This tutorial will explore how to perform regularized multinomial logistic regression in R. We will cover both the manual approach—building the model from scratch—and using the popular {glmnet} package. The {glmnet} package is widely used for fitting generalized linear models with elastic net regularization and offers efficient algorithms for solving penalized regression problems. By the end of this tutorial, you will thoroughly understand how to fit regularized multinomial logistic regression models in R, both by manually implementing the model and utilizing the efficient {glmnet} package for regularized model fitting. Mastering regularized multinomial logistic regression is an essential skill for any data scientist or statistician, whether you are working with high-dimensional data or aiming to improve the interpretability of your models.
Overview
Multinomial Logistic Regression (MLR) is an extension of binary logistic regression used when the dependent variable \(y\) is categorical with more than two levels (e.g., \(C\) classes, \(y \in \{1, 2, \dots, C\}\)). Regularization is added to the optimization process to prevent overfitting by penalizing large coefficients. To prevent overfitting, regularization is introduced by adding a penalty term to the likelihood function.
The common regularization techniques are:
Ridge Regularization (L2)
Adds a penalty proportional to the square of the coefficients:
Use metrics like accuracy, cross-entropy loss, or confusion matrix to evaluate performance.
Regularized Multinomial Logistic Regression from Scratch
Fitting a regularized multinomial logistic regression in R without using external packages can be achieved by manually implementing the necessary steps, as R does not natively provide multinomial logistic regression with regularization in base functions. Here’s a comprehensive guide to perform this task:
Synthetic Data Generation
We will generate a synthetic dataset with three classes and multiple predictors.
Code
# Set seed for reproducibilityset.seed(42)# 1. Generate synthetic datan <-300# Number of observationsp <-10# Number of predictorsk <-3# Number of classes# Generate predictorsX <-matrix(rnorm(n * p), n, p)# Generate coefficientsbeta <-matrix(rnorm(p * (k -1)), p, k -1)# Compute linear predictors and probabilitieseta <-cbind(0, X %*% beta) # Linear predictors for k-1 classesprob <-exp(eta) /rowSums(exp(eta)) # Convert to probabilitiesy <-apply(prob, 1, function(x) sample(1:k, 1, prob = x)) # Multinomial responsedata <-data.frame(y =as.factor(y), X)head(data)
Create a 5-fold cross-validation setup and define the hyperparameters for regularization.
Code
# 2. Cross-validation setupfolds <-sample(1:5, n, replace =TRUE) # 5-fold cross-validationalphas <-seq(0, 1, by =0.1) # Elastic net mixinglambdas <-10^seq(-4, 1, length =10) # Regularization strengths
Create Loss Functions and Optimization
Define the loss functions for Ridge, Lasso, and Elastic Net regularization. The loss functions compute the negative log-likelihood of the multinomial logistic regression model with the penalty term.
Code
# 3. Loss functions for regularized multinomial logistic regressionridge_loss <-function(beta_vec, X, y, lambda, k) { n <-nrow(X) p <-ncol(X) beta <-matrix(beta_vec, p, k -1)# Compute linear predictors and probabilities eta <-cbind(0, X %*% beta) prob <-exp(eta) /rowSums(exp(eta))# Multinomial negative log-likelihood log_lik <--sum(log(prob[cbind(1:n, as.numeric(y))]))# Ridge penalty ridge_penalty <- lambda *sum(beta^2)return(log_lik + ridge_penalty)}lasso_loss <-function(beta_vec, X, y, lambda, k) { n <-nrow(X) p <-ncol(X) beta <-matrix(beta_vec, p, k -1)# Compute linear predictors and probabilities eta <-cbind(0, X %*% beta) prob <-exp(eta) /rowSums(exp(eta))# Multinomial negative log-likelihood log_lik <--sum(log(prob[cbind(1:n, as.numeric(y))]))# Lasso penalty lasso_penalty <- lambda *sum(abs(beta))return(log_lik + lasso_penalty)}elastic_net_loss <-function(beta_vec, X, y, lambda, alpha, k) { n <-nrow(X) p <-ncol(X) beta <-matrix(beta_vec, p, k -1)# Compute linear predictors and probabilities eta <-cbind(0, X %*% beta) prob <-exp(eta) /rowSums(exp(eta))# Multinomial negative log-likelihood log_lik <--sum(log(prob[cbind(1:n, as.numeric(y))]))# Elastic net penalty ridge_penalty <- (1- alpha) * lambda *sum(beta^2) lasso_penalty <- alpha * lambda *sum(abs(beta))return(log_lik + ridge_penalty + lasso_penalty)}# Gradient descent optimization for Ridge, Lasso, and Elastic Netoptimize_model <-function(X, y, lambda, alpha =NULL, k, loss_function) { p <-ncol(X) beta_init <-rnorm(p * (k -1))# Pass alpha only for Elastic Netif (is.null(alpha)) { optim_res <-optim(beta_init, loss_function, X = X, y = y, lambda = lambda, k = k, method ="BFGS") } else { optim_res <-optim(beta_init, loss_function, X = X, y = y, lambda = lambda, alpha = alpha, k = k, method ="BFGS") }return(matrix(optim_res$par, p, k -1))}
Hyperparameter Selection via Cross-Validation
Perform hyperparameter selection via cross-validation to find the best model and hyperparameters.
