from this distribution. A p-value less than .05 indicates a significant difference, suggesting the data is likely over-dispersed.
Code
summary(gf)
Goodness-of-fit test for poisson distribution
X^2 df P(> X^2)
Likelihood Ratio 958.8815 14 1.032889e-195
The p-value is indeed smaller than .05 which means that we should indeed use a negative-binomial model rather than a Poisson model. We will ignore this, for now, and proceed to fit a Poisson mixed-effects model and check what happens if a Poisson model is fit to over-dispersed data.
Mixed Effect Poisson Models
To analyze the Salamanders dataset from the {glmmTMB} package using different types of Poisson models with the {lme4} package, you can follow these steps. Here’s a detailed approach to fit fixed-effects, random-effects, and nested random-effects Poisson models.
We will fit the following models to the Salamanders dataset to model the count of salamanders observed using the cover, mined and spp variables:
Fixed-Effects Poisson Model
This model assumes only fixed effects without any grouping structure.
Code
# Fixed-effects Poisson modelmodel_fixed <-glm(count ~ mined + spp + cover, data = mf, family ="poisson")summary(model_fixed)
Call:
glm(formula = count ~ mined + spp + cover, family = "poisson",
data = mf)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.49204 0.14129 -10.560 < 2e-16 ***
minedno 2.29902 0.12005 19.151 < 2e-16 ***
sppPR -1.38629 0.21517 -6.443 1.17e-10 ***
sppDM 0.23052 0.12889 1.789 0.0737 .
sppEC-A -0.77011 0.17105 -4.502 6.73e-06 ***
sppEC-L 0.62117 0.11931 5.206 1.92e-07 ***
sppDES-L 0.67916 0.11813 5.749 8.96e-09 ***
sppDF 0.08004 0.13344 0.600 0.5486
cover -0.23087 0.04136 -5.582 2.37e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 2120.7 on 643 degrees of freedom
Residual deviance: 1278.9 on 635 degrees of freedom
AIC: 2020.1
Number of Fisher Scoring iterations: 6
Random-Intercept Model
This model includes a random intercept for the site.
Code
# Random-intercept Poisson modelmodel_random_intercept <-glmer(count ~ mined + spp + cover + (1| site), data = Salamanders, family ="poisson")summary(model_random_intercept)
The \(R^2\) values of the are incorrect (as indicated by the missing conditional \(R^2\) value). The more appropriate conditional and marginal coefficient of determination for generalized mixed-effect models can be extracted using the r.squaredGLMM () function from the {MuMIn} package (Barton 2020).
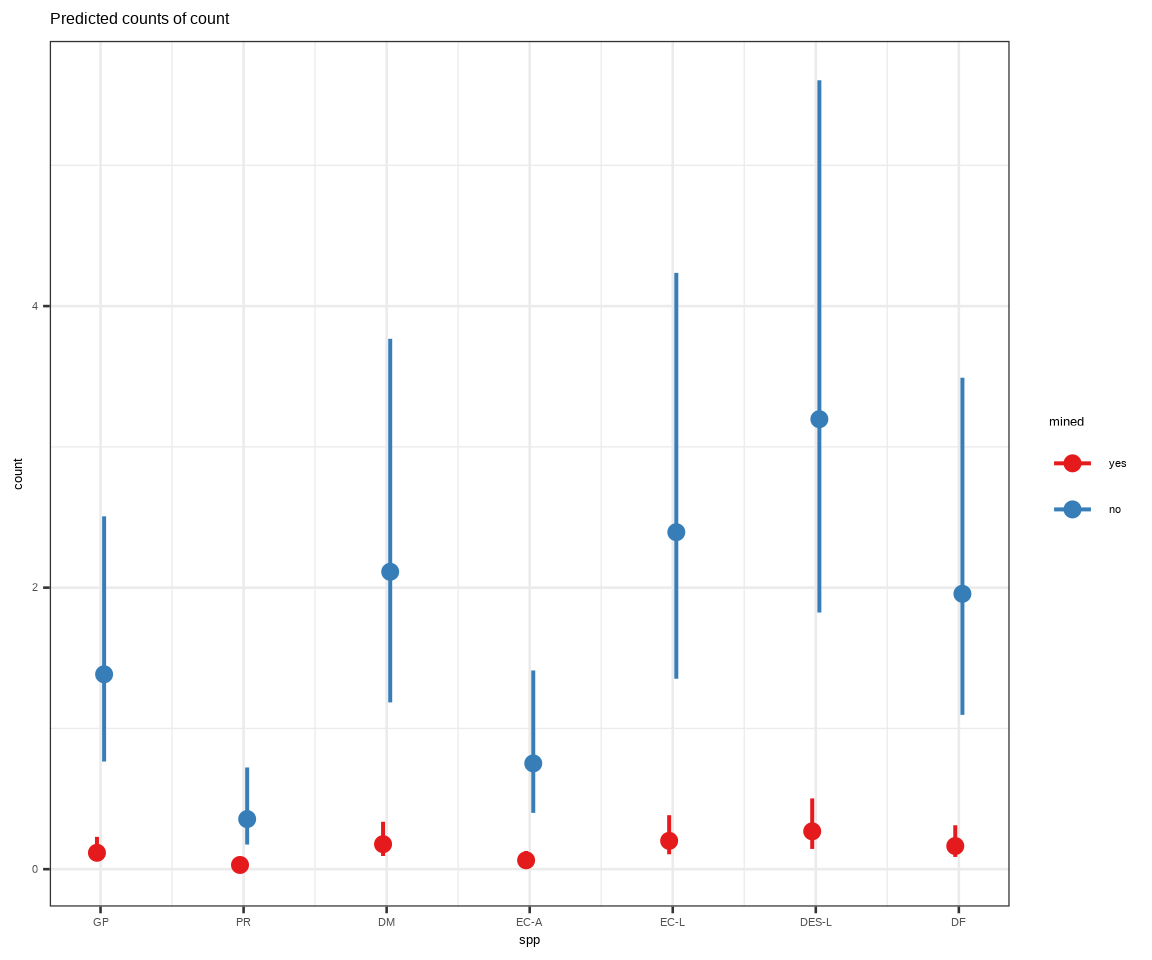
plot_model() of {sjPlot} creates plots from regression models, either estimates (as so-called forest or dot whisker plots) or marginal effects.
