3.2. Multilevels or Mixed-Effects Multinomial Model
Multilevels or Mixed-Effect miltinomial model is an extension of the multinomial regression model that accounts for random effects. It’s particularly useful when data is structured hierarchically or has a multilevel nature, such as repeated measurements within individuals or groups. In this tutorial, we will demonstrate how to build and fit a multilevel multinomial model in R, focusing on the theoretical background, model implementation, and interpretation of results.
Overview
Multilevel multinomial models, also known as mixed-effects multinomial models, are used to analyze categorical outcomes with more than two categories while accounting for hierarchical structures in the data. These models extend the concept of mixed-effects models to multinomial outcomes, allowing for the estimation of both fixed and random effects. By incorporating random effects, these models can capture the variability within groups or clusters, providing more accurate estimates and predictions. In this tutorial, we will demonstrate how to build and fit a multilevel multinomial model in R, focusing on the theoretical background, model implementation, and interpretation of results.
A Mixed-Effects Multinomial Regression Model is an extension of the multinomial regression model that accounts for random effects. It’s particularly useful when data is structured hierarchically or has a multilevel nature, such as repeated measurements within individuals or groups.
Below, I explain the model, starting with multinomial regression, then incorporating mixed effects.
1. Multinomial Regression
Multinomial regression models the probabilities of \(K\) categorical outcomes (\(y\)) for a dependent variable, given predictors \(\mathbf{X}\). For \(K\)-category outcomes (\(y \in \{1, 2, \dots, K\}\)):
\[ P(y = k \mid \mathbf{X}) = \frac{\exp(\boldsymbol{\beta}_k^\top \mathbf{X})}{\sum_{j=1}^K \exp(\boldsymbol{\beta}_j^\top \mathbf{X})}, \quad k = 1, 2, \dots, K \]
\(\boldsymbol{\beta}_k\): Coefficients for the predictors for category \(k\).
One category (often the last one) is treated as the reference category, and its coefficients \(\boldsymbol{\beta}_K\) are set to 0 to avoid overparameterization.
The log-odds of being in category \(k\) relative to the reference category \(K\) is:
\[ \log \left( \frac{P(y = k \mid \mathbf{X})}{P(y = K \mid \mathbf{X})} \right) = \boldsymbol{\beta}_k^\top \mathbf{X} \]
2. Mixed-Effects Multinomial Regression
To incorporate random effects, the model adds random components to account for variability across clusters or groups (e.g., individuals, locations). The random effects modify the linear predictor.
For each cluster \(i\), we assume:
\[ P(y_i = k \mid \mathbf{X}_i, \mathbf{b}_i) = \frac{\exp((\boldsymbol{\beta}_k + \mathbf{b}_{i,k})^\top \mathbf{X}_i)}{\sum_{j=1}^K \exp((\boldsymbol{\beta}_j + \mathbf{b}_{i,j})^\top \mathbf{X}_i)}, \quad k = 1, 2, \dots, K \]
\(\mathbf{b}_{i,k}\): Random effects for group \(i\) and category \(k\).
\(\mathbf{b}_i = (\mathbf{b}_{i,1}, \dots, \mathbf{b}_{i,K})\) are typically assumed to follow a multivariate normal distribution:
\(\mathbf{b}_i \sim \mathcal{N}(\mathbf{0}, \mathbf{\Sigma})\), where \(\mathbf{\Sigma}\) is the covariance matrix of random effects.
The random effects allow the model to capture unobserved heterogeneity across groups.
Model Interpretation
Fixed Effects: Represent the population-level relationships between predictors and the outcome probabilities.
Random Effects: Capture deviations specific to each cluster or group.
The probabilities for each category are obtained by combining fixed and random effects in the linear predictor.
Log-Likelihood Function
The log-likelihood for the mixed-effects multinomial model, given data (\(\mathbf{y}, \mathbf{X}\)), is:
\(f(\mathbf{b}\_i \mid \mathbf{\Sigma})\): Density of the random effects.
This integral is generally intractable, so numerical methods such as Gaussian quadrature or Monte Carlo integration are used.
Suppose we want to model a patient’s choice among three treatments (\(A, B, C\)) repeatedly observed across multiple hospitals. Predictor variables include patient characteristics (\(\mathbf{X}_{ij}\)), and random effects account for variability in hospital-level preferences.
Fixed effects: (\(\boldsymbol{\beta}\)) capture how predictors like age or severity influence treatment choice.