In R, you can perform multinomial logistic regression using the {glmnet} package, which fits a generalized linear model via penalized maximum likelihood. {glmnet} supports ridge regression, lasso regression, and elastic net for various types of generalized linear models, including multinomial logistic regression.
The response variable y must be a factor for multinomial regression.
The family = "multinomial" argument ensures that the model performs multinomial logistic regression.
glmnet handles both Lasso (alpha = 1) and Ridge (alpha = 0) penalties, or you can use an Elastic Net combination by setting 0 < alpha < 1.
In this tutorial, we will demonstrate how to perform regularized multinomial logistic regression in R using the {glmnet} package. We will use the health_insurance data set, which contains information about individuals’ choice of health insurance products based on their
Install Required R Packages
To fit a Regularized Logistic Model R, we will use {glmnet} package. The {glmnet} package provides efficient functions for fitting generalized linear models (GLMs) with L1 (Lasso) and L2 (Ridge) regularization. The package is widely used for regression and classification tasks, especially when dealing with high-dimensional data or multicollinearity.
Following R packages are required to run this notebook. If any of these packages are not installed, you can install them using the code below:
Rows: 1448 Columns: 6
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): product, gender
dbl (4): age, household, position_level, absent
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
x for holding the predictor variables. This should be created using the function model.matrix() allowing to automatically transform any qualitative variables (if any) into dummy variables, which is important because glmnet() can only take numerical, quantitative inputs. After creating the model matrix, we remove the intercept component at index = 1.
Now we can apply cv.glmnet() function for cross-validation to choose the best lambda (regularization parameter). For example, suppose we designate \(α\)=0 for ridge regression and specify nlambda as 200. This implies that the model fit will be calculated solely for 200 \(λ\) values.
A special option for multinomial regression is type.multinomial, which allows the usage of a grouped lasso penalty (q=2 ) if type.multinomial = "grouped". The default is type.multinomial = "ungrouped" (q=1 ).
Printing the resulting object gives some basic information on the cross-validation performed:
Code
print(ridge.cv)
Call: cv.glmnet(x = x.train, y = y.train, type.measure = "deviance", nfolds = 5, alpha = 0, family = "multinomial", type.multinomial = "grouped", nlambda = 200)