Code
plot_model(model_nested, type ="pred", terms =c("spp", "mined"), show.values =TRUE)
You are calculating adjusted predictions on the population-level (i.e.
`type = "fixed"`) for a *generalized* linear mixed model.
This may produce biased estimates due to Jensen's inequality. Consider
setting `bias_correction = TRUE` to correct for this bias.
See also the documentation of the `bias_correction` argument.
Mixed-Effect Models for Overdispersed Count Data
When analyzing count data, overdispersion is a common issue where the variance of the outcome variable exceeds the mean. This can lead to biased parameter estimates and incorrect inferences if not properly addressed. In this section, we will demonstrate how to fit mixed-effects regression models for overdispersed count data. First we check for overdispersion in the Poisson model and then adjust for overdispersion using the quasi-Poisson approximation or fit a negative binomial model as an alternative.
Check for Overdispersion
Check for overdispersion of model_nested by calculating the ratio of the residual deviance to the degrees of freedom:
Code
# Check overdispersionoverdispersion_ratio <-sum(residuals(model_nested, type ="pearson")^2) /df.residual(model_nested)cat("Overdispersion ratio:", overdispersion_ratio, "\n")
Overdispersion ratio: 1.153974
If the overdispersion ratio is significantly greater than 1, overdispersion is present.
Or we can use the performance::check_overdispersion() function to check for overdispersion in the model_nested.
Code
performance::check_overdispersion(model_nested)
# Overdispersion test
dispersion ratio = 1.154
Pearson's Chi-Squared = 730.465
p-value = 0.004
Overdispersion detected.
Adjust for Overdispersion in the Poisson Model (Quasi-Poisson Approximation)
The quasi-Poisson approach is used to handle overdispersion (variance greater than the mean) in count data. However, the {lme4} package does not directly support quasi-Poisson models because it is based on maximum likelihood estimation (which does not accommodate quasi-likelihood models). To address overdispersion in a Poisson model, we can adjust the standard errors post hoc using the overdispersion ratio.
To account for overdispersion, fit a quasi-Poisson model using the glmmPQL() function of {MASS} package. The quasi-Poisson model is a generalized linear mixed model that relaxes the assumption of equal mean and variance in Poisson regression, making it suitable for overdispersed count data.
Code
# Quasi-Poisson mixed-effects modelmodel_quasi_poisson <- MASS::glmmPQL(count ~ mined + spp + cover, random =~1| site, data = mf, family =quasipoisson(link='log'))summary(model_quasi_poisson)
Linear mixed-effects model fit by maximum likelihood
Data: mf
AIC BIC logLik
NA NA NA
Random effects:
Formula: ~1 | site
(Intercept) Residual
StdDev: 0.2888095 1.5873
Variance function:
Structure: fixed weights
Formula: ~invwt
Fixed effects: count ~ mined + spp + cover
Value Std.Error DF t-value p-value
(Intercept) -1.4630935 0.2478870 615 -5.902259 0.0000
minedno 2.2211941 0.2489954 20 8.920625 0.0000
sppPR -1.3862944 0.3439443 615 -4.030578 0.0001
sppDM 0.2305237 0.2060291 615 1.118889 0.2636
sppEC-A -0.7701082 0.2734303 615 -2.816470 0.0050
sppEC-L 0.6211737 0.1907148 615 3.257082 0.0012
sppDES-L 0.6791609 0.1888278 615 3.596722 0.0003
sppDF 0.0800427 0.2133052 615 0.375250 0.7076
cover -0.1686904 0.1105425 20 -1.526023 0.1427
Correlation:
(Intr) minedn sppPR sppDM spEC-A spEC-L sDES-L sppDF
minedno -0.722
sppPR -0.278 0.000
sppDM -0.463 0.000 0.334
sppEC-A -0.349 0.000 0.252 0.420
sppEC-L -0.500 0.000 0.361 0.602 0.454
sppDES-L -0.505 0.000 0.364 0.608 0.458 0.657
sppDF -0.447 0.000 0.322 0.538 0.406 0.582 0.587
cover 0.278 -0.498 0.000 0.000 0.000 0.000 0.000 0.000
Standardized Within-Group Residuals:
Min Q1 Med Q3 Max
-1.59244712 -0.45929426 -0.32368772 0.09159159 7.69097201
Number of Observations: 644
Number of Groups: 23
Fit a Negative Binomial Model (Alternative for Overdispersion)
Negative binomial regression models extend the framework of Poisson regression by addressing a critical limitation inherent in the Poisson approach: the assumption that the variance of the outcome variable is equal to its mean. This assumption can often lead to poor model fit, especially when the data exhibit overdispersion — where the observed variance significantly exceeds the mean. By allowing for greater flexibility in modeling the relationship between the dependent and independent variables, negative binomial regression provides a robust alternative when dealing with count data that do not conform to the strict requirements of the Poisson distribution, making it particularly useful in real-world scenarios where data often show considerable variability.