Random effects: (\(\mathbf{b}_i\)) allow each hospital to have its own baseline tendencies for treatment preferences.
The model estimates how patient characteristics and hospital preferences jointly influence treatment choices, providing insights into the factors driving patient decisions.
Multilevel Multinomial Model from Scratch
Building a multilevel multinomial logistic regression model from scratch in R without using specialized packages is a complex task because it involves implementing maximum likelihood estimation, handling the integration over random effects, and ensuring numerical stability. Below is a step-by-step outline for such an implementation:
Generate Example Data
We’ll create synthetic data with both fixed and random effects for a multinomial outcome. The data will include a single predictor variable and group identifiers for the random effects. The design matrix will include an intercept term.
Code
# Simulate Example Dataset.seed(42)n <-100# Number of observationsn_groups <-5# Number of groupsX <-data.frame(X1 =rnorm(n)) # Single predictorgroup <-sample(1:n_groups, n, replace =TRUE) # Group identifiersy <-sample(1:3, n, replace =TRUE) # Multinomial outcome (3 categories)data <-data.frame(group = group, X1 = X$X1, y = y)# Design matrix including interceptX <-cbind(1, as.matrix(data[, "X1", drop =FALSE])) # Add intercept# Initial parameter vector (length should match model requirements)num_predictors <-ncol(X) # Including interceptnum_categories <-length(unique(data$y))init_params <-c(rep(0, num_predictors * (num_categories -1)), log(1))head(data)
Define the multinomial log-likelihood with random effects
The log-likelihood function calculates the negative log-likelihood of the model given the data, parameters, and random effects. It integrates over the random effects using Gaussian quadrature to estimate the log-likelihood for each group. The function also includes a regularization term to prevent large random effect variances.
Optimization and Fit the Model
Optimize the log-likelihood function to estimate the model parameters. We used Nelder-Mead optimization method was used. This methods is often more stable when dealing with noisy or numerically unstable functions. The optimization process is controlled by the maximum number of iterations and the level of output tracing.
Output Results
Other results such as the optimized parameters, final log-likelihood, and convergence status are extracted from the optimization output.
cat("\nEstimated Random Effect Variance (Sigma):\n")
Estimated Random Effect Variance (Sigma):
Code
print(sigma_hat)
[1] 2.661495e-16
Make Predictions Using the Fitted Model
Predict the class labels for each observation based on the estimated parameters. The predicted probabilities are calculated using the linear predictor and normalized to obtain class probabilities. The class with the highest probability is assigned as the predicted class label.
Multilevel Multinomial Model in R
In this section, we will focus on how to implement a mixed-effects multinomial regression model using the mblogit() function from the {mclogit} package in R. The mblogit() function allows you to fit multinomial models with random effects, making it suitable for analyzing categorical outcomes with hierarchical structures. We will demonstrate the step-by-step process of building and interpreting a mixed-effects multinomial model using the mblogit() function.