Measure: Multinomial Deviance
Lambda Index Measure SE Nonzero
min 0.03771 200 1.139 0.01966 6
1se 0.04537 196 1.158 0.01826 6
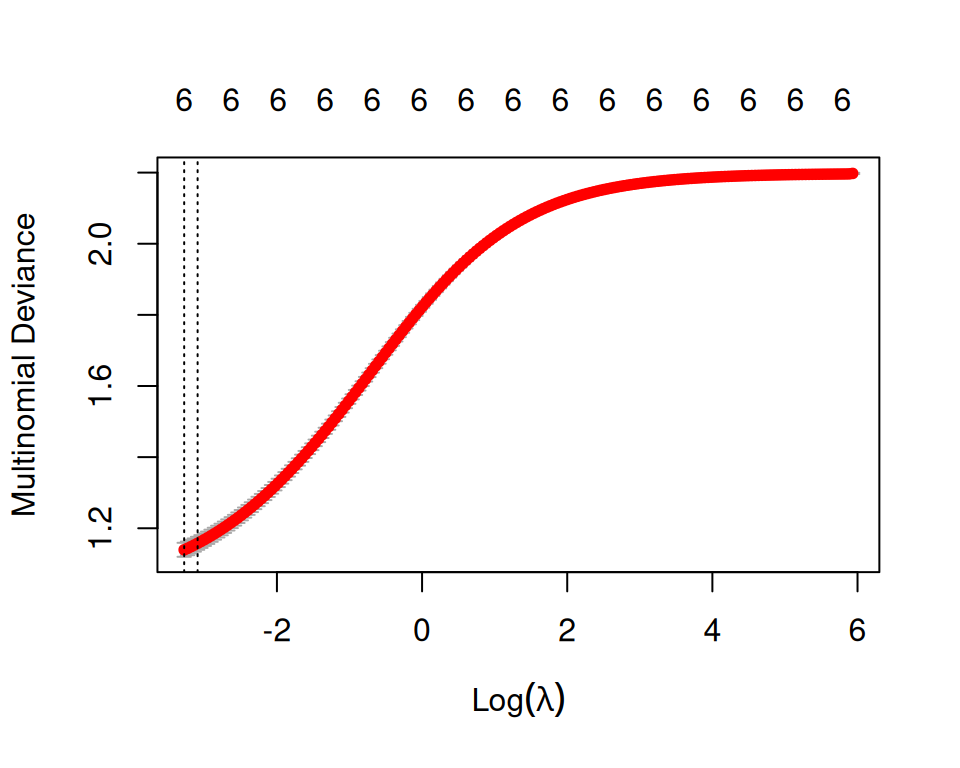
We can plot ridge.cv object to see how each tested lambda value performed:
Code
plot(ridge.cv)
The plot shows the cross-validation error based on the logarithm of lambda. The dashed vertical line on the left indicates that the optimal logarithm of lambda is around -2, which minimizes the prediction error. This lambda value will provide the most accurate model. The exact value of lambda can be viewed as follow:
Code
ridge.cv$lambda.min
[1] 0.03770618
Generally, the purpose of regularization is to balance accuracy and simplicity. This means, a model with the smallest number of predictors that also gives a good accuracy. To this end, the function cv.glmnet() finds also the value of lambda that gives the simplest model but also lies within one standard error of the optimal value of lambda. This value is called lambda.1se.
$A
6 x 1 sparse Matrix of class "dgCMatrix"
s0
2.648144980
age -0.087712433
household 0.118887896
position_level 0.125788485
genderMale 0.441857800
absent -0.002939366
$B
6 x 1 sparse Matrix of class "dgCMatrix"
s0
0.596075835
age 0.032590386
household -0.410129801
position_level -0.106127988
genderMale -1.027268491
absent -0.001981378
$C
6 x 1 sparse Matrix of class "dgCMatrix"
s0
-3.244220816
age 0.055122047
household 0.291241905
position_level -0.019660497
genderMale 0.585410691
absent 0.004920744
Prediction test data
Code
# Make predictions on the test datax.test <-model.matrix(product~., test)[,-1]# Outcome variabley.test <-train$product# Predictionridge.pred<-as.data.frame(test$product)ridge.pred$Class_Pred<-ridge.fit |>predict(newx = x.test, type="class") ridge.pred <- ridge.pred |> dplyr::select("test$product", "Class_Pred") |> dplyr::rename(Obs_Class ="test$product") |> dplyr::rename(Pred_Class ="Class_Pred") glimpse(ridge.pred)
Rows: 438
Columns: 2
$ Obs_Class <fct> A, A, A, A, A, A, A, A, A, A, A, A, A, A, A, A, A, A, A, A,…
$ Pred_Class <chr[,1]> "A", "B", "A", "B", "B", "A", "C", "A", "A", "A", "A", …
Finally we will extract the coefficients for the selected \(λ\) using coef() function:
Code
coef(lasso.fit)
$A
6 x 1 sparse Matrix of class "dgCMatrix"
s0
3.65183352
age -0.11527181
household 0.15408964
position_level 0.06947353
genderMale 0.42949078
absent .
$B
6 x 1 sparse Matrix of class "dgCMatrix"
s0
0.21983614
age 0.04498977
household -0.49079558
position_level -0.05717795
genderMale -1.00574848
absent .
$C
6 x 1 sparse Matrix of class "dgCMatrix"
s0
-3.87166967
age 0.07028204
household 0.33670594
position_level -0.01229558
genderMale 0.57625770
absent .