A negative binomial model can handle overdispersion more directly. First we use {glmmTMB} to fit a negative binomial models. Two parameterisations are often used to fit negative binomial regression models (see Hilbe (2011Hilbe, Joseph M. 2011. Negative Binomial Regression. Cambridge University Press. https://doi.org/10.1017/CBO9780511973420.)):
NB1 (variance = \(μ\) + \(αμ\)); and,
NB2 (variance = \(μ+αμ^2\)); where \(μ\) is the mean, and αα is the overdispersion parameter
NB1 Parameterization
Code
# Negative binomial mixed-effects modelmodel_negbinom_01 <-glmmTMB(count ~ mined + spp + cover+(1| site / spp), data = mf, family = nbinom1)# model summarysummary(model_negbinom_01)
We also fit a negative binomial mode using glmer.nb() of {lme4} package but it may be slower and unstable compared to {glmmTMB} package.
Code
# Negative binomial mixed-effects modelmodel_negbinom_03 <-glmer.nb(count ~ mined + spp + cover+(1| site / spp), data = mf)
Warning in checkConv(attr(opt, "derivs"), opt$par, ctrl = control$checkConv, :
Model failed to converge with max|grad| = 0.0127471 (tol = 0.002, component 1)
Code
jtools::summ(model_negbinom_03)
Observations
644
Dependent variable
count
Type
Mixed effects generalized linear model
Family
Negative Binomial(1.666)
Link
log
AIC
1648.59
BIC
1702.20
Pseudo-R² (fixed effects)
0.48
Pseudo-R² (total)
0.69
Fixed Effects
Est.
S.E.
z val.
p
(Intercept)
-2.10
0.36
-5.87
0.00
minedno
2.44
0.36
6.72
0.00
sppPR
-1.34
0.39
-3.44
0.00
sppDM
0.42
0.33
1.29
0.20
sppEC-A
-0.61
0.35
-1.73
0.08
sppEC-L
0.55
0.33
1.68
0.09
sppDES-L
0.83
0.32
2.60
0.01
sppDF
0.35
0.33
1.06
0.29
cover
-0.07
0.18
-0.40
0.69
Random Effects
Group
Parameter
Std. Dev.
spp:site
(Intercept)
0.75
site
(Intercept)
0.51
Grouping Variables
Group
# groups
ICC
spp:site
161
0.10
site
23
0.04
Zero-inflated Mixed Effect Models
Zero-inflated models are used to account for excess zeros in count data, which can arise due to a separate process that generates zeros (e.g., structural zeros) in addition to the count process. In zero-inflated models, the data are assumed to come from two different processes: one that generates zeros and one that generates counts. The zero-inflated Poisson model is a mixture model that combines a Poisson distribution for the count data with a point mass at zero for the excess zeros.
Check for zero-inflation and overdispersion in the model
We can use the performance::check_zeroinflation() function to check for zero-inflation in the nested model (model_nested).
This tutorial has thoroughly introduced mixed-effects Poisson models, emphasizing their application in analyzing count data while accounting for both fixed and random effects. We begin by constructing a Mixed-Effects Poisson Model from scratch without relying on external libraries. Next, we fit various types of Poisson models using the {lme4}, {glmmTMB}, and {MASS} packages. The {lme4} package is utilized to fit random-effects Poisson models of varying complexity, including random intercept models, random intercept and slope models, and nested random-effects models. The {glmmTMB} package provides enhanced capabilities by fitting negative binomial models to address overdispersion, a common issue with Poisson data. Finally, the {MASS} package demonstrates how to fit quasi-Poisson and negative binomial models as alternatives for handling overdispersion, offering more flexible modeling approaches.
This tutorial explored mixed-effect Poisson modeling, from manual implementation to leveraging powerful R packages. For most practical applications, begin with {lme4} for basic mixed-effects Poisson models. For datasets with overdispersion or more complex structures, consider {glmmTMB} or {MASS} for extended modeling capabilities. By mastering these techniques, you can effectively analyze count data with hierarchical structures, making informed inferences and predictions in various fields such as biostatistics, epidemiology, and ecology.