Install Required R Packages
Following R packages are required to run this notebook. If any of these packages are not installed, you can install them using the code below:
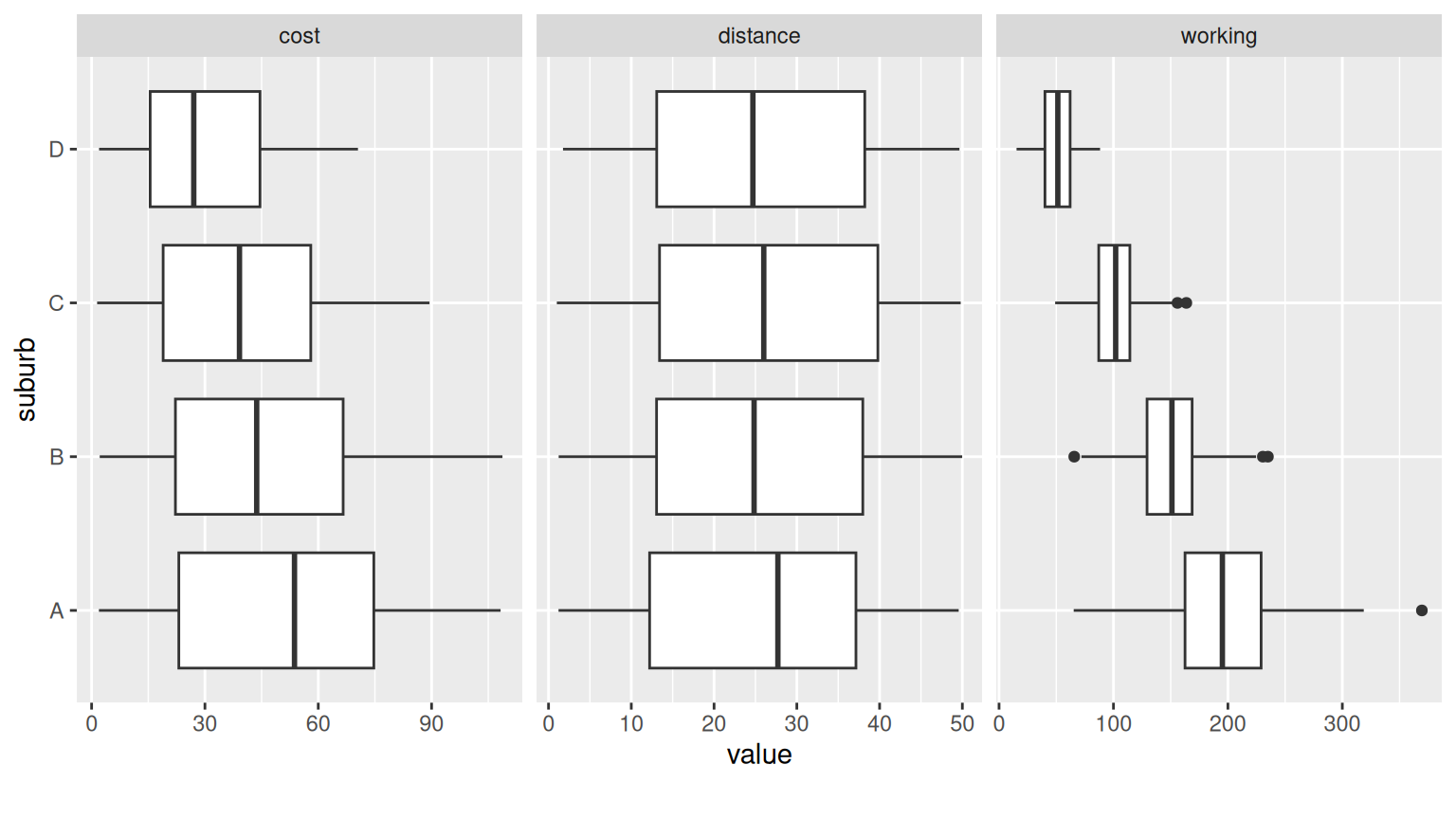
In this exercise we will use use a synthatic data similar to Transport data set of {mclogit} package. The dataset contains information about the mode of transportation chosen by individuals based on the cost, working population, and distance traveled. The goal is to predict the mode of transportation based on these predictors using a mixed-effects multinomial model.
transport: The chosen mode of transportation (Car, Bus, Train). cost: Cost of the transportation, influenced by distance and suburb class. working: Size of the working population in the suburb. distance: Distance traveled, uniformly distributed between 1 km and 50 km. suburb: Categorical variable indicating the suburb class (A, B, C, D).
Code
# Load required packageset.seed(123) # For reproducibility# Define constantsn_samples <-1000suburb_classes <-c("A", "B", "C", "D")transport_modes <-c("Car", "Bus", "Train")n_suburbs <-length(suburb_classes)# Generate suburb datasuburbs <-sample(suburb_classes, size = n_samples, replace =TRUE, prob =c(0.2, 0.3, 0.3, 0.2))# Generate working population size by suburb classworking_population_by_class <-list(A =c(mean =200, sd =50),B =c(mean =150, sd =30),C =c(mean =100, sd =20),D =c(mean =50, sd =15))working_population <-sapply(suburbs, function(suburb) {rnorm(1, mean = working_population_by_class[[suburb]]["mean"],sd = working_population_by_class[[suburb]]["sd"])})# Generate distance traveled (longer distances in suburban/rural areas)distance <-runif(n_samples, min =1, max =50) # Between 1 km and 50 km# Generate cost (correlated with distance and suburb class)cost_base_by_class <-c(A =2.0, B =1.8, C =1.5, D =1.2)cost <-mapply(function(suburb, dist) { dist *rnorm(1, mean = cost_base_by_class[suburb], sd =0.2)}, suburb = suburbs, dist = distance)# Simulate multinomial choice for transport modes# Use a softmax-like function for transport probabilitiessoftmax <-function(x) { exp_x <-exp(x -max(x)) exp_x /sum(exp_x)}# Assign base utilities for transport modes by suburbbase_utilities <-list(Car =c(A =2.5, B =2.0, C =1.5, D =1.0),Bus =c(A =1.5, B =1.8, C =2.0, D =2.5),Train =c(A =2.0, B =1.5, C =1.2, D =1.0))# Calculate probabilities and assign transporttransport_choices <-sapply(1:n_samples, function(i) { utilities <-sapply(transport_modes, function(mode) { base_utilities[[mode]][suburbs[i]] -0.05* cost[i] +0.02* distance[i] }) probabilities <-softmax(utilities)sample(transport_modes, size =1, prob = probabilities)})# Create the final datasetmf <-data.frame(transport = transport_choices,cost = cost,working = working_population,distance = distance,suburb = suburbs)# convert to factormf$transport <-as.factor(mf$transport)mf$suburb <-as.factor(mf$suburb)# Preview the datasetglimpse(mf)
Rows: 1,000
Columns: 5
$ transport <fct> Bus, Bus, Bus, Train, Car, Bus, Bus, Bus, Train, Bus, Car, C…
$ cost <dbl> 18.819656, 58.857251, 27.258692, 71.097966, 20.331215, 55.84…
$ working <dbl> 131.94321, 35.09452, 120.53570, 237.55307, 124.54167, 147.14…
$ distance <dbl> 11.085519, 47.184413, 19.586866, 31.685767, 9.991618, 33.301…
$ suburb <fct> B, D, C, A, A, B, C, A, C, C, A, C, D, C, B, A, B, B, C, A, …
We will fit a mixed-effects multinomial model to the Transport dataset using the mblogit() function from the {mclogit} package. The model will predict the choice of transportation based on the cost, walking distance, and working population of each suburb. We will include random effects for the suburb variable to account for the hierarchical structure of the data.
Random Intercept Model
In a first step, we generate a baseline model with random intercept only. This model assumes that the effect of the predictors is the same across all levels of the random effect.
Code
# Fit random intercept multinomial modelmodel_inter <-mblogit(formula = transport ~1, random =~1| suburb, data = mf)
Call:
mblogit(formula = transport ~ 1, data = mf, random = ~1 | suburb)
Equation for Car vs Bus:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.1552 0.3993 -0.389 0.697
Equation for Train vs Bus:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.7218 0.3415 -2.114 0.0345 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Co-)Variances:
Grouping level: suburb
Estimate Std.Err.
Car~1 0.6133 0.3349
Train~1 0.4989 0.4334 0.2799 0.2339
Approximate residual deviance: 2019
Number of Fisher scoring iterations: 4
Number of observations
Groups by suburb: 4
Individual observations: 1000
Mixed-Effects Multinomial Model
We will fit a mixed-effects multinomial model with random intercept allowing the effect of the predictors to vary across levels of the random effect.
Code
summary(model_mixed)
Call:
mblogit(formula = transport ~ cost + working + distance, data = mf,
random = ~1 | suburb)
Equation for Car vs Bus:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.314057 0.487163 -0.645 0.519
cost -0.002346 0.010427 -0.225 0.822
working 0.001417 0.002365 0.599 0.549
distance 0.003019 0.017704 0.171 0.865
Equation for Train vs Bus:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.152709 0.421166 -2.737 0.0062 **
cost 0.005934 0.011392 0.521 0.6024
working 0.002561 0.002344 1.092 0.2747
distance -0.005541 0.019596 -0.283 0.7774
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Co-)Variances:
Grouping level: suburb
Estimate Std.Err.
Car~1 0.5117 0.13468
Train~1 0.3213 0.2239 0.08724 0.05652
Approximate residual deviance: 2018
Number of Fisher scoring iterations: 4
Number of observations
Groups by suburb: 4
Individual observations: 1000
Model Comparison
We can compare the two models using the anova() function to see if the mixed-effects model provides a better fit to the data than the random intercept model.
Code
anova(model_inter, model_mixed)
Analysis of Deviance Table
Model 1: transport ~ 1
Model 2: transport ~ cost + working + distance
Resid. Df Resid. Dev Df Deviance
1 1995 2019.5
2 1989 2017.5 6 1.9592
As the second model is significantly better, we are justified to believe that our fixed effects have explanatory power. We can now use the getSummary.mmblogit() function to get a summary of the model with the fixed effects.
Code
getSummary.mmblogit(model_mixed)
$coef
, , Car/Bus
est se stat p lwr
(Intercept) -0.314056911 0.487163046 -0.6446649 0.5191444 -1.268878937
cost -0.002345802 0.010426949 -0.2249749 0.8219988 -0.022782247
working 0.001416738 0.002365095 0.5990195 0.5491599 -0.003218763
distance 0.003018856 0.017703536 0.1705228 0.8645990 -0.031679437
upr
(Intercept) 0.640765114
cost 0.018090643
working 0.006052239
distance 0.037717149
, , Train/Bus
est se stat p lwr
(Intercept) -1.152708724 0.421165825 -2.7369474 0.00620122 -1.978178572
cost 0.005933943 0.011391700 0.5209006 0.60243601 -0.016393379
working 0.002560673 0.002344172 1.0923572 0.27467615 -0.002033819
distance -0.005541115 0.019596485 -0.2827607 0.77736030 -0.043949521
upr
(Intercept) -0.327238876
cost 0.028261266
working 0.007155164
distance 0.032867290
$suburb
, , 1
est se stat p lwr upr
Car/Bus: VCov(~1,~1) 0.5117241 0.13467786 NA NA NA NA
Train/Bus: VCov(~1,~1) 0.3212967 0.08724274 NA NA NA NA
, , 2
est se stat p lwr upr
Car/Bus: VCov(~1,~1) 0.3212967 0.08724274 NA NA NA NA
Train/Bus: VCov(~1,~1) 0.2238657 0.05651621 NA NA NA NA
$Groups
Groups by suburb
4
$sumstat
LR df deviance McFadden Cox.Snell Nagelkerke
1.797156e+02 1.100000e+01 2.017509e+03 8.179211e-02 1.644922e-01 1.850538e-01
AIC BIC N
2.039509e+03 2.093494e+03 1.000000e+03
$call
mblogit(formula = transport ~ cost + working + distance, data = mf,
random = ~1 | suburb)
$contrasts
NULL
$xlevels
named list()
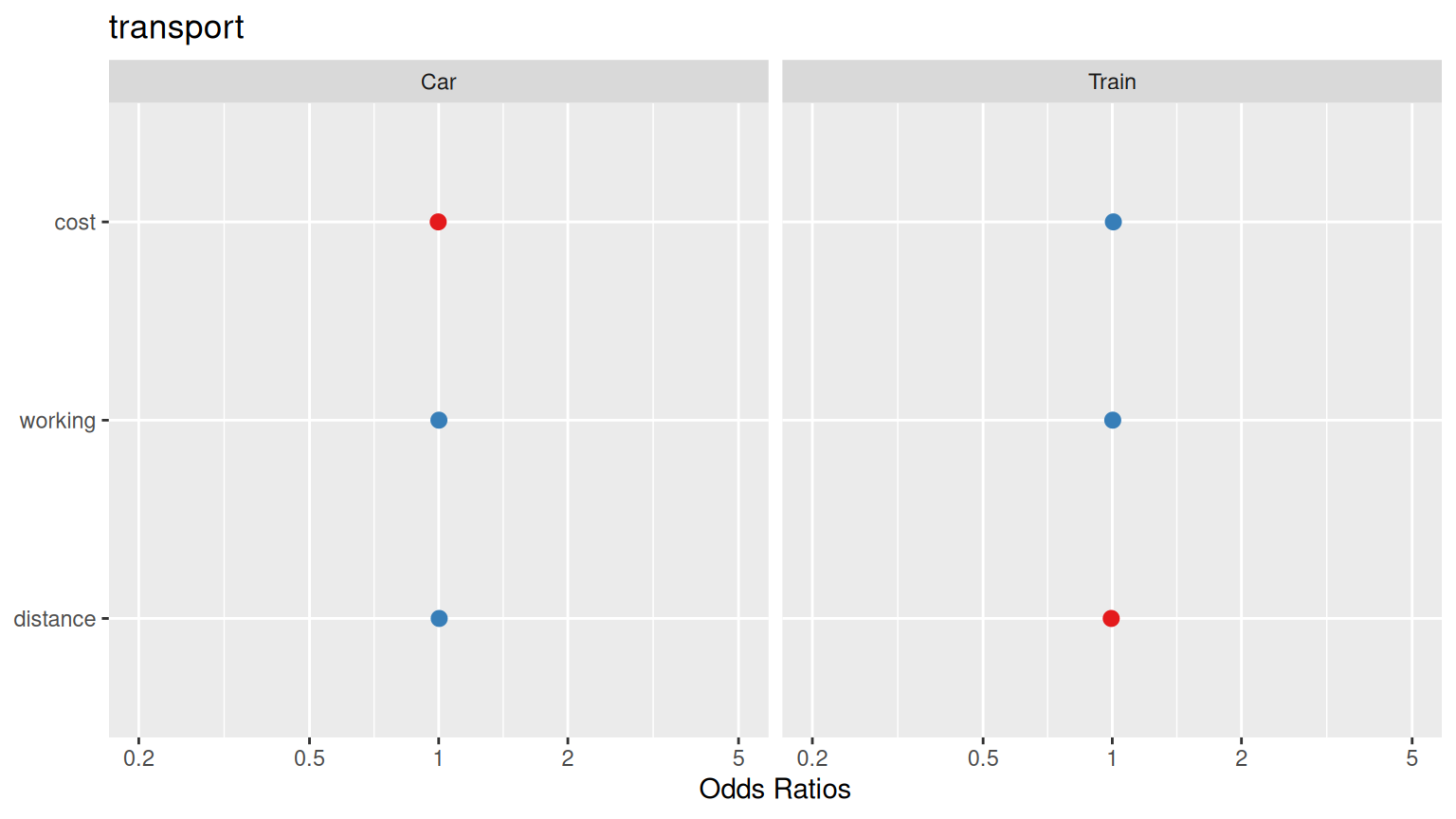
We can also use the tab_model() function from the {sjPlot} package to generate a table of the model coefficients and their significance levels. Each row in the table represents a predictor variable, and the columns display Odds Ratios, CI, and p-values.
Code
sjPlot::tab_model(model_mixed)
transport: Car
transport: Train
Predictors
Odds Ratios
CI
p
Odds Ratios
CI
p
(Intercept)
0.73
0.28 – 1.90
0.519
0.32
0.14 – 0.72
0.006
cost
1.00
0.98 – 1.02
0.822
1.01
0.98 – 1.03
0.602
working
1.00
1.00 – 1.01
0.549
1.00
1.00 – 1.01
0.275
distance
1.00
0.97 – 1.04
0.865
0.99
0.96 – 1.03
0.777
N suburb
4
Observations
1000
Plot the marginal effects of the predictors on the outcome variable using the plot_model() function from the {sjPlot} package. This function generates a plot showing the marginal effects of each predictor variable on the outcome variable, along with confidence intervals.
We can evaluate the performance of the mixed-effects multinomial model using the performance() function from the {performance} package. This function provides various performance metrics such as the AIC, BIC, and log-likelihood of the model.
Code
performance::performance(model_mixed)
# Indices of model performance
AIC | BIC | Nagelkerke's R2 | RMSE | Sigma
-----------------------------------------------------
2039.509 | 2093.494 | 0.185 | 0.447 | 1.426
Prediction Performance
We can also evaluate the prediction performance of the model using the predict() function. This function generates predicted probabilities for each category of the outcome variable based on the model’s fixed and random effects.
Code
# Predict probabilities for each categorypred_probs <-predict(model_mixed, type ="response")# # Convert probabilities to classpred_classes <-apply(pred_probs, 1, which.max)head(pred_classes)
[1] 2 1 1 2 2 2
Code
# Training set evaluationactual_classes <-as.numeric(mf$transport) # Convert to numeric if neededconf_matrix <-table(Predicted = pred_classes, Actual = actual_classes)conf_matrix
# Calculate in-class accuracyin_class_accuracy <-diag(conf_matrix) /colSums(conf_matrix)# Display in-class accuracy for each classcat("In-Class Accuracy for each class:\n")
In-Class Accuracy for each class:
Code
print(round(in_class_accuracy*100, 2))
1 2 3
65.98 60.93 144.22
Summary and Conclusion
This tutorial demonstrated how to build and fit a multilevel multinomial model in R using the mblogit() function from the {mclogit} package. We started by generating synthetic data with hierarchical structures and categorical outcomes. We then fitted a mixed-effects multinomial model to predict the mode of transportation based on the cost, working population, and distance traveled. The model included random effects for the suburb variable to account for the hierarchical structure of the data. We compared the model with random intercept and slope to a model with random intercept only and found that the mixed-effects model provided a better fit to the data. We evaluated the model’s performance using various metrics and generated predictions for the outcome variable. Overall, the tutorial provided a comprehensive overview of building and interpreting multilevel multinomial models in R, highlighting the importance of accounting for hierarchical structures in categorical data analysis.