Prediction test data
Code
# Make predictions on the test datax.test <-model.matrix(product~., test)[,-1]# Outcome variabley.test <-train$product# Prediction# Predictionlasso.pred<-as.data.frame(test$product)lasso.pred$Class_Pred<-lasso.fit |>predict(newx = x.test, type="class") lasso.pred <- lasso.pred |> dplyr::select("test$product", "Class_Pred") |> dplyr::rename(Obs_Class ="test$product") |> dplyr::rename(Pred_Class ="Class_Pred") glimpse(lasso.pred)
Rows: 438
Columns: 2
$ Obs_Class <fct> A, A, A, A, A, A, A, A, A, A, A, A, A, A, A, A, A, A, A, A,…
$ Pred_Class <chr[,1]> "A", "B", "A", "A", "B", "A", "A", "A", "A", "A", "A", …
Predicted
Actual A B C
A 125 18 6
B 26 101 11
C 20 18 113
Elastic Net Regression
Cross Validation of the best Elastic Net regression
Code
#|message: false# Define hyperparameter gridalphas <-seq(0, 1, by =0.1) # Grid for alphalambda_seq <-10^seq(3, -3, length =100) # Grid for lambda# To store resultsresults <-data.frame(alpha =numeric(), lambda =numeric(), error =numeric())# Perform grid searchfor (a in alphas) {# Fit glmnet model for each alpha cv_fit <-cv.glmnet(x.train, y.train, family ="multinomial", alpha = a, lambda = lambda_seq, type.measure ="class")# Extract best lambda and error for the current alpha best_lambda <- cv_fit$lambda.min best_error <-min(cv_fit$cvm) # Minimum cross-validation error# Store results results <-rbind(results, data.frame(alpha = a, lambda = best_lambda, error = best_error))}# Find the best parametersbest_params <- results[which.min(results$error), ]print(best_params)
alpha lambda error
2 0.1 0.00231013 0.2247525
Fit the final model with optimal parameters
Code
# Refit the final model with optimal parametersenet.fit <-glmnet(x.train, y.train, family ="multinomial", alpha = best_params$alpha, lambda = best_params$lambda)# View coefficientsprint(coef(enet.fit))
$A
6 x 1 sparse Matrix of class "dgCMatrix"
s0
4.699700666
age -0.166665301
household 0.228786494
position_level 0.261680332
genderMale 0.614902899
absent -0.007895397
$B
6 x 1 sparse Matrix of class "dgCMatrix"
s0
0.28951435
age 0.06737238
household -0.69844870
position_level -0.15111152
genderMale -1.58434184
absent .
$C
6 x 1 sparse Matrix of class "dgCMatrix"
s0
-4.989215017
age 0.091022644
household 0.419403184
position_level -0.019721577
genderMale 0.741220510
absent 0.005142852
Prediction test data
Code
# Make predictions on the test datax.test <-model.matrix(product~., test)[,-1]# Outcome variabley.test <-train$product# Predictionenet.pred<-as.data.frame(test$product)enet.pred$Class_Pred<-enet.fit |>predict(newx = x.test, type="class") enet.pred <- enet.pred |> dplyr::select("test$product", "Class_Pred") |> dplyr::rename(Obs_Class ="test$product") |> dplyr::rename(Pred_Class ="Class_Pred") glimpse(enet.pred)
Rows: 438
Columns: 2
$ Obs_Class <fct> A, A, A, A, A, A, A, A, A, A, A, A, A, A, A, A, A, A, A, A,…
$ Pred_Class <chr[,1]> "A", "B", "A", "B", "B", "A", "C", "A", "A", "A", "A", …
Predicted
Actual A B C
A 119 20 10
B 25 102 11
C 19 20 112
Summary and Conclusion
In this tutorial, we explored regularized multinomial logistic regression in R, focusing on both the manual implementation and using the efficient {glmnet} package. We began by understanding the fundamentals of multinomial logistic regression, a model used for predicting categorical outcomes with more than two classes. Recognizing that overfitting can be a significant issue in high-dimensional or small datasets, we introduced regularization techniques, specifically Ridge (L2) and Lasso (L1) regression, which add penalty terms to the model to prevent overfitting and improve generalization. This process may entail parameter tuning through grid search, facilitated by the {caret} or {h2o} packages (please refer to the Machine Learning chapter).