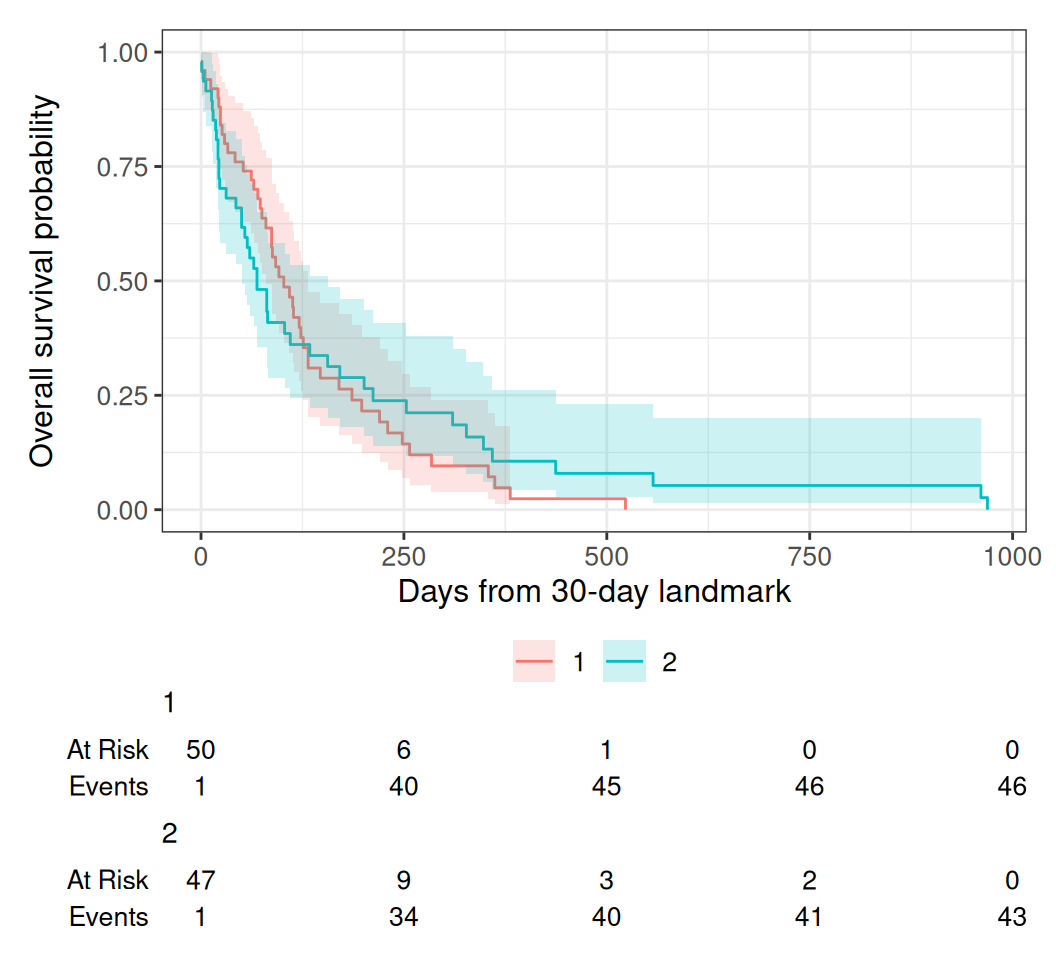
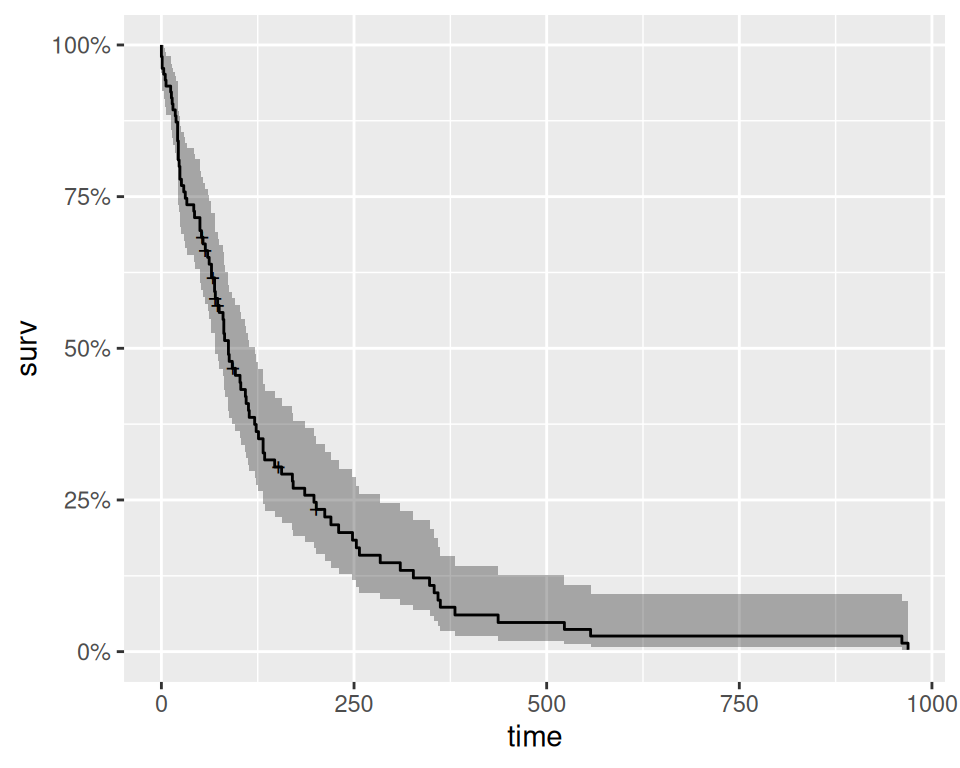
Rows: 97
Columns: 9
$ trt <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ celltype <fct> squamous, squamous, squamous, squamous, squamous, squamou…
$ time <dbl> 72, 411, 228, 126, 118, 82, 110, 314, 100, 42, 144, 30, 3…
$ status <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, …
$ karno <dbl> 60, 70, 60, 60, 70, 40, 80, 50, 70, 60, 30, 60, 60, 80, 4…
$ diagtime <dbl> 7, 5, 3, 9, 11, 10, 29, 18, 6, 4, 4, 3, 9, 4, 3, 5, 14, 2…
$ age <dbl> 69, 64, 38, 63, 65, 69, 68, 43, 70, 81, 63, 61, 42, 63, 5…
$ prior <dbl> 0, 10, 0, 10, 10, 10, 0, 0, 0, 0, 0, 0, 0, 10, 0, 0, 10, …
$ time_from_lm <dbl> 42, 381, 198, 96, 88, 52, 80, 284, 70, 12, 114, 0, 354, 